I think this pipeline could be simplified a bit without changing the result. Since SOX uses int32 it might make sense to make the first conversion to int32 instead of float64. It probably give the same result, but makes it easier to follow what the pipeline is doing. Can SOX do format conversion at the same time as resampling? I guess it can, and then the first camilladsp wouldn't be needed at all (unless you also want to attenuate a little, but maybe sox can do that too?).This is very exciting news ... because it's really working !!! Three piped instances of camilladsp's within a same testbed:
The first instance to read in an audio.wav (S16LE) and transforming the bitdepth and format of the datastream to F64, could also perform -1dB .. -2dB to prevent intersample clipping in the following stages
(Then a samplerate conversion 44.1k->96k)
The second instance to perform the convolution, in this example 10x 128k Filters in full F64
The third instance to transform from F64 to S32, along with some dithering.
(Then aplay or playhrt)
and this looks like
camilladsp /home/privat/_camilladsp/BitXform/S16-F64.yml | \
resample_soxr ... --inrate=44100 --outrate=9600 | \
camilladsp /home/privat/_camilladsp/4way/4way.yml | \
camilladsp /home/privat/_camilladsp/BitXform/F64-S32.yml | \
aplay -c 2 -D hw:0,0 --mmap -f S32_LE -r 96000
My linux is a slim Arch, the hardware is an outdated Lenovo T500 with a (by today's standards weak) Core2Duo Mobile processor. On this machine, the first and the last instance of camilladsp generate each a mere 0.3% cpu load. The convolution instance makes up for some 60% ... 65% cup load. Playback is stable and rock solid.
This is really great news, and it's getting absolutely interesting ... No more sox needed, no more brutefir needed ...
Also the last camilladsp just doing conversion float64-int32 can be left out if the the conversion is added to the processing instance. Again, shouldn't change the result but if this was a "real" pipeline and not for testing, fewer steps is probably a good thing.
BTW, I'm also running Arch on my work laptop (with a fairly new 4-core i7). I run the Sway tiling window manager which is also light, and this thing is really (really really!) fast. But its starting to feel a bit unfair, I never have to wait for the computer to do anything, while it has to wait for me all the time.. 🙂
Last edited:
Hello.
I'am trying to build a new camilladsp.
I can't figure the compile options out, don't now why 😕
I have both this error with a build :
Also this one :
Really strange i cannot figure it out.
Henrik can you please 🙂 explain how i do it?
git clone
git checkout
git pull
I need 32bit, FFTW, -p switch, without pulse, with alsa
I allready tried options 1000 times without luck
Crazy me i know...
Jesper.
I'am trying to build a new camilladsp.
I can't figure the compile options out, don't now why 😕
I have both this error with a build :
./camilladsp: error while loading shared libraries: libpulse-simple.so.0: cannot open shared object file: No such file or directory
Also this one :
error: Found argument '-p' which wasn't expected, or isn't valid in this context
Really strange i cannot figure it out.
Henrik can you please 🙂 explain how i do it?
git clone
git checkout
git pull
I need 32bit, FFTW, -p switch, without pulse, with alsa
I allready tried options 1000 times without luck
Crazy me i know...
Jesper.
I'll try to explain the compile options a little better!
All the available options, or "features" are:
All the available options, or "features" are:
- alsa-backend
- pulse-packend
- socketserver
- FFTW
- 32bit
The first three (alsa-backend, pulse-packend, socketserver) are included in the default features, meaning if you don't specify anuthing you get those three.
Cargo doesn't allow disabling a single default feature, but you can disable the whole group with the --no-default-features flag. Then you have to manually ad the ones you want.
Example: I want alsa-backend, pulse-packend, socketserver and FFTW. The first three are included by default so I only need to add FFTW:
Code:cargo build --release --features FFTW
Example: I want alsa-backend, socketserver, 32bit and FFTW. Since I don't want pulse-backend I have to disable the defaults, and then add both alsa-backend and socketserver:
Code:cargo build --release --no-default-features --features alsa-backend --features socketserver --features FFTW --features 32bit
Hope thjis clears it up a little! I should probably work on this section of the readme..
Hey, very good.
This helped me a lot Henrik.
( btw.: I missed the post you wrote yesterday, but i will do as you wrote regarding more dokumentation, but i first have to fix and clean up some things)
Jesper.
This helped me a lot Henrik.
( btw.: I missed the post you wrote yesterday, but i will do as you wrote regarding more dokumentation, but i first have to fix and clean up some things)
Jesper.
I messed up the table in the previous post and now it's too late to edit. All the available options, or "features" are:
- alsa-backend
- pulse-packend
- socketserver
- FFTW
- 32bit
Yes, sox does indeed all these jobs, and as we know, with 32Bit accuracy. Then, there is a better alternative to sox for these tasks: resample_soxr. Resample_soxr is one of the frankl audio programs: frankl's stereo pages - PlayerI think this pipeline could be simplified a bit without changing the result. ... Can SOX do format conversion at the same time as resampling? I guess it can, and then the first camilladsp wouldn't be needed at all ...
resample_soxr reads in any audio file, converts the data first to float64, then performs samplerate conversion, volume adjustments ... every operation, unlike sox, with 64Bits accuracy.
So, a high-resolution audio pipe boils down to:
sudo chrt -f 93 taskset -c 0 resample_soxr --band-width 80 --buffer-length=8192 --file=${IN_FILE} --outrate=96000 --phase=25 --volume=0.8 | \
sudo chrt -f 94 taskset -c 0 camilladsp /home/privat/_camilladsp/4way/4way.yml | \
sudo chrt -f 95 taskset -c 0 volrace --buffer-length=1024 --volume=1.25 --max-volume=2.0 | \
sudo chrt -f 96 taskset -c 0 volrace --buffer-length=1024 --fading-length=24000 --param-file=/home/privat/_frankl/volrace.params | \
sudo chrt -f 97 taskset -c 0 camilladsp /home/privat/_camilladsp/BitXform/F64-S32_96000.yml | \
sudo chrt -f 98 taskset -c 0 writeloop --block-size=512 --file-size=3072 --shared --force-shm /bl1b /bl2b /bl3b & sleep 0.1; \
sudo chrt -f 98 taskset -c 1 catloop --block-size=256 --shared /bl1b /bl2b /bl3b | \
sudo chrt -f 99 taskset -c 1 playhrt --buffer-size=2048 --device=hw:0,0 --extra-bytes-per-second=-10 --extra-frames-out=24 --hw-buffer=4096 --loops-per-second=1500 --max-bad-reads=100000 --mmap --non-blocking-write --number-channels=2 --sample-format=S32_LE --sample-rate=96000 --sleep=10000 --stdin --stripped
Twice camilladsp. 1. camilladsp in order to convolve at a maximum possible level (after initial --volume=0.8 to prevent ISC), then to perform volume (re)adjustments in float64 by 2x volrace, then 2. camilladsp to convert back to S32 with some dithering.
Nice! Twice!
Ah right, I was reading with the brain turned off and resample_soxr became just sox..Yes, sox does indeed all these jobs, and as we know, with 32Bit accuracy. Then, there is a better alternative to sox for these tasks: resample_soxr. Resample_soxr is one of the frankl audio programs: frankl's stereo pages - Player
resample_soxr reads in any audio file, converts the data first to float64, then performs samplerate conversion, volume adjustments ... every operation, unlike sox, with 64Bits accuracy.
So, a high-resolution audio pipe boils down to:
sudo chrt -f 93 taskset -c 0 resample_soxr --band-width 80 --buffer-length=8192 --file=${IN_FILE} --outrate=96000 --phase=25 --volume=0.8 | \
sudo chrt -f 94 taskset -c 0 camilladsp /home/privat/_camilladsp/4way/4way.yml | \
sudo chrt -f 95 taskset -c 0 volrace --buffer-length=1024 --volume=1.25 --max-volume=2.0 | \
sudo chrt -f 96 taskset -c 0 volrace --buffer-length=1024 --fading-length=24000 --param-file=/home/privat/_frankl/volrace.params | \
sudo chrt -f 97 taskset -c 0 camilladsp /home/privat/_camilladsp/BitXform/F64-S32_96000.yml | \
sudo chrt -f 98 taskset -c 0 writeloop --block-size=512 --file-size=3072 --shared --force-shm /bl1b /bl2b /bl3b & sleep 0.1; \
sudo chrt -f 98 taskset -c 1 catloop --block-size=256 --shared /bl1b /bl2b /bl3b | \
sudo chrt -f 99 taskset -c 1 playhrt --buffer-size=2048 --device=hw:0,0 --extra-bytes-per-second=-10 --extra-frames-out=24 --hw-buffer=4096 --loops-per-second=1500 --max-bad-reads=100000 --mmap --non-blocking-write --number-channels=2 --sample-format=S32_LE --sample-rate=96000 --sleep=10000 --stdin --stripped
Twice camilladsp. 1. camilladsp in order to convolve at a maximum possible level (after initial --volume=0.8 to prevent ISC), then to perform volume (re)adjustments in float64 by 2x volrace, then 2. camilladsp to convert back to S32 with some dithering.
Nice! Twice!
The output part with writeloop->catloop->playhrt looks very complicated. I meant to ask earlier but forgot. What is the purpose of this?
I often use this writeloop/catloop buffering scheme within my pipes, because I see two main advances to do so:... The output part with writeloop->catloop->playhrt looks very complicated. I meant to ask earlier but forgot. What is the purpose of this?
1. A writeloop/catloop buffering pair provides control over the readyness state of a data stream, as writeloop writes three blocks of shared memory. Now if all these three blocks become active in /dev/shm, then everything with the incoming data is ok. This way, there is the opportunity to test this state within a loop, and then eventually trigger further events in case of audio data readyness. Eg. in applications including an on-off player like MDP, it is possible to setup MPD to pipe into writeloop. And then, from an outside loop, check for the /dev/shm blocks. If the /dev/shm blocks get ready, then another, independent pipe may be started, by opening it with catloop. That works fine.
2. There are cases of pipes where aplay works, and playhrt does not. In these cases, I have the impression that time/data continuity of the audio pipe may suffer from minor glitches. This is where a buffer section with writeloop/catloop saves the game. For playhr anyway, catloop as a direct feeder provides a good base. Within a multikernel system, the last catloop | playhrt section of the pipe may be running on the same, uniquely dedicated cpu kernel.
Writeloop/catloop accounts for 1.0%/1.3% cpu usage on my stone age system. So it's not very expensive in terms of processing. I always use it in the shm configuration, to avoid file system overhead and additional buffering by the operating system. It's even possible to include two (or more) such pairs within the same pipe. In this case, the naming of the memory blocks must be different from pair to pair.
Therefore this writeloop/catloop section occurs in my sample pipe I posted. I don't see any reason not to include it. But of course, maybe I am overlooking some drawbacks. If it were so, I am always grateful for further information/objections.
writeloop --help
Seriously?
In experiments I found that audio playback was improved compared to a
direct playing. For larger file sizes (a few megabytes) the effect was
similar to copying the file into RAM and playing that file.
But even better was the effect with small file sizes (a few kilobytes)
such that all files fit into the processor cache.
Seriously?
Hmm I read the documentation for hrtplay, catloop and writeloop and it seems to be a lot of shuffling back and forth between different buffers, don't see any benefit. I would actually think that the added complexity increases the risk of a buffer uderrun.I often use this writeloop/catloop buffering scheme within my pipes, because I see two main advances to do so:
1. A writeloop/catloop buffering pair provides control over the readyness state of a data stream, as writeloop writes three blocks of shared memory. Now if all these three blocks become active in /dev/shm, then everything with the incoming data is ok. This way, there is the opportunity to test this state within a loop, and then eventually trigger further events in case of audio data readyness. Eg. in applications including an on-off player like MDP, it is possible to setup MPD to pipe into writeloop. And then, from an outside loop, check for the /dev/shm blocks. If the /dev/shm blocks get ready, then another, independent pipe may be started, by opening it with catloop. That works fine.
2. There are cases of pipes where aplay works, and playhrt does not. In these cases, I have the impression that time/data continuity of the audio pipe may suffer from minor glitches. This is where a buffer section with writeloop/catloop saves the game. For playhr anyway, catloop as a direct feeder provides a good base. Within a multikernel system, the last catloop | playhrt section of the pipe may be running on the same, uniquely dedicated cpu kernel.
Writeloop/catloop accounts for 1.0%/1.3% cpu usage on my stone age system. So it's not very expensive in terms of processing. I always use it in the shm configuration, to avoid file system overhead and additional buffering by the operating system. It's even possible to include two (or more) such pairs within the same pipe. In this case, the naming of the memory blocks must be different from pair to pair.
Therefore this writeloop/catloop section occurs in my sample pipe I posted. I don't see any reason not to include it. But of course, maybe I am overlooking some drawbacks. If it were so, I am always grateful for further information/objections.
In the end it's just about writing samples to a buffer from which the kernel driver can then copy them to the hardware.
The first point about the possibility for checking the datastream makes sense, but it still seems complicated. There must be a simpler way..
I have now updated "master" to version 0.0.12, which has been waiting in "develop" for a while. The "develop" branch now holds v0.0.13, with these new features:
- You can start without a config file, and wait for one to be provided via the websocket server
- You can stop processing and wait for a new config
- Various fixes to make config file error messages better
- Extended the build instructions in the readme
I have now updated "master" to version 0.0.12, which has been waiting in "develop" for a while. The "develop" branch now holds v0.0.13, with these new features:
- You can start without a config file, and wait for one to be provided via the websocket server
- You can stop processing and wait for a new config
- Various fixes to make config file error messages better
- Extended the build instructions in the readme
While getting everything working now, i have a little issue with the CamillaDSP 0.0.12
not this brandnew one yet 😉
I can do this for samplerate change :
from subprocess import *
import time
from websocket import create_connection
ws = create_connection("ws://127.0.0.1:3011")
ws.send("setconfigname:/home/tc/DSP_Engine/filters/rate_44100.yml")
ws.send("reload")
While this don't change samplerate :
from subprocess import *
import time
from websocket import create_connection
ws = create_connection("ws://127.0.0.1:3011")
ws.send("setconfig:{/home/tc/DSP_Engine/filters/rate_44100.yml}".format(cfg))
I bellive the syntax is wrong (as allway's when i try 😛😱)
(I will try to build the new one later.)
Jesper.
Your format command looks very strange. The setconfig command should give the yaml file contents as a string, not the filename. Try this:
Code:
from websocket import create_connection
ws = create_connection("ws://127.0.0.1:3011")
# read the contents of the config file
with open("/home/tc/DSP_Engine/filters/rate_44100.yml") as f:
cfg=f.read()
ws.send("setconfig:{}".format(cfg))By the way, updating the config via the websocket server makes it easy to modify the config before sending it. Like this for example:
Code:
import yaml
from websocket import create_connection
# read the config to a Python dict
with open("simpleconfig.yml") as f:
cfg=yaml.safe_load(f)
# Modify something
cfg["devices"]["samplerate"] = 96000
# Serialize to yaml string
modded = yaml.dump(cfg)
# Send the modded config
ws = create_connection("ws://127.0.0.1:3011")
ws.send("setconfig:{}".format(modded))
print(ws.recv())So I have started looking into this. The plan is to add an (optional!) asynchronous sample rate converter in the capture process. This would then be controlled via the same mechanism that is used to set the speed of a loopback device. The use case is for phofmans case A, when the source and sink are using different clock sources.Many people (including me) keep hitting the problem of multiple master clocks in the chain. There are two cases:
A) All master clocks are fixed, uncontrollable by the chain.
Example: Two separate soundcards (clocked by crystal or SPDIF input).
....
Case A) requires some form of adaptive resampling, no other option possible.
I have written an ugly and slow test in Python, but even in this state it works pretty well. Resampling a 10kHz sine from 44100Hz to 44200Hz gives the spectrum in the attached file. The y-axis is in dB, blue is before and orange is after resampling.
The whole thing is based on this paper: https://www.analog.com/media/en/tec...-articles/5148255032673409856AES2005_ASRC.pdf
Attachments
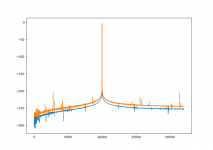
Henrik, fantastic results, the resampling artefacts are deep below any real-world noise.
I wonder if there was a chance to have this as a standalone binary.... but there would be the problem with output, how to chain with the next part. Just your source code will be a very important help for implementing the algorithm in other projects.
I wonder if there was a chance to have this as a standalone binary.... but there would be the problem with output, how to chain with the next part. Just your source code will be a very important help for implementing the algorithm in other projects.
Is this running at 64 bit float? I guess it has to be because otherwise artefacts would be way higher. Don't get me wrong, still impressive. And I still have to be convinced that resampling with a high quality resampler at 32 bit float even has audible artifacts.
Just my 2 cts
Just my 2 cts
Thanks! I still haven't written any rust code for this. Once I start the plan is to make the resampler a separate library. For CamillaDSP the resampling must be embedded, but I'll need to make some standalone application for testing the library anyway. I could spend a little more time and make it usable for more than testing.Henrik, fantastic results, the resampling artefacts are deep below any real-world noise.
I wonder if there was a chance to have this as a standalone binary.... but there would be the problem with output, how to chain with the next part. Just your source code will be a very important help for implementing the algorithm in other projects.
Yes it's 64-bit, simply Python default floats. With 32-bit the noise floor would be somewhere around -140dB. The graph I posted doesn't reach the 64-bit noise floor because of how I windowed the signal before fft. Once it's in rust, playing with 32-bit floats becomes easy.Is this running at 64 bit float? I guess it has to be because otherwise artefacts would be way higher. Don't get me wrong, still impressive. And I still have to be convinced that resampling with a high quality resampler at 32 bit float even has audible artifacts.
Just my 2 cts
- Home
- Source & Line
- PC Based
- CamillaDSP - Cross-platform IIR and FIR engine for crossovers, room correction etc