The plots you see here paint a picture of deep dips. But you've got to remember our head is in the middle of those two wave fronts. So the first wave to hit the ears will be the left and right signal hitting the left and right ear and the dips will be caused by the sound that hits the other ear about ~0.270 - 0.290 ms later (left signal hitting right ear and right signal hitting left ear that cancels with the direct wave front with that time difference between them). No doubt the signal traveling around the head is a bit lower in SPL than that first wave front due to head shading. The biggest problem will be the ~2 KHz signal creating the largest dip. By adjusting the phase angle (gradually shifting) those sounds will no longer completely cancel each other, though they probably won't sum ideally either.
We might be able to sim that as well to see how it looks.
All it would take is summing 2 sweeps with the same ~0.270 - 0.290 ms timing difference after first applying the left phase shuffler to the first and the right phase shuffler to the second one. The result of that should show the theoretical difference.
Right? Or did I miss anything...
At the mic spot, without a head and both signals being in perfect phase you should get a perfect sum as there is no time difference. Move one inch to the side and combing starts as you will have introduced a timing difference between left and right.
Sitting in the sweet spot with a matrass in front of your face should cancel those dips as well I guess.
We might be able to sim that as well to see how it looks.
All it would take is summing 2 sweeps with the same ~0.270 - 0.290 ms timing difference after first applying the left phase shuffler to the first and the right phase shuffler to the second one. The result of that should show the theoretical difference.
Right? Or did I miss anything...
At the mic spot, without a head and both signals being in perfect phase you should get a perfect sum as there is no time difference. Move one inch to the side and combing starts as you will have introduced a timing difference between left and right.
Sitting in the sweet spot with a matrass in front of your face should cancel those dips as well I guess.
An externally hosted image should be here but it was not working when we last tested it.
I should have figured that out sooner, here's a dirac pulse summed with a 270 ms difference:

Here's Pano's RePhase shuffle-2 summed at 270 ms difference:

The two compared:

Does this help us create a better recipe? Interesting what that extra shuffle at ~3.7 KHz does for the signal, is that why I like it so much? There are still dips, but they moved around a bit. That extra wiggle creates a wider flat spot though... hmmm... interesting 🙂
Here's Pano's RePhase shuffle-2 summed at 270 ms difference:
The two compared:
Does this help us create a better recipe? Interesting what that extra shuffle at ~3.7 KHz does for the signal, is that why I like it so much? There are still dips, but they moved around a bit. That extra wiggle creates a wider flat spot though... hmmm... interesting 🙂
Attachments
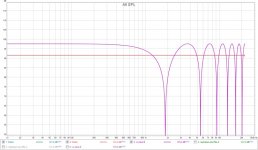
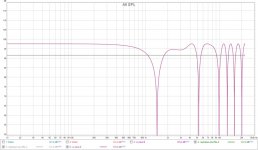
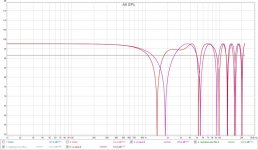
Something I have to try soon is Pano's recipe with a couple of cuts...
Here's the Dirac with 0.270 ms difference plot:

Which made me cut at 3700 Hz, Q = 2.7, Gain = -1.4 and 7270 Hz, Q = 2.7, Gain = -1.
And here is RePhase Shuffle-2 with 2 cuts:

Cut at 4270 Hz, Q = 2, Gain = -2.6 plus 6900 Hz, Q = 2, Gain = -3.1
Remember, this is happening after hearing the original wave front, after that 0.27 ms time difference has passed. This tweak might still benefit from a slight boost of the center channel compared to the sides between 2 and 10 KHz.
What do you guys think? I did try and better the shuffler but as the peaks move closer together I wasn't successful to do it yet without adjusting Q (which I didn't want to do).
Here's the Dirac with 0.270 ms difference plot:
Which made me cut at 3700 Hz, Q = 2.7, Gain = -1.4 and 7270 Hz, Q = 2.7, Gain = -1.
And here is RePhase Shuffle-2 with 2 cuts:
Cut at 4270 Hz, Q = 2, Gain = -2.6 plus 6900 Hz, Q = 2, Gain = -3.1
Remember, this is happening after hearing the original wave front, after that 0.27 ms time difference has passed. This tweak might still benefit from a slight boost of the center channel compared to the sides between 2 and 10 KHz.
What do you guys think? I did try and better the shuffler but as the peaks move closer together I wasn't successful to do it yet without adjusting Q (which I didn't want to do).
Attachments

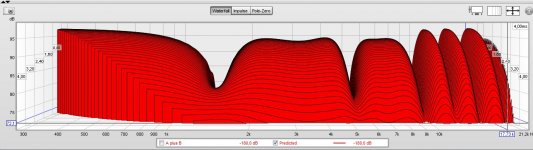
An externally hosted image should be here but it was not working when we last tested it.
Oh, the patented "mattress nose hanger sound spatializer equilibriator"! 🙂
Sitting in the sweet spot with a matrass in front of your face should cancel those dips as well I guess.
An externally hosted image should be here but it was not working when we last tested it.
Tight radiation horns work in my room although the center does shift a bit side to side when moving the cross talk is low and the central tone is excellent
At least it shows why we all hear different, nose sizes vary you know 😀...
Scrap my above comments as I just simulated what happens at the other ear (by shifting the other signal 0.270 ms). It shows a different plot:

It also shows us the average of those two plots will have a better potential than getting to hear the dirac in left and right ear, as there will be no change between the plots there.
The phase shuffler does work (remarkably well for a "shot in the dark") to fill in dips at the center when we look at the combined result.
You either get 2x the dirac or the more equally summing phase shifted plots.
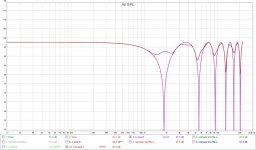
If we average the shuffler and compare it to the dirac we see this:

Probably why it will sound a bit brighter and retain more detail.
Scrap my above comments as I just simulated what happens at the other ear (by shifting the other signal 0.270 ms). It shows a different plot:
It also shows us the average of those two plots will have a better potential than getting to hear the dirac in left and right ear, as there will be no change between the plots there.
The phase shuffler does work (remarkably well for a "shot in the dark") to fill in dips at the center when we look at the combined result.
You either get 2x the dirac or the more equally summing phase shifted plots.
If we average the shuffler and compare it to the dirac we see this:
Probably why it will sound a bit brighter and retain more detail.
Attachments
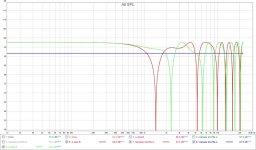
One more thing to add... the left and right FR remains the same as far as cross talk is considered. They each sum exactly as the original dirac pulse does. So no change for the side frequency balance as far as this shuffler is concerned (aside from the possible perception of the phase wiggle).
Tight radiation horns work in my room although the center does shift a bit side to side when moving the cross talk is low and the central tone is excellent
Mike made it easy to try a few sound clips, you could try if it does anything for you at all:
https://www.dropbox.com/sh/p2eww8mm4kxl4rf/AABwdEsCWT19nk6e5jfl8o2La?dl=0
Clips in "Original" (unprocessed), "Pano Rephase-2", and "Mike Min9".
Jane - Ben Folds Five
Our Prayer - Beach Boys (original mono)
Impossible Spaces - Sandro Perri
Limit to Your Love - James Blake
Black Skinhead - Kanye West
River Deep, Mountain High - Tina Turner (original mono)
Drume Negrita - Ry Cooder and Manuel Galban
De Camino a La Vereda - Buena Vista Social Club
Bang Bang - Nancy Sinatra (original *almost* dual mono)
Surf's Up (solo piano version) - Brian Wilson
Can't Feel My Face - The Weeknd
Angel - Sarah McLaughlin
A Movie Script Ending - Death Cab for Cutie
Clips are the same volume although peak levels are different due to the phase shuffling.
With your horns you'd already be in a favorable position due to avoiding early reflections. Easy enough to try 🙂.
Last edited:
wesayso,
Great thanks share hard work and thinking for us. Had those traces yesterday after posting the high resolution IR-file of comb filter but it was over my head to think which ones could be right out of the math combinations on "All SPL" tab. Try merge the two you created in first plot post 346 by say A plus B and we pretty much back at comb filter and that confuse me at moment 😛.
Great thanks share hard work and thinking for us. Had those traces yesterday after posting the high resolution IR-file of comb filter but it was over my head to think which ones could be right out of the math combinations on "All SPL" tab. Try merge the two you created in first plot post 346 by say A plus B and we pretty much back at comb filter and that confuse me at moment 😛.
What you see in the first graph of post 346 is the sound arriving at the left and the right ear after 0.27 ms.
All that has happened compared to no shuffler is the dips have been shifted and they sum different at the ears, making it different in perception in your head.
To to me it doesn't make any sense to add them again. Our brains will do that math. All you have to ask yourself what will sound better, the dirac sum arriving at both ears or the signals in the first plot in post 346. Remember this is not completely true to reality, the sound that travels around our head and arrives late at the other ear will be down in volume. All plots here are at equal volume and it makes them easier to read but the reality will be less severe (I hope). If you compare it to the Toole plots the general trends seem to hold true.
All the sims I did were with 0.27 ms delay. I'm pretty sure that's my ideal number. All of my previous experiments and my EQ cuts confirmed that.
In time I hope we can find an even better summing shuffler. But so far this one certainly isn't bad at all.
Just played a few tracks with adjusted EQ settings (based on the average response, nothing heavy) and I've got to say it opens up the sound like before, it's very clear and equal across the stage. I like it.
Basically it does something you can't do with EQ. You can't boost a dip, but we can shuffle it 😀.
All that has happened compared to no shuffler is the dips have been shifted and they sum different at the ears, making it different in perception in your head.
To to me it doesn't make any sense to add them again. Our brains will do that math. All you have to ask yourself what will sound better, the dirac sum arriving at both ears or the signals in the first plot in post 346. Remember this is not completely true to reality, the sound that travels around our head and arrives late at the other ear will be down in volume. All plots here are at equal volume and it makes them easier to read but the reality will be less severe (I hope). If you compare it to the Toole plots the general trends seem to hold true.
All the sims I did were with 0.27 ms delay. I'm pretty sure that's my ideal number. All of my previous experiments and my EQ cuts confirmed that.
In time I hope we can find an even better summing shuffler. But so far this one certainly isn't bad at all.
Just played a few tracks with adjusted EQ settings (based on the average response, nothing heavy) and I've got to say it opens up the sound like before, it's very clear and equal across the stage. I like it.
Basically it does something you can't do with EQ. You can't boost a dip, but we can shuffle it 😀.
Last edited:
Thanks taking time, think will take a rest and look at stuff with fresh eyes tomorrow.
Think about in meantime if any real live electric loop over weekend can help to explore results even more, in i have two AP192 equiped machines that are able to loop up to 192kHz with SPDIF signal all along the route which means they total clean from analog clutter and bench IR as the perfect ones created in Rephase. A scenario could be use side buzz routing plus adjust volume and delays inside JRiver that is available on both listening and playback computer so as REW end up being the listening head in the loop between power of 2 times JRiver DSP.
Think about in meantime if any real live electric loop over weekend can help to explore results even more, in i have two AP192 equiped machines that are able to loop up to 192kHz with SPDIF signal all along the route which means they total clean from analog clutter and bench IR as the perfect ones created in Rephase. A scenario could be use side buzz routing plus adjust volume and delays inside JRiver that is available on both listening and playback computer so as REW end up being the listening head in the loop between power of 2 times JRiver DSP.
Should be fun! But the difference in SPL we have to guess at without any measurements.
Now that I know what "I think" I'm looking for I can actually improve the results somewhat, all theoretically of coarse 😀.
Now that I know what "I think" I'm looking for I can actually improve the results somewhat, all theoretically of coarse 😀.
Average of Pano vs a new attempt:

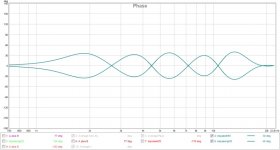
Phase of the new version:

For those willing to give it a go, I'll add it to this post...
(I'll probably fine tune it a couple of hundred times though )
)
Phase of the new version:
For those willing to give it a go, I'll add it to this post...
(I'll probably fine tune it a couple of hundred times though
)Attachments

Last edited:
I don't know. Would have to sit down with pencil and paper to figure that out....won't there still have to be a point in space where the combination of LR still nulls?
At the original comb frequency you've shifted the speakers 60 or more degrees out of phase. Where would they combine again?
I don't know. Would have to sit down with pencil and paper to figure that out.
At the original comb frequency you've shifted the speakers 60 or more degrees out of phase. Where would they combine again?
I think I may have answered that question. We are shifting the dips and the resulting sum (of the signal at the left and right ear) fills the dips.
We are not avoiding any dips here. That wouldn't be possible without altering the frequencies played.
IDEA
I havn't read All the posts, so forgive me if someones already posted this idea !
How about blending a Just a portion of L + R mono summed together, & mixing this in to the L & R signals. This "might" help to fix a stable central image ? Of course you could also tinker with the blend, if need be, with eq etc etc. The blend would i guess, be better if it was made variable in level, so people could fine tune it.
I havn't read All the posts, so forgive me if someones already posted this idea !
How about blending a Just a portion of L + R mono summed together, & mixing this in to the L & R signals. This "might" help to fix a stable central image ? Of course you could also tinker with the blend, if need be, with eq etc etc. The blend would i guess, be better if it was made variable in level, so people could fine tune it.
Actually that is close to my original idea, before I stumbled onto the shuffler.  The shuffler works better and is easy to use. Many of the reasons why are described in the paper linked to at the top of the thread.
The shuffler works better and is easy to use. Many of the reasons why are described in the paper linked to at the top of the thread.
The shuffler works better and is easy to use. Many of the reasons why are described in the paper linked to at the top of the thread.I havn't read All the posts, so forgive me if someones already posted this idea !
How about blending a Just a portion of L + R mono summed together, & mixing this in to the L & R signals. This "might" help to fix a stable central image ? Of course you could also tinker with the blend, if need be, with eq etc etc. The blend would i guess, be better if it was made variable in level, so people could fine tune it.
You could do it easy with Voxengo's mid/side vst plugin. Just boost the mid channel. You can even use it as a mid/side encoder and/or decoder to have EQ in between. But it doesn't quite work, more below...
Actually that is close to my original idea, before I stumbled onto the shuffler.
Yes I agree... changing the phantom signal too much would upset the frequency balance and screw with the stereo image. While the phantom center might sound better it would eat away all signals panned between left and center and right and center.
This cross talk mostly interferes with the phantom center, not the left and right panned sounds.
Ultimately it would lead to an ambiophonic solution to gain back what you lost by introducing a cross talk cancelation signal(*). The most powerful version of that implementation is probably the one from Professor Edgar Y. Choueiri. He calls it BACCH,
https://www.princeton.edu/3D3A/Publi...CHPaperV4d.pdf
Though other solutions and options do exist. One thing they have in common is the need to get the speakers closer together to make it work. More info on some of the other solutions at: Home Page
The shuffler doesn't upset the FR balance, it merely shifts dips left and right making it sum differently at the ears.
You could use something like this trick:

(JRiver processing chain)
Just to find your exact sweet spot. Just vary the time delay of (center), here set at 0.29 ms to find your sweet spot. You can make it more powerful by reducing the -15 dB to something less. It will mess up your stage but it will enhance the phantom center. Keep changing it till you find a setting that creates the most believable center image. I ended up liking 0.27 ms the most.
Don't mind the rest of the stage. You need good speakers with even balance and relatively smooth phase and avoid early reflections for best results. This is equally important for the shuffler to function as advertised.
Once you find that sweet spot you can make an exact fit shuffler based on that delay.
0.27 ms should already be pretty close if you use a standard 60 degree equilateral stereo setup and with an average head size.
(*) unless you can live with a physical barrier like Don Keele demonstrates here (taken from a presentation by Siegfried Linkwitz by the way)
Link to presentation.
An old matrass would probably work even better. 😀
Attachments

{kind=link}
Last edited:
I suspect that the inter-aural cancellation is only theoretically correct to use below about 1kHZ, and we may be coloring the upper-midrange with FR ripple that doesn't get us real improvement.
Below about 1kHZ we sense image location largely by timing or phase comparison, as opposed to above about 1kHZ where we sense image location apparently only by amplitude comparisons. I've read this in many papers. This is because the brain has no way of knowing which period of waveshape it's comparing, when the half or full wavelengths (not sure which) are shorter than the distance between the ears.
Since our attempt to cancel inter-aural crosstalk causes comb filter cancellations above about 1kHZ, wouldn't it be nice if we didn't have to do that? I've read many times that stereo image cues in the upper midrange are dependent on the balance of amplitude over frequency between the L and R speakers. since you can't separate the center signal from the L and R for independent processing without matrix crosstalk, I'm still having a hard time imagining how a phantom center image can be improved, beyond using inter-aural cancellation to spread the images apart more.
The result of the shuffler may work great, but it does leave you with 6dB+ FR variations in the upper frequencies, which by themselves could fool someone into thinking there is more depth or presence etc.
In the modified Carver "Holographic Generator" circuit I'm building right now I've included a BW limit for the inter-aural cancellation at 1kHZ as an option, switchable on the front panel. It may not create as dramatic an effect, but may be more accurate, less coloring of the upper frequencies and their imaging cues. Any thoughts?
Below about 1kHZ we sense image location largely by timing or phase comparison, as opposed to above about 1kHZ where we sense image location apparently only by amplitude comparisons. I've read this in many papers. This is because the brain has no way of knowing which period of waveshape it's comparing, when the half or full wavelengths (not sure which) are shorter than the distance between the ears.
Since our attempt to cancel inter-aural crosstalk causes comb filter cancellations above about 1kHZ, wouldn't it be nice if we didn't have to do that? I've read many times that stereo image cues in the upper midrange are dependent on the balance of amplitude over frequency between the L and R speakers. since you can't separate the center signal from the L and R for independent processing without matrix crosstalk, I'm still having a hard time imagining how a phantom center image can be improved, beyond using inter-aural cancellation to spread the images apart more.
The result of the shuffler may work great, but it does leave you with 6dB+ FR variations in the upper frequencies, which by themselves could fool someone into thinking there is more depth or presence etc.
In the modified Carver "Holographic Generator" circuit I'm building right now I've included a BW limit for the inter-aural cancellation at 1kHZ as an option, switchable on the front panel. It may not create as dramatic an effect, but may be more accurate, less coloring of the upper frequencies and their imaging cues. Any thoughts?
- Home
- Loudspeakers
- Multi-Way
- Fixing the Stereo Phantom Center