Did you mean this command?:🙂
Working like this :
squeezelite -n XioPlayX -o - -a 32 -z (n=name, -o - =stdout, -a32=buf -z=daemonize)
camilladsp -v /home/pi/Cfilters/rate_44100.yml
But no sound, and squeezelite is consuming like 100% CPU...
also squeezelite acting very unstable like this... not camilladsp's fault 😉
I created an issue on the squeezelite git for this a couble of hours ago allready.
Let's see if there will be any correction on that?
Jesper.
Code:
squeezelite -n XioPlayX -o - -a 32 -z | camilladsp -v /home/pi/Cfilters/rate_44100.ymlDid you mean this command?:
Code:squeezelite -n XioPlayX -o - -a 32 -z | camilladsp -v /home/pi/Cfilters/rate_44100.yml
This for starting squeezelite and send stream to stdout:
squeezelite -n XioPlayX -o - -a 32 -z
squeezelite name=XioPlay output (-o -)=stdout
And this for starting camilladsp:
camilladsp -v /home/pi/Cfilters/rate_44100.yml
With this config...
capture:
type: File
channels: 2
filename: "/dev/stdin"
format: S32LE
playback:
type: Alsa
channels: 2
device: "sound_out"
format: S32LE
Jesper.
Is the /home/pi/rawfile.dat named pipe (fifo)?
No, it was not, i never tried creating an FIFO pipe before, i guess it's the problem squeezelite having running crazy and uses too much cpu, as i was writing to a "normal" file 😱
Jesper.
I just updated the "develop" branch to version 0.0.12.
New features:
New features:
- New filter type "BiquadCombo" for making Butterworth and LR high/lowpass filters (no more tables!)
- Option to use FFTW instead of RustFFT. FFTW runs about a factor 2 faster, but increases the complexity a lot. Use only if you have problems with high cpu usage!
- More options for Dither filters
- Added first order allpass, first order low/high shelf Biquads
- New filter type DiffEq for making filters with arbitrary poles/zeros. Give a0..aN and b0..bN, for H(z) = (b0 + b1z^-1 + .. + bnz^-n)/(a0 + a1z^-1 + .. + anz^-n)
- Improved readme
- Minor fixes
Alright. If you use stdin/stdout you need to start them together with the pipe operator "|" in between. Otherwise they don't get connected. Whe you type "some_command | another_command", the system connects stdout of the first one to stdin of the second one.This for starting squeezelite and send stream to stdout:
squeezelite -n XioPlayX -o - -a 32 -z
squeezelite name=XioPlay output (-o -)=stdout
And this for starting camilladsp:
camilladsp -v /home/pi/Cfilters/rate_44100.yml
With this config...
Jesper.
Alright. If you use stdin/stdout you need to start them together with the pipe operator "|" in between. Otherwise they don't get connected. Whe you type "some_command | another_command", the system connects stdout of the first one to stdin of the second one.
A little delayed i know, but it's working allright... I havent tried to mkfifo named pipe's but i guess it will work nearly with same performance.
When piping using "|" between output / input, i have an 40sec. delay before music starts, but didn't try anything to fix that now.
The camilladsp & squeezelite are using very little cpu when using stdio pipes (when using them the correct way Jesper... sighhh!@%?) 😱
Jesper.
The snd-aloop issue will take a bit to fix Functionality of pcm_notify in snd-aloop?
Yes... but when it's done i need to try again... good catch phofman !
Jesper.
It's simple, I have just reported. The real work will be done by the devels.
But I like the way the process works. Try to report a bug in windows .... if there was a loopback device in the first place :-(
But I like the way the process works. Try to report a bug in windows .... if there was a loopback device in the first place :-(
Henrik... 🙂
Is this still the right way of building ?
Anyway i actually found a way making switching filters "on the fly".
It's working as proto pretty well, for now on RPI4 with Raspbian OS 😉
Right now i am listning to different sample rates (44100 & 96000) with the simple highpass+-gain filter i created.
I had to hack the squeezelite code for making it possible and set the right switch on it when executed.
What is does is as follows.
LogitechMediaServer (LMS) send stream to squeezelite, which is started with this syntax:
sudo /home/pi/DSP_Engine/squeezelite/squeezelite -n SuperPlayer -o squeeze -r 44100-192000:3000 -z
This stream is then captured by camilladsp from the alsa ~alias 'squeeze'(Card1,device0 on my setup)... Camilla send the stream after filter are invoked to the real hardware (alsa ~alias 'sound_out')
Then if sample_rate is changed in squeezelite, it sends a through system call (snip from squeezelite C sourcecode :
The python script connect to camilladsp and change the filter to e.g. 96000, the switch '-r' i use for executing squeezelite makes a delay when sample_rate change before music is started again, so there are no hickups when sample_rate are changing.
I can provide some more information if anyone like?, but it's only some uglyhack setup, but hey it's working very good indeed!
Jesper.
Is this still the right way of building ?
git clone GitHub - HEnquist/camilladsp: A flexible linux IIR and FIR engine for crossovers, room correction etc.
git checkout develop
git pull
Build with ::
cargo build --release --no-default-features --features alsa-backend --features 32bit --features FFTW
Anyway i actually found a way making switching filters "on the fly".
It's working as proto pretty well, for now on RPI4 with Raspbian OS 😉
Right now i am listning to different sample rates (44100 & 96000) with the simple highpass+-gain filter i created.
I had to hack the squeezelite code for making it possible and set the right switch on it when executed.
What is does is as follows.
LogitechMediaServer (LMS) send stream to squeezelite, which is started with this syntax:
sudo /home/pi/DSP_Engine/squeezelite/squeezelite -n SuperPlayer -o squeeze -r 44100-192000:3000 -z
This stream is then captured by camilladsp from the alsa ~alias 'squeeze'(Card1,device0 on my setup)... Camilla send the stream after filter are invoked to the real hardware (alsa ~alias 'sound_out')
Then if sample_rate is changed in squeezelite, it sends a through system call (snip from squeezelite C sourcecode :
LOG_INFO("Player detected sample rate change ! %u", sample_rate);
if(sample_rate == 44100) system("/usr/bin/python3 /home/pi/DSP_Engine/filters/exec_44100.py");
if(sample_rate == 96000) system("/usr/bin/python3 /home/pi/DSP_Engine/filters/exec_96000.py");
LOG_INFO("Sample rate filter changed ! %u", sample_rate);
The python script connect to camilladsp and change the filter to e.g. 96000, the switch '-r' i use for executing squeezelite makes a delay when sample_rate change before music is started again, so there are no hickups when sample_rate are changing.
I can provide some more information if anyone like?, but it's only some uglyhack setup, but hey it's working very good indeed!
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1167 root 20 0 16960 13924 6788 S 2.3 0.3 1:13.57 squeezelite
1154 pi 20 0 32036 6788 5752 S 2.0 0.2 1:17.94 camilladsp
Jesper.
I did some benchmarking of CamillaDSP as a convolver and compared it vs. Brutefir. Very first the results in words:
- Camilladsp precision is equal with Brutefir and as mathematically adequate as possible.
- Camilladsp requires a bit more CPU ressources than Brutefr (due to inbuilt supervisor mechanisms).
- Camilladsp, unlike Brutefir, preserves datastream integrity till the very end, even along with linear phase filters (Brutefir stops convolution as soon as the incoming data stream ends. Because of the time delay introduced by the linear phase filters this will truncate the data stream at it's end).
Camilladsp (and Brutefir) were tested within an audiopipe. Input was a multitone signal of 16/24/32/64 Bit depth. This input was normalized by sox to FLOAT64. The convolution was performed using a set of FLOAT64 mixed linear-phase and minimum-phase filters, summing up to a delay of 128k. Filters were arranged to an input shelving filter, then a 4-/5-way xover, then summing and a final inverse shelving filter. Summing up to a (cpu-intense, but useless) 1:1 in-out-setup. The output was sampled as FLOAT64.
Filters were generated by Acourate, and so the analysis of the resulting output files.
1. Filters setup:
A_Filters+20-285.png
2. 16Bit input file - Comparing input file (red), sox conversion (green, -10dB), brutefir convolution result (brown, -20dB) and camilladsp convoltution result (blue, -30dB)
A_16_Orig-Sox-Bfir-Cam.png
3. 24Bit input file - Comparing input file (red), sox conversion (green, -10dB), brutefir convolution result (brown, -20dB) and camilladsp convoltution result (blue, -30dB)
A_24_Orig-Sox-Bfir-Cam.png
4. 32Bit input file - Comparing input file (red), sox conversion (green, -10dB), brutefir convolution result (brown, -20dB) and camilladsp convoltution result (blue, -30dB)
A_32_Orig-Sox-Bfir-Cam.png
5. Behavior of Camilladsp vs. Brutefir in case of the linear phase filters used in this setup (2*128k, equalling to a delay of 120k). Brutefir will truncate the 128k samples initial delay at the end. Camilladap does not.
16-Time.png
Because of this latter improvement over brutefir , my vote goes to Camilladsp, despite of the higher CPU usage. Because I am using linear phase filters within my active loudspeakers projects.
- Camilladsp precision is equal with Brutefir and as mathematically adequate as possible.
- Camilladsp requires a bit more CPU ressources than Brutefr (due to inbuilt supervisor mechanisms).
- Camilladsp, unlike Brutefir, preserves datastream integrity till the very end, even along with linear phase filters (Brutefir stops convolution as soon as the incoming data stream ends. Because of the time delay introduced by the linear phase filters this will truncate the data stream at it's end).
Camilladsp (and Brutefir) were tested within an audiopipe. Input was a multitone signal of 16/24/32/64 Bit depth. This input was normalized by sox to FLOAT64. The convolution was performed using a set of FLOAT64 mixed linear-phase and minimum-phase filters, summing up to a delay of 128k. Filters were arranged to an input shelving filter, then a 4-/5-way xover, then summing and a final inverse shelving filter. Summing up to a (cpu-intense, but useless) 1:1 in-out-setup. The output was sampled as FLOAT64.
Filters were generated by Acourate, and so the analysis of the resulting output files.
1. Filters setup:
A_Filters+20-285.png
2. 16Bit input file - Comparing input file (red), sox conversion (green, -10dB), brutefir convolution result (brown, -20dB) and camilladsp convoltution result (blue, -30dB)
A_16_Orig-Sox-Bfir-Cam.png
3. 24Bit input file - Comparing input file (red), sox conversion (green, -10dB), brutefir convolution result (brown, -20dB) and camilladsp convoltution result (blue, -30dB)
A_24_Orig-Sox-Bfir-Cam.png
4. 32Bit input file - Comparing input file (red), sox conversion (green, -10dB), brutefir convolution result (brown, -20dB) and camilladsp convoltution result (blue, -30dB)
A_32_Orig-Sox-Bfir-Cam.png
5. Behavior of Camilladsp vs. Brutefir in case of the linear phase filters used in this setup (2*128k, equalling to a delay of 120k). Brutefir will truncate the 128k samples initial delay at the end. Camilladap does not.
16-Time.png
Because of this latter improvement over brutefir , my vote goes to Camilladsp, despite of the higher CPU usage. Because I am using linear phase filters within my active loudspeakers projects.
Attachments


Just a note - sox uses signed int32 internally, therefore any work with larger formats (e.g. float64) reduces precision.
sox/sox.h at master * jacksonh/sox * GitHub
sox/sox.h at master * jacksonh/sox * GitHub
sox/sox.h at master * jacksonh/sox * GitHub
sox/sox.h at master * jacksonh/sox * GitHub
Just a note - sox uses signed int32 internally, therefore any work with larger formats (e.g. float64) reduces precision ...
OK. This is it! These are the corresponding graphs with an input from a file formatted as FLOAT64. Note that the multitone does not reach 64Bit precision. But such as it is, sox does set the resolution level at -210dB (sox graph is attenuated by -10dB), which is slightly worse than the input signal.
64-64-bit.png
Does anybody know a bitdepth converter which will gracefully handle conversions to FLOAT64 and back?
Attachments
Yes that looks correct! I take it you're not using the websocket server?Is this still the right way of building ?
This is brilliant! I had a feeling you would get it working eventually 🙂Anyway i actually found a way making switching filters "on the fly".
It's working as proto pretty well, for now on RPI4 with Raspbian OS 😉
Right now i am listning to different sample rates (44100 & 96000) with the simple highpass+-gain filter i created.
I had to hack the squeezelite code for making it possible and set the right switch on it when executed.
What is does is as follows.
LogitechMediaServer (LMS) send stream to squeezelite, which is started with this syntax:
sudo /home/pi/DSP_Engine/squeezelite/squeezelite -n SuperPlayer -o squeeze -r 44100-192000:3000 -z
This stream is then captured by camilladsp from the alsa ~alias 'squeeze'(Card1,device0 on my setup)... Camilla send the stream after filter are invoked to the real hardware (alsa ~alias 'sound_out')
Then if sample_rate is changed in squeezelite, it sends a through system call (snip from squeezelite C sourcecode :
The python script connect to camilladsp and change the filter to e.g. 96000, the switch '-r' i use for executing squeezelite makes a delay when sample_rate change before music is started again, so there are no hickups when sample_rate are changing.
I can provide some more information if anyone like?, but it's only some uglyhack setup, but hey it's working very good indeed!
Jesper.
Having squeezelite somehow signal when it wants a new samplerate makes perfect sense. Perhaps your solution could be made a bit more generic, so you specify the command to run as a config parameter or something?
There is actually an open pull request on squeezelite that has some similarities, for controlling an external amplifier: Support control of an external amplifier. by mjagdis * Pull Request #81 * ralph-irving/squeezelite * GitHub
If you could make a nice generic solution and send it as a pull request, there should be a good chance to get it accepted. Are you familiar with the process of making pull requests? If not, just ask and I'll try to help you.
Thanks for testing this so carefully, and for the very detailed writeup! Nice to see I haven't made any silly mistakes that destroys the numerical precision 🙂I did some benchmarking of CamillaDSP as a convolver and compared it vs. Brutefir. Very first the results in words:
.....
Actually, you can use CamillaDSP for that 🙂Does anybody know a bitdepth converter which will gracefully handle conversions to FLOAT64 and back?
Just compile it with the default features (meaning without 32bit mode) and run it with file in/out with the formats you want, and an empty pipeline. You could also add some dither if you like.
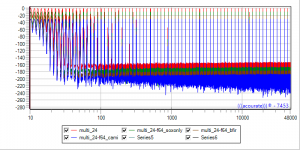
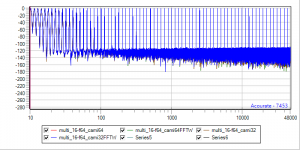
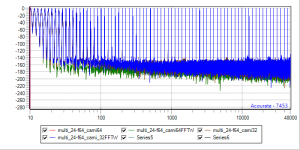
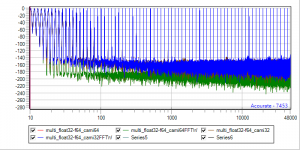
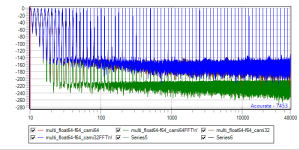
Yet another set of benchmarks. Camilladsp comes in different flavors, 64Bit, 32Bit, RustFFT, FFTW ... So there is a nice playround to compare 64Bit, 64BitFFTW, 32Bit, 32BitFFTW
16BitIn -> sox -> Float64 -> Camilladsp (all 4 datasets the same, blue-4 hiding brown-3 hiding green-2 hiding red-1)
16-64.png
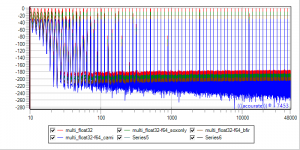
24BitIn -> sox -> Float64 -> Camilladsp (gn-2 hiding red-1, blue-4 hiding brown-3)
24-64.png
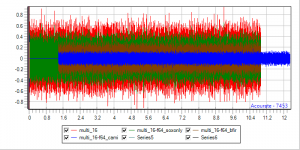
32BitIn -> sox -> Float64 -> Camilladsp (gn-2 hiding red-1, blue-4 hiding brown-3)
32-64.png
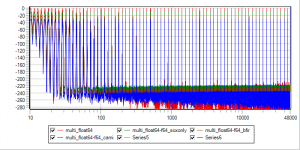
64BitIn -> sox -> Float64 -> Camilladsp (gn-2 hiding red-1, blue-4 hiding brown-3)
64-64.png
And Brutefir 32Bit as a reference, formatted differently with all 16/24/32/64 inputs on the same graph
1664-64_Bfir32.png
No surprizes (still with sox as a bitdepth shifter - was done before phofman made his objection about the problematic float64 conversion by sox).
Oh my ... this calls for another set of benchmarks ...
16BitIn -> sox -> Float64 -> Camilladsp (all 4 datasets the same, blue-4 hiding brown-3 hiding green-2 hiding red-1)
16-64.png
24BitIn -> sox -> Float64 -> Camilladsp (gn-2 hiding red-1, blue-4 hiding brown-3)
24-64.png
32BitIn -> sox -> Float64 -> Camilladsp (gn-2 hiding red-1, blue-4 hiding brown-3)
32-64.png
64BitIn -> sox -> Float64 -> Camilladsp (gn-2 hiding red-1, blue-4 hiding brown-3)
64-64.png
And Brutefir 32Bit as a reference, formatted differently with all 16/24/32/64 inputs on the same graph
1664-64_Bfir32.png
No surprizes (still with sox as a bitdepth shifter - was done before phofman made his objection about the problematic float64 conversion by sox).
Actually, you can use CamillaDSP for that 🙂
Just compile it with the default features (meaning without 32bit mode) and run it with file in/out with the formats you want, and an empty pipeline. You could also add some dither if you like.
Oh my ... this calls for another set of benchmarks ...
Attachments
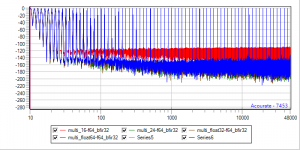
Last edited:
This is very exciting news ... because it's really working !!! Three piped instances of camilladsp's within a same testbed:Actually, you can use CamillaDSP for that 🙂
Just compile it with the default features (meaning without 32bit mode) and run it with file in/out with the formats you want, and an empty pipeline. You could also add some dither if you like.
The first instance to read in an audio.wav (S16LE) and transforming the bitdepth and format of the datastream to F64, could also perform -1dB .. -2dB to prevent intersample clipping in the following stages
(Then a samplerate conversion 44.1k->96k)
The second instance to perform the convolution, in this example 10x 128k Filters in full F64
The third instance to transform from F64 to S32, along with some dithering.
(Then aplay or playhrt)
and this looks like
camilladsp /home/privat/_camilladsp/BitXform/S16-F64.yml | \
resample_soxr ... --inrate=44100 --outrate=9600 | \
camilladsp /home/privat/_camilladsp/4way/4way.yml | \
camilladsp /home/privat/_camilladsp/BitXform/F64-S32.yml | \
aplay -c 2 -D hw:0,0 --mmap -f S32_LE -r 96000
My linux is a slim Arch, the hardware is an outdated Lenovo T500 with a (by today's standards weak) Core2Duo Mobile processor. On this machine, the first and the last instance of camilladsp generate each a mere 0.3% cpu load. The convolution instance makes up for some 60% ... 65% cup load. Playback is stable and rock solid.
This is really great news, and it's getting absolutely interesting ... No more sox needed, no more brutefir needed ...
- Home
- Source & Line
- PC Based
- CamillaDSP - Cross-platform IIR and FIR engine for crossovers, room correction etc