I suspect that very few people actually notice the problem because their listening rooms aren't acoustically dead enough.
Pano, you mentioned having a dead room and I know Wesayso made acoustic panels for his room. What locations did you treat and with absorption or diffusion. Once I finish my line arrays with TC9's (one speaker done), I'm considering building floor to ceiling bass traps for the two corners by the speakers and then go from there. Is this needed with line arrays? Everyone discussing room treatments uses line sources.
I did not use bass traps, but I also wasn't using line arrays. Just thick fiberglass panels where the reflections would be, thick carpet on a good pad, some diffusion between the speakers and behind me. All DIY of course. And my speakers were fairly directional, too.
I found it did not take huge amounts of room treatment to kill the majority of reflection problems.
I found it did not take huge amounts of room treatment to kill the majority of reflection problems.
I have mid-side on my bucket list but just don't have the platform at the moment to try it.
All my absorption test has ended up me thinking it sounds dead. Even after EQ adjustments for the FR difference. But I probably have some way to go here...
//
All my absorption test has ended up me thinking it sounds dead. Even after EQ adjustments for the FR difference. But I probably have some way to go here...
//
Only measurements can tell....
It is a fun road I travel, but do remember that I'm treating my setup as a play garden to learn from. I want to try out stuff to form my opinion on it, learn how and why I hear what i hear. Some experiments are useful, others turn out to be a waste of time.
Overall I managed to learn quite a few things. I can better relate what i measure to what I hear, by limiting a lot of variables. I'm playing around with them, in an as controlled manner as I can think of.
Early on I already tried a lot, and simply cannot describe all of the different types of sound I've heard. There can be such huge differences in perception, which makes it pretty hard to analyze. I do it as a hobby, where most people move on to the next build, for now, this is it for me. I'm focused on improving what I've got. And I have to say, that really works! Slow, but it works...
The moments I browse this forum (I do that a lot) and stumble upon posts like this:
Or this:
Source: https://www.diyaudio.com/forums/full-range/336658-ids-25-clone.html#post5760632
I do tend to smile and feel a bit proud about it all. In the end, I'm just catering to my own taste and preferences, but it feels pretty good that at least others seem to agree with it, that it isn't just "bad taste" from my side 🙂. I've learned a lot, but still think I know hardly anything... at least, that's how it feels (lol). I'll keep on going as long as it's a fun way to spend my time. Can't wait to go back into the garage to finish the subs!
It is a fun road I travel, but do remember that I'm treating my setup as a play garden to learn from. I want to try out stuff to form my opinion on it, learn how and why I hear what i hear. Some experiments are useful, others turn out to be a waste of time.
Overall I managed to learn quite a few things. I can better relate what i measure to what I hear, by limiting a lot of variables. I'm playing around with them, in an as controlled manner as I can think of.
Early on I already tried a lot, and simply cannot describe all of the different types of sound I've heard. There can be such huge differences in perception, which makes it pretty hard to analyze. I do it as a hobby, where most people move on to the next build, for now, this is it for me. I'm focused on improving what I've got. And I have to say, that really works! Slow, but it works...
The moments I browse this forum (I do that a lot) and stumble upon posts like this:
Source: https://www.diyaudio.com/forums/multi-way/334790-school-2way-paper-sound-philosophy-seas-ss-sba-3.html#post5725549How about buying the cheapest driver and amplifier and then use cheap DSP to flatten the response at ears position? Taa daa.. we have a system that is comparable with the most expensive system in the world.
Partially yes, as long as the system is not forced too much and stays within its motor lineairity. After listening to the 25 Vifa TC 9 oer side full range, digitally in-room-equalized Wesayso system (see the 4000+ posts thread Tale of Two Towers here on diyaudio) I am even more convinced about that. Best system I heard ever, regardless of price.
Another example is the Kii 3 system: cheap bread'nbutter drivers plus extensive DSP correction. Regarded by many as on of the the best compact systems around. Kef LS50 active is another great example.
But hey, who am I to say all this? Feel free to spend away money at exotic components and throw them in a box and then have the illusion of owning the best system in the world.
Or this:
Want to make something even better than Mr Russell's IDS-25? Just read the tome or textbook on the topic by Wesayso in this thread:
The making of: The Two Towers (a 25 driver Full Range line array)
There is a recipe in there and if you follow it, you will be rewarded with, and I kid not, perhaps the finest sounding speaker in the world, anywhere, any price. I have heard it myself and it is simply staggering and mind blowing what the sound quality and realism is like.
But there are a lot of fine details and much of it requires real time DSP to realize. A lot of it requires room treatments. Lot's of little things that when all pieced together, yield a sum greater than their parts.
Source: https://www.diyaudio.com/forums/full-range/336658-ids-25-clone.html#post5760632
I do tend to smile and feel a bit proud about it all. In the end, I'm just catering to my own taste and preferences, but it feels pretty good that at least others seem to agree with it, that it isn't just "bad taste" from my side 🙂. I've learned a lot, but still think I know hardly anything... at least, that's how it feels (lol). I'll keep on going as long as it's a fun way to spend my time. Can't wait to go back into the garage to finish the subs!
Last edited:
Another read trough: US20130163766A1 - Spectrally Uncolored Optimal Crosstalk Cancellation For Audio Through Loudspeakers
- Google Patents for some inspiration.
The last cross talk cancellation setup I tried was pretty promising, I'm trying to figure out where to go from there. I do have a few ideas, however I'm lacking the time alone with my toys to try everything.
To state the not so obvious, I'm aiming for a more global solution, that cures the specific sweet spot problems without affecting the off axis spots as used in Home Theatre or family listening.
- Google Patents for some inspiration.
The last cross talk cancellation setup I tried was pretty promising, I'm trying to figure out where to go from there. I do have a few ideas, however I'm lacking the time alone with my toys to try everything.
To state the not so obvious, I'm aiming for a more global solution, that cures the specific sweet spot problems without affecting the off axis spots as used in Home Theatre or family listening.
Last edited:
Going for a "race" to the finish...
Going back trough the "fixing the Stereo Phantom Center" thread, Dr. Choeiri's work and my own experiments to see if I can come up with something useful.
A race to the finish 😉.
The difficult part here is to adjust the idea to a regular Stereo setup instead of the closely spaced speakers. The aim is to have a great sweet spot but keet it's benefits of a wider suitability to seats next to it.
I've been eye-ing the plots made by jim1961 (made under excellent conditions), figuring out the effects of my own experiments, the theory of the original shuffler, the phase swopper that resulted from that as well as my own mid/side EQ.
Yesterday while laying back in the sun some ideas popped into my head. So I'm fully inspired again to take another shot at it.
It will take some time to implement and to get a good listen. Fingers crossed!
After all, how hard can this puzzle be! 😀
Going back trough the "fixing the Stereo Phantom Center" thread, Dr. Choeiri's work and my own experiments to see if I can come up with something useful.
A race to the finish 😉.
The difficult part here is to adjust the idea to a regular Stereo setup instead of the closely spaced speakers. The aim is to have a great sweet spot but keet it's benefits of a wider suitability to seats next to it.
I've been eye-ing the plots made by jim1961 (made under excellent conditions), figuring out the effects of my own experiments, the theory of the original shuffler, the phase swopper that resulted from that as well as my own mid/side EQ.
Yesterday while laying back in the sun some ideas popped into my head. So I'm fully inspired again to take another shot at it.
It will take some time to implement and to get a good listen. Fingers crossed!
After all, how hard can this puzzle be! 😀
Attachments

Tested the theory today, this is a path to follow for the coming time... 🙂
I replaced all mid/side EQ with an anti cross talk signal.
Let me explain the 'tongue in cheek' remark I made in my last post... the "race" to the finish...
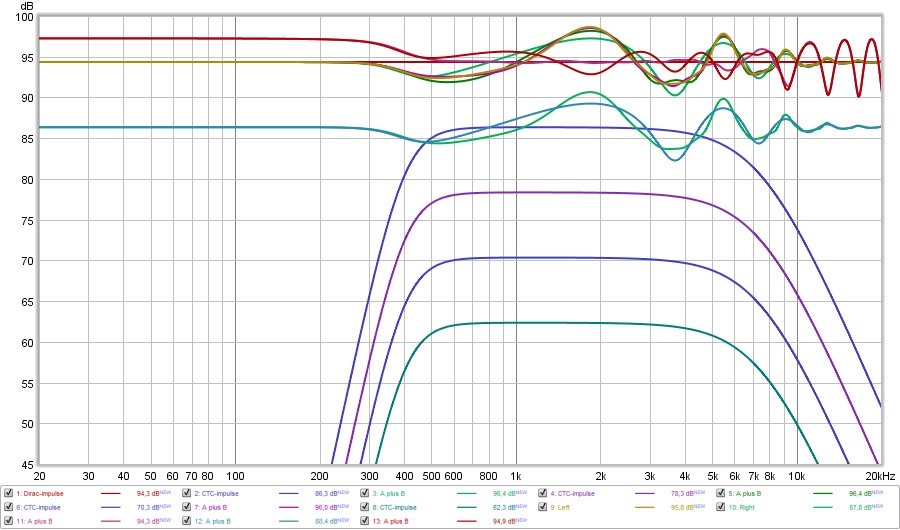
In the cross talk I experience at the sweet spot in my ~30 degree stereo setup, the biggest dip is going to be somewhere around 1850 Hz. I've mentioned that a couple of times. I measured the path lengths with simple strings and also tried to find it with delayed signals. This 1850 Hz dip relates to the right ear getting the left signal about 0.272 ms after the right main wave front or pulse. And vice versa.
That was what that negative pulse I use at 0.272 ms was all about. However, if we look at the length of a signal at 1850 Hz, we notice that it takes about ~0.54 ms at that wavelength to complete a full cycle.
So the wrap around wave that travels from the left speaker into the right ear is half a wavelength behind the wave front arriving at that same ear from the right speaker. That's the cause of that dip, obviously. 😉
However, a tone that's playing at that frequency usually consists of more than one cycle. So while the left and right both are playing the tone, we get that dip consistently at both our ears when listening in the exact sweet spot.
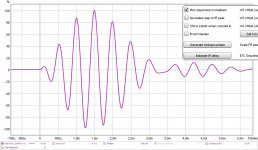
To tune my speakers, I use about a 4 cycle length of correction in the midrange. This is because when looking at a wave shape as measured in REW, it takes about that long for the signal to reach it's maximum output. That isn't to say each tone we hear is going to take that long though...
Here's a look at the wave shape filtered at 1/3 at 2000 Hz:
Here you can see that at about the 4th cycle we reach the maximum level.
A true wave shape in a song could be either shorter or longer, however in my DRC experiments, that 4 cycle frequency dependent window is just long enough to give an effective correction, while being short enough to be "out of there" before the room takes over. Put in another way, an effective correction can be based on this length of window.
Anyway, if you have one corrective anti cross talk dip, it is only going to cure that cross talk dip partially. That negative spike is going to be heard by the other ear too!
There in lies the basics of the "Race" algorithm's used in Ambiophonics.
Basically, we use a dip at about 0.27 ms that tries to block the sound coming from the opposite speaker. Next we get a slightly lower in SPL positive spike at 0.54 ms, (remember the wavelength at 1850 Hz being 0.54 ms in length?) that counter act's the negative first spike, as that too, will travel to the other ear, after first blocking the sound from the opposite speaker. Repeated enough times, it will be so low in SPL, it won't be heard anymore.
That's a mouth full, let's see it in pictures:
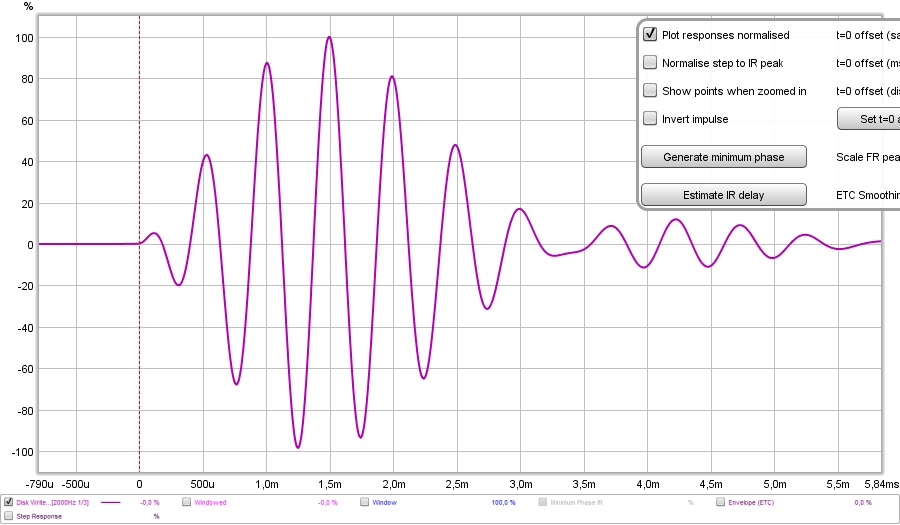
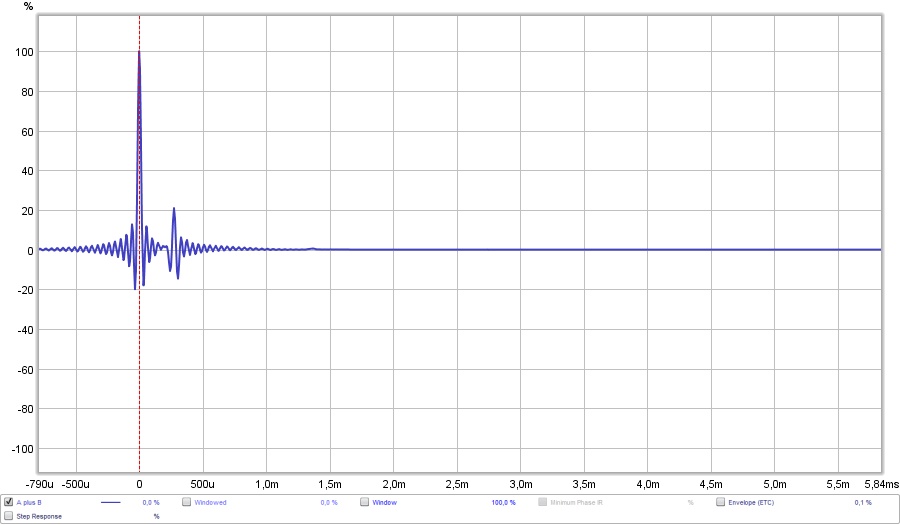
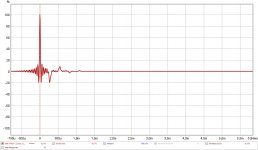
Here's the main pulse (this picture is made with an ideal Dirac pulse as a start signal) and the cross talk cancelation dips and peaks:
What we see here is that "race" algorithm, with 4 consecutive dips/peaks
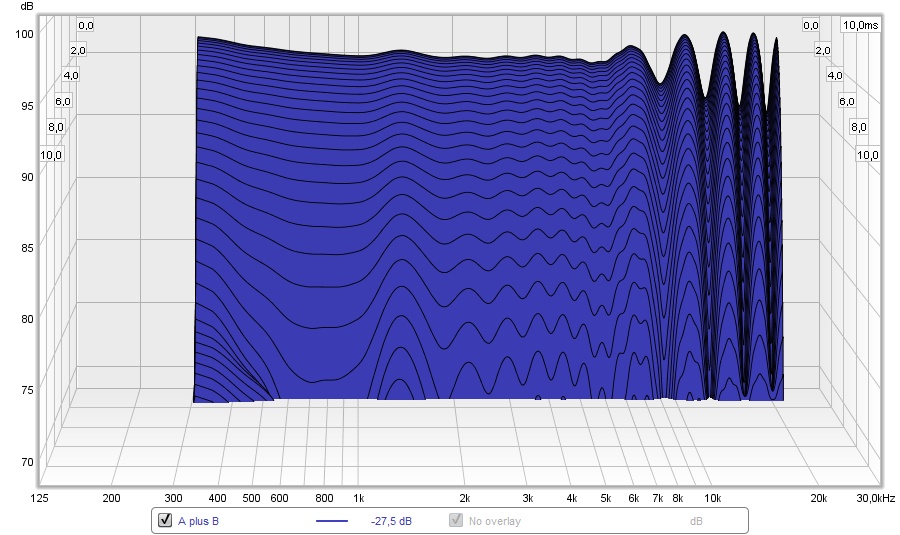
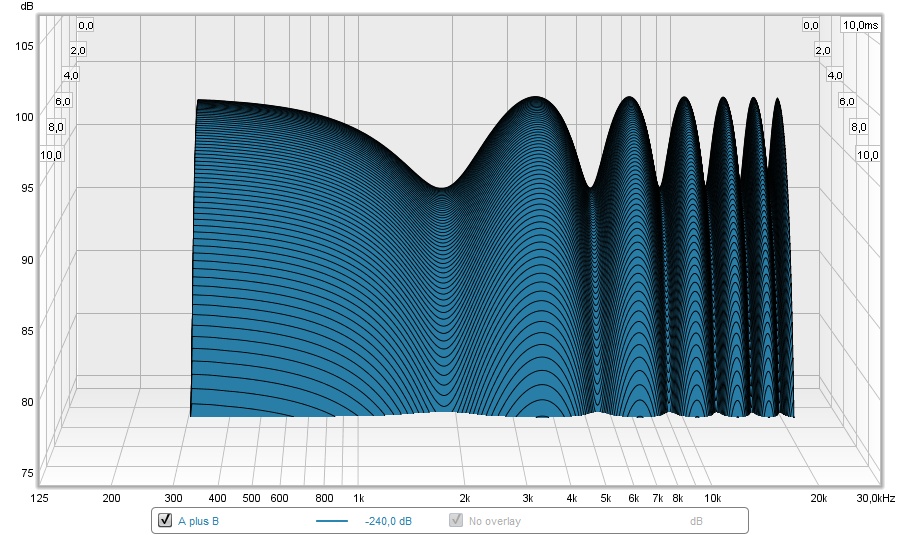
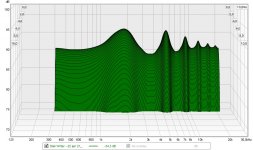
If we look at that signal in a waterfall plot, it looks like this:
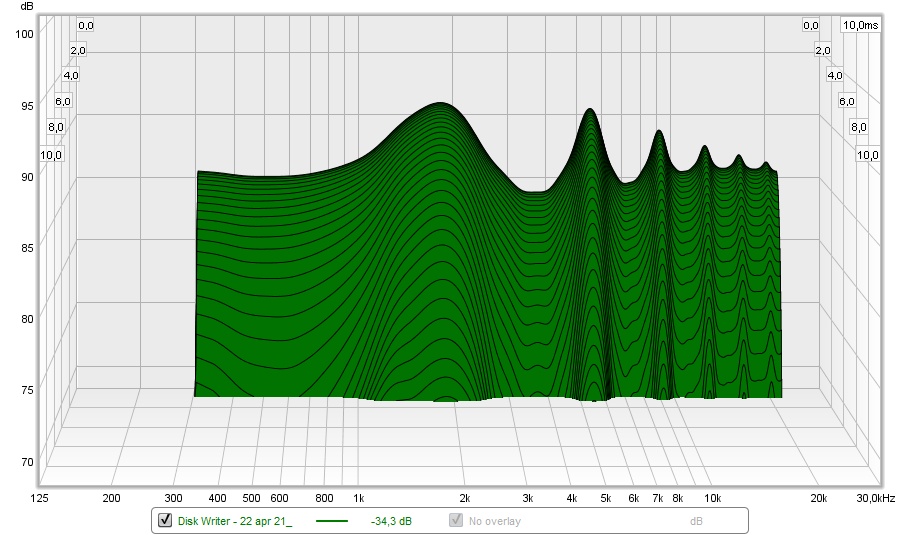
See how the signal at 1850 Hz is much wider than at ~3.7 Hz? That is the result of that "Race" of dips and peaks. It also EQ's the output, making the counter wiggles that eliminate the dips we normally hear in the exact sweet spot. That shape actually looks a lot like the mid/side EQ I was applying to my speakers. This widening and narrowing in a waterfall plot I had first seen in the plots from the phase shuffler. That made me go: what's happening here? It wasn't what I was expecting to see.
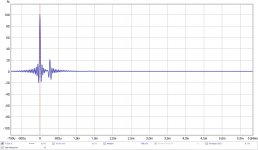
Now if we look at what happens at the ear, by summing the two signals at one ear, one main signal, as coming from the speaker on that ear's side, and the other, somewhat reduced in level because of head shading and arriving 0.27 ms later, we see this:
The first peak is like always, arriving at full strength, the second peak however (which is the opposite speaker arriving at our ear ~0.27 ms later) is largely diminished by the anti cross talk dip we had in our signal. Effectively lowering the output at our ear from the opposite side speaker.
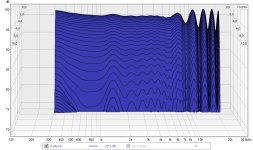
If we look at how it sums at our ear in a waterfall plot, it starts to look like this:
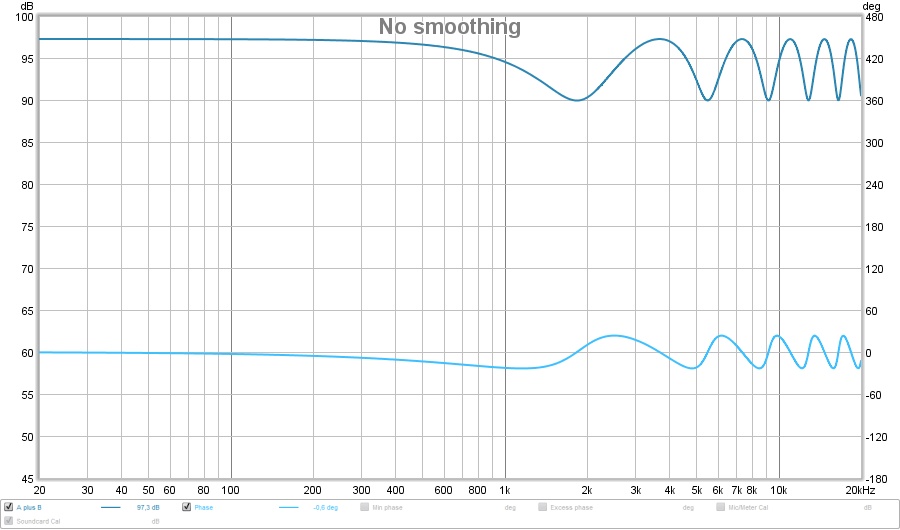
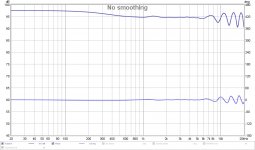
That's actually looking quite good, right? Lets look at phase and frequency:
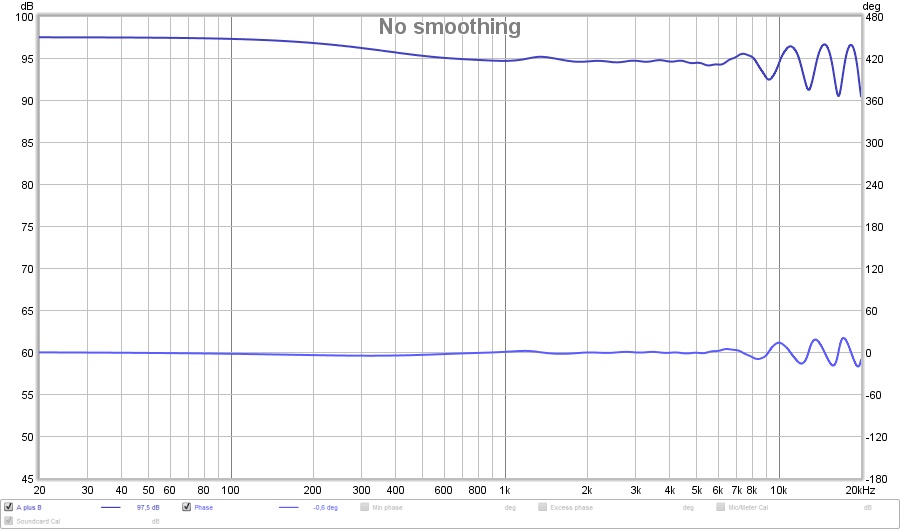
You can see in these plots I band passed my anti cross talk, as there's still wiggles showing up above ~5-6 KHz. As we go up in frequency, wave lengths become smaller and smaller, so small, even a slight movement of the head would mean we get totally different summing at those frequencies. Couple that with the fact that our head will shade way more of those higher frequencies anyway.
But it's looking quite different from the usual cross talk signal we get at our ear(s). For a reminder, let's look at how those plots look, if we account for about an 8 dB drop(*) in SPL due to head shading...
First the IR:
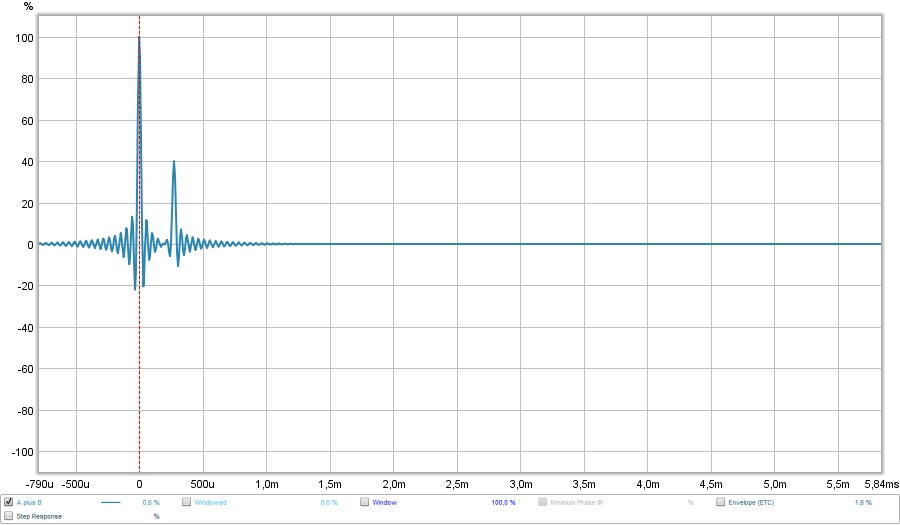
See how the second peak is about 20% higher than in our "anti cross talk" plot?
The waterfall plot, remember that both ears would get to hear this for all phantom sounds:
And the frequency/phase plot:
See how both phase and frequency are all messed up compared to the earlier graph?
The hardest part is finding out what "our" head shading does. It is clear it is more effective at higher frequencies. At ultra low frequencies the wave will be so large, our head will hardly block anything at all. So that's the next hurdle to take, adjusting the band passed signal to best suit the situation.
(*) This 8 dB of shading I used in the above example was arrived at by looking at the picture as presented by Toole of the dips caused by cross talk in a normal room. The graphs, posted on this thread by jim1961 showed a similar drop in level. He measured at (or near) ear position, both speakers playing and wrapped something fluffy to fake a head to provide some shading.
So the success of this "anti cross talk" lies in finding the right numbers needed to effectively combat the cross talk itself. The good news is that even though the first plots, those showing those peaks, look horrendous. But they don't sound bad, not even off axis. The head shading will vary with frequency, the trick will be to learn how much shading takes place.
This row of peaks and dips is adjustable in timing, level and content. So enough to keep me quite busy for a while. 😀
One last remark, a lot more work is needed than the above story, as the phantom sum, which is a simple (left + Right) sum, also contains 'left only' and 'right only' signals in this sum. To avoid upsetting the side balance, we need to subtract some of that left or right panned sounds, as those will not meet the counter acting wave front resulting in a dip. A sound coming from the side should largely remain in tact to sound it's best. As it is largely right from the start due to the placement of the speaker.
I replaced all mid/side EQ with an anti cross talk signal.
Let me explain the 'tongue in cheek' remark I made in my last post... the "race" to the finish...
In the cross talk I experience at the sweet spot in my ~30 degree stereo setup, the biggest dip is going to be somewhere around 1850 Hz. I've mentioned that a couple of times. I measured the path lengths with simple strings and also tried to find it with delayed signals. This 1850 Hz dip relates to the right ear getting the left signal about 0.272 ms after the right main wave front or pulse. And vice versa.
That was what that negative pulse I use at 0.272 ms was all about. However, if we look at the length of a signal at 1850 Hz, we notice that it takes about ~0.54 ms at that wavelength to complete a full cycle.
So the wrap around wave that travels from the left speaker into the right ear is half a wavelength behind the wave front arriving at that same ear from the right speaker. That's the cause of that dip, obviously. 😉
However, a tone that's playing at that frequency usually consists of more than one cycle. So while the left and right both are playing the tone, we get that dip consistently at both our ears when listening in the exact sweet spot.
To tune my speakers, I use about a 4 cycle length of correction in the midrange. This is because when looking at a wave shape as measured in REW, it takes about that long for the signal to reach it's maximum output. That isn't to say each tone we hear is going to take that long though...
Here's a look at the wave shape filtered at 1/3 at 2000 Hz:
Here you can see that at about the 4th cycle we reach the maximum level.
A true wave shape in a song could be either shorter or longer, however in my DRC experiments, that 4 cycle frequency dependent window is just long enough to give an effective correction, while being short enough to be "out of there" before the room takes over. Put in another way, an effective correction can be based on this length of window.
Anyway, if you have one corrective anti cross talk dip, it is only going to cure that cross talk dip partially. That negative spike is going to be heard by the other ear too!
There in lies the basics of the "Race" algorithm's used in Ambiophonics.
Basically, we use a dip at about 0.27 ms that tries to block the sound coming from the opposite speaker. Next we get a slightly lower in SPL positive spike at 0.54 ms, (remember the wavelength at 1850 Hz being 0.54 ms in length?) that counter act's the negative first spike, as that too, will travel to the other ear, after first blocking the sound from the opposite speaker. Repeated enough times, it will be so low in SPL, it won't be heard anymore.
That's a mouth full, let's see it in pictures:
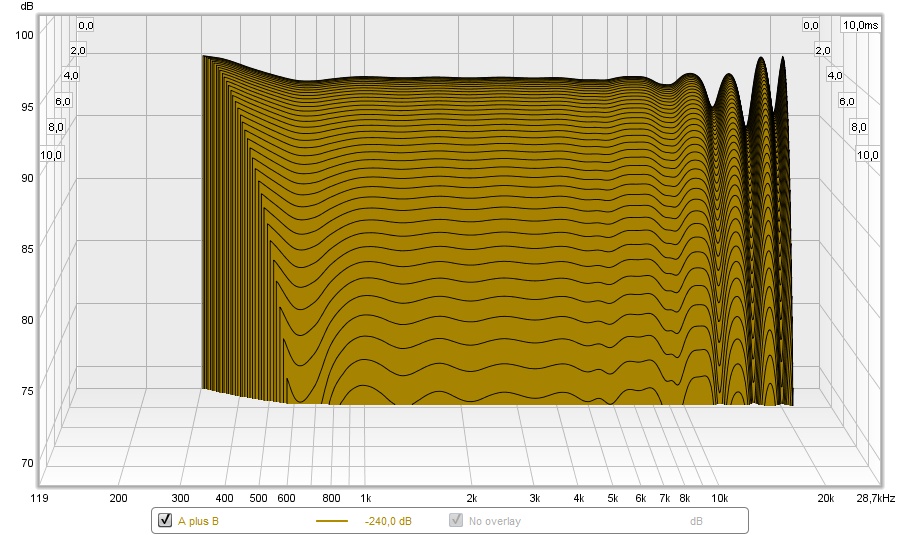
Here's the main pulse (this picture is made with an ideal Dirac pulse as a start signal) and the cross talk cancelation dips and peaks:
What we see here is that "race" algorithm, with 4 consecutive dips/peaks
If we look at that signal in a waterfall plot, it looks like this:
See how the signal at 1850 Hz is much wider than at ~3.7 Hz? That is the result of that "Race" of dips and peaks. It also EQ's the output, making the counter wiggles that eliminate the dips we normally hear in the exact sweet spot. That shape actually looks a lot like the mid/side EQ I was applying to my speakers. This widening and narrowing in a waterfall plot I had first seen in the plots from the phase shuffler. That made me go: what's happening here? It wasn't what I was expecting to see.
Now if we look at what happens at the ear, by summing the two signals at one ear, one main signal, as coming from the speaker on that ear's side, and the other, somewhat reduced in level because of head shading and arriving 0.27 ms later, we see this:
The first peak is like always, arriving at full strength, the second peak however (which is the opposite speaker arriving at our ear ~0.27 ms later) is largely diminished by the anti cross talk dip we had in our signal. Effectively lowering the output at our ear from the opposite side speaker.
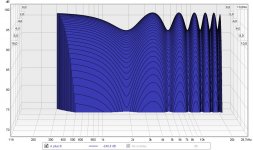
If we look at how it sums at our ear in a waterfall plot, it starts to look like this:
That's actually looking quite good, right? Lets look at phase and frequency:
You can see in these plots I band passed my anti cross talk, as there's still wiggles showing up above ~5-6 KHz. As we go up in frequency, wave lengths become smaller and smaller, so small, even a slight movement of the head would mean we get totally different summing at those frequencies. Couple that with the fact that our head will shade way more of those higher frequencies anyway.
But it's looking quite different from the usual cross talk signal we get at our ear(s). For a reminder, let's look at how those plots look, if we account for about an 8 dB drop(*) in SPL due to head shading...
First the IR:
See how the second peak is about 20% higher than in our "anti cross talk" plot?
The waterfall plot, remember that both ears would get to hear this for all phantom sounds:
And the frequency/phase plot:
See how both phase and frequency are all messed up compared to the earlier graph?
The hardest part is finding out what "our" head shading does. It is clear it is more effective at higher frequencies. At ultra low frequencies the wave will be so large, our head will hardly block anything at all. So that's the next hurdle to take, adjusting the band passed signal to best suit the situation.
(*) This 8 dB of shading I used in the above example was arrived at by looking at the picture as presented by Toole of the dips caused by cross talk in a normal room. The graphs, posted on this thread by jim1961 showed a similar drop in level. He measured at (or near) ear position, both speakers playing and wrapped something fluffy to fake a head to provide some shading.
So the success of this "anti cross talk" lies in finding the right numbers needed to effectively combat the cross talk itself. The good news is that even though the first plots, those showing those peaks, look horrendous. But they don't sound bad, not even off axis. The head shading will vary with frequency, the trick will be to learn how much shading takes place.
This row of peaks and dips is adjustable in timing, level and content. So enough to keep me quite busy for a while. 😀
One last remark, a lot more work is needed than the above story, as the phantom sum, which is a simple (left + Right) sum, also contains 'left only' and 'right only' signals in this sum. To avoid upsetting the side balance, we need to subtract some of that left or right panned sounds, as those will not meet the counter acting wave front resulting in a dip. A sound coming from the side should largely remain in tact to sound it's best. As it is largely right from the start due to the placement of the speaker.
Attachments
-
 waveshape.jpg108.8 KB · Views: 391
waveshape.jpg108.8 KB · Views: 391 -
 leftIR.jpg69.5 KB · Views: 404
leftIR.jpg69.5 KB · Views: 404 -
 waterfall.jpg151.1 KB · Views: 387
waterfall.jpg151.1 KB · Views: 387 -
 earIR.jpg68.4 KB · Views: 389
earIR.jpg68.4 KB · Views: 389 -
 Earwaterfall.jpg152.8 KB · Views: 389
Earwaterfall.jpg152.8 KB · Views: 389 -
 frequency plot at ear.jpg91.9 KB · Views: 397
frequency plot at ear.jpg91.9 KB · Views: 397 -
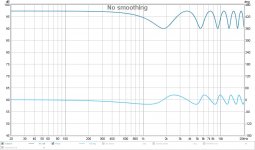 dirac x-talk.jpg97.1 KB · Views: 385
dirac x-talk.jpg97.1 KB · Views: 385 -
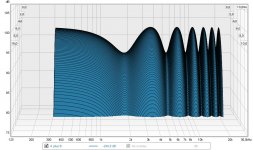 x-talk waterfall.jpg178.6 KB · Views: 384
x-talk waterfall.jpg178.6 KB · Views: 384 -
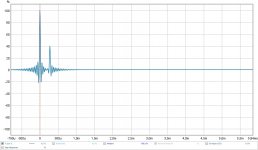 x-talkIR.jpg67.9 KB · Views: 387
x-talkIR.jpg67.9 KB · Views: 387
Last edited:
Today was a movie day for my mom and my son together. They watched Bohemian Rhapsody together, my mom being a (huge) fan since "Killer Queen" in 1974.
My son became a bigger fan due to seeing the movie.
Lots of tears flowing from sheer emotion 🙂, also in the aftermath they played some songs from CD, saved to HD (with the new anti cross talk).
Anyways they both enjoyed it very much. My son is going wild over the imaging in "The March of the Black Queen" and insisted my mom to have a listen. They ended up playing lots of songs while I had to leave for work.
All this is making my son very aware of the possibilities of Stereo listening. I think he might get as crazy about it as his dad is, at some point. We've got to create/nurture/shape the future after all 😀. He takes an interest!
My son became a bigger fan due to seeing the movie.
Lots of tears flowing from sheer emotion 🙂, also in the aftermath they played some songs from CD, saved to HD (with the new anti cross talk).
Anyways they both enjoyed it very much. My son is going wild over the imaging in "The March of the Black Queen" and insisted my mom to have a listen. They ended up playing lots of songs while I had to leave for work.
All this is making my son very aware of the possibilities of Stereo listening. I think he might get as crazy about it as his dad is, at some point. We've got to create/nurture/shape the future after all 😀. He takes an interest!
Last edited:
I'm hoping to get some measurements today, from my latest experiments. I can't promise to publish them, I might not get anything worthwhile 😉.
In theory this works very well, in practice it does not seem to disappoint either. Now I want to try and measure it, to see if it matches up and if there's room for improvement.
This isn't going to be easy though, I've got a foam ball I need to cut up and align to function as head shading. But I'll try to get something of use out of it. It's possible I may get help from my son, as he's having a school vacation.
In theory this works very well, in practice it does not seem to disappoint either. Now I want to try and measure it, to see if it matches up and if there's room for improvement.
This isn't going to be easy though, I've got a foam ball I need to cut up and align to function as head shading. But I'll try to get something of use out of it. It's possible I may get help from my son, as he's having a school vacation.
The way I see it, in Ambiophonics, where you place the left/right speaker close together, the cross talk happens at a higher frequency than in a regular 30 degree stereo setup.
However the head shading will be less in such an Ambio setup, as the sound is coming from almost straight forward.
The key I want to find is how much of an influence does head shading have (ballpark for now, as I don't measure with my actual head) and at what frequency.
In the papers from Prof. Choeiri we see the huge dips (nul) he's trying to compensate for, but also that he's cutting off the tops of those correction peaks. Trying to limit the balance change from the sound coming from the speaker.
If we have enough shading from the head within a stereo triangle, the dips are not going to be as severe as this Ambio type of setup. That would mean less of a correction would be needed, keeping it more pleasant to listen to off axis. There are several other differences though, but my main interest lies in finding just how much head shading is contributing to the results.
So far my results seem to underline this, as did the earlier mid/side EQ.
However the head shading will be less in such an Ambio setup, as the sound is coming from almost straight forward.
The key I want to find is how much of an influence does head shading have (ballpark for now, as I don't measure with my actual head) and at what frequency.
In the papers from Prof. Choeiri we see the huge dips (nul) he's trying to compensate for, but also that he's cutting off the tops of those correction peaks. Trying to limit the balance change from the sound coming from the speaker.
If we have enough shading from the head within a stereo triangle, the dips are not going to be as severe as this Ambio type of setup. That would mean less of a correction would be needed, keeping it more pleasant to listen to off axis. There are several other differences though, but my main interest lies in finding just how much head shading is contributing to the results.
So far my results seem to underline this, as did the earlier mid/side EQ.
Last edited:
I did not manage to squeeze in the measurements yet. Had some errands to run instead.
Hopefully tomorrow 🙁.
Hopefully tomorrow 🙁.
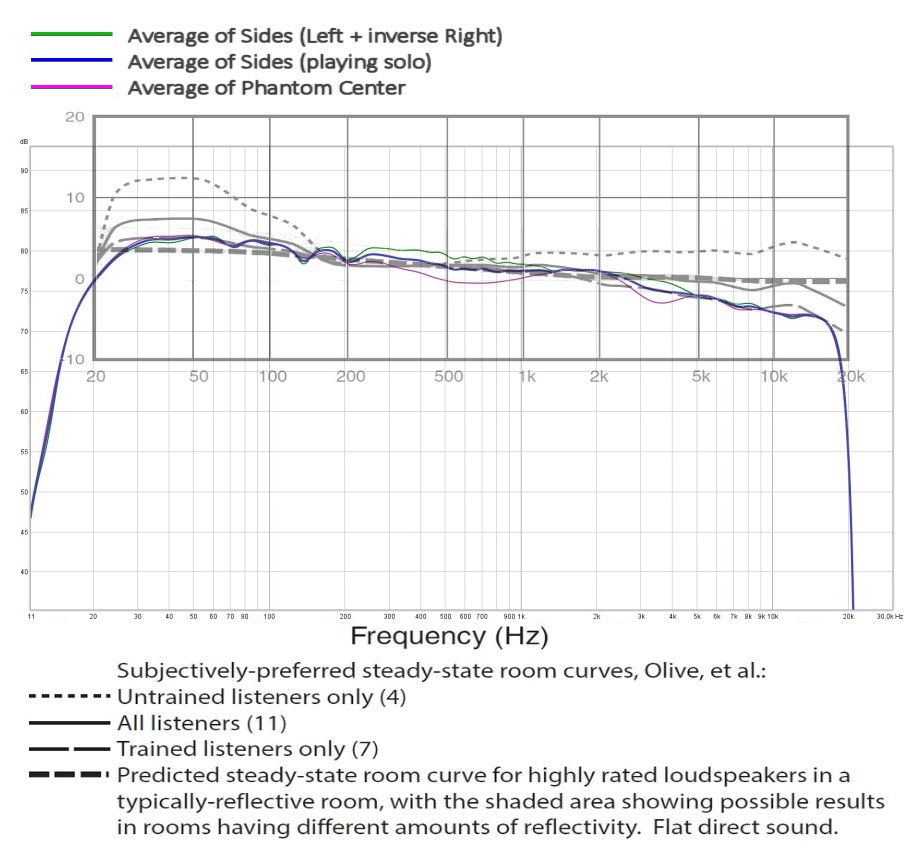
In the mean time, let's rerun this link: Sound Reproduction: The Acoustics and Psychoacoustics of Loudspeakers and Rooms - Floyd Toole - Google Books
It pretty much covers what I'm trying to say, and has been linked to before on the "Fixing the Phantom Center" Thread.
Just to show I'm not the only nutcase that found this flaw within our Stereo reproduction, for any new readers it may open up a new perspective.
It pretty much covers what I'm trying to say, and has been linked to before on the "Fixing the Phantom Center" Thread.
Just to show I'm not the only nutcase that found this flaw within our Stereo reproduction, for any new readers it may open up a new perspective.
Way too soon to draw any serious conclusions, but I managed to get some measurements of the head shading effect. I'll need way more time to set things up a bit better to get a true view of it.
Time has been in short supply so this will have to do for now:
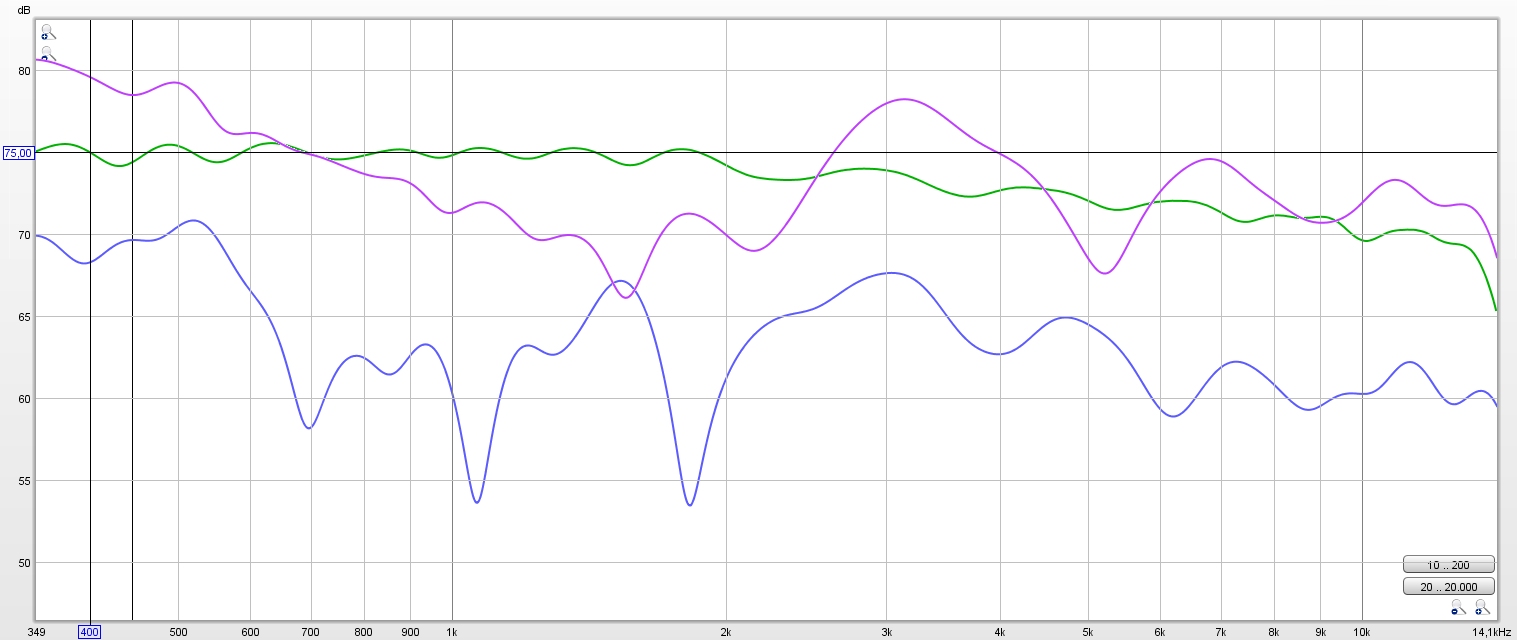
Traces were somewhat normalized (to main signal) to be able to see the differences and filtered with a 6 cycle frequency dependent window.
I use a foam ball about the size of my head with the mic flush to the outside.
I timed the IR peaks so the opposite speaker peak was about 0.27ms behind.
The green trace is the main sound at the microphone. The blue trace is the opposite speaker playing by itself, measured at the head/ball shaded mic.
The purple trace is both speakers playing as measured at the mic.
The same or at least very similar effects would happen at the other ear.
I'll include the cross talk I was using in this graph to show what it does:
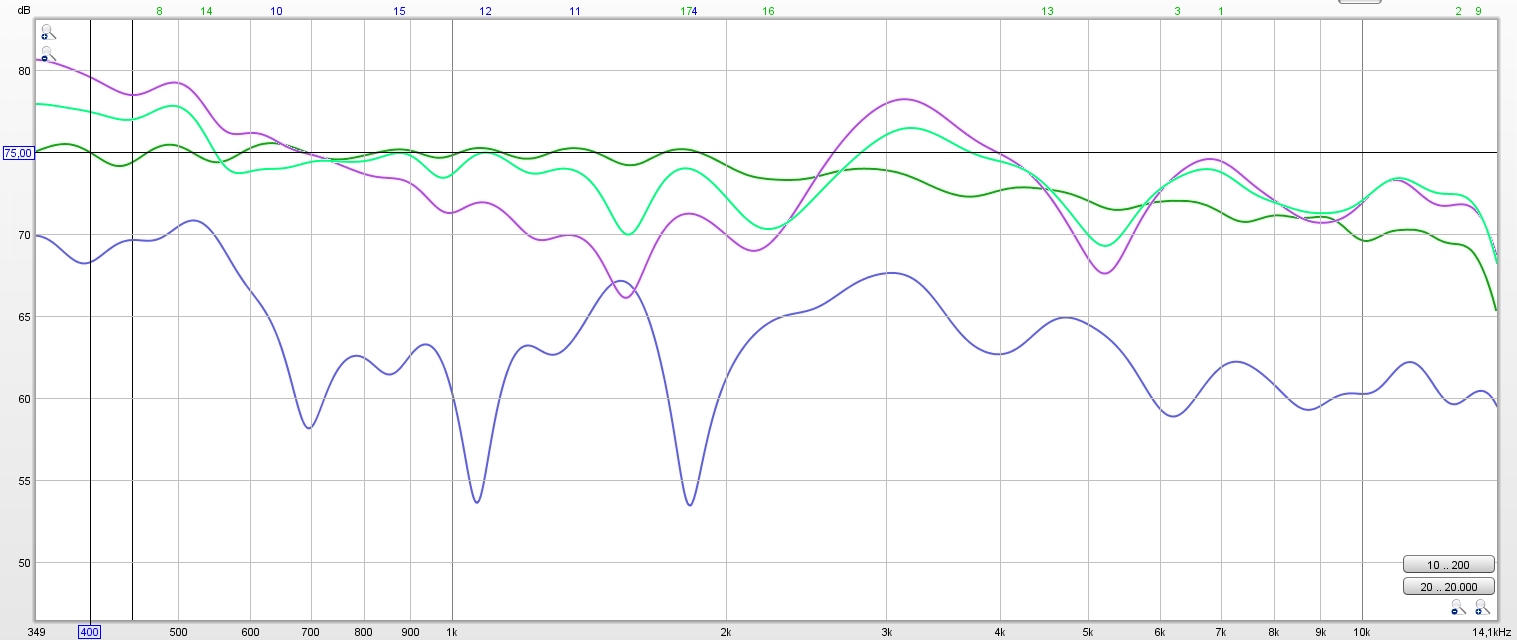
We can see it clearly does something positive, but wasn't strong enough to solve everything. What I did was change the level which seemed most pleasant to me, making my x-talk compensation about 14 dB below main level. Clearly this wasn't enough to get a flat correction, but having it louder did emphasize other frequency anomalies in real life.
What I'm thinking is that I'd need another target too, if the cross talk compensation is used to it's full extend.
I'm going to think this over, trying to determine the next steps. The cross talk compensation does work, but it's also very positional dependent.
You need to get it just right in order for it to shine.
It's quite difficult to determine the exact delay of the cross talk happening at my ears, but it seems to agree with the mid/side EQ I was using.
Due to adding sound, the total balance is different though, from my set room target. I would need to aim for the cross talk compensation balance at the ear, which means many measurements with the foam ball for both ears and a new FIR/EQ to fit. Only then I'd be able to really judge it.
The mid/side tweaks were a lot simpler but did not solve the wide dip at ~1850 Hz. I think it would make sense to go for compensation of that dip and do the rest in mid/side EQ to keep it simpler. The dip just past 5000 Hz isn't wide and would be influenced a lot by little head movements.
I have lived without much draw back with the mid/side EQ. I only noticed more sense of depth, getting some vocals more up front/free when I did try to cure that biggest dip. That has been the reason for another go at this.
Time has been in short supply so this will have to do for now:
Traces were somewhat normalized (to main signal) to be able to see the differences and filtered with a 6 cycle frequency dependent window.
I use a foam ball about the size of my head with the mic flush to the outside.
I timed the IR peaks so the opposite speaker peak was about 0.27ms behind.
The green trace is the main sound at the microphone. The blue trace is the opposite speaker playing by itself, measured at the head/ball shaded mic.
The purple trace is both speakers playing as measured at the mic.
The same or at least very similar effects would happen at the other ear.
I'll include the cross talk I was using in this graph to show what it does:
We can see it clearly does something positive, but wasn't strong enough to solve everything. What I did was change the level which seemed most pleasant to me, making my x-talk compensation about 14 dB below main level. Clearly this wasn't enough to get a flat correction, but having it louder did emphasize other frequency anomalies in real life.
What I'm thinking is that I'd need another target too, if the cross talk compensation is used to it's full extend.
I'm going to think this over, trying to determine the next steps. The cross talk compensation does work, but it's also very positional dependent.
You need to get it just right in order for it to shine.
It's quite difficult to determine the exact delay of the cross talk happening at my ears, but it seems to agree with the mid/side EQ I was using.
Due to adding sound, the total balance is different though, from my set room target. I would need to aim for the cross talk compensation balance at the ear, which means many measurements with the foam ball for both ears and a new FIR/EQ to fit. Only then I'd be able to really judge it.
The mid/side tweaks were a lot simpler but did not solve the wide dip at ~1850 Hz. I think it would make sense to go for compensation of that dip and do the rest in mid/side EQ to keep it simpler. The dip just past 5000 Hz isn't wide and would be influenced a lot by little head movements.
I have lived without much draw back with the mid/side EQ. I only noticed more sense of depth, getting some vocals more up front/free when I did try to cure that biggest dip. That has been the reason for another go at this.
Attachments
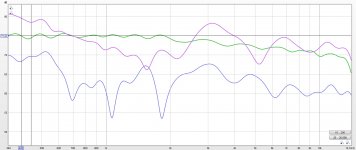
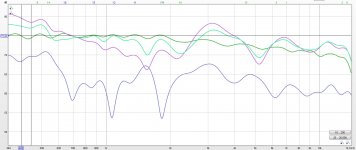
I did some further research in REW and RePhase, using an ideal case of Dirac pulses with a head shading of 11 dB on average.
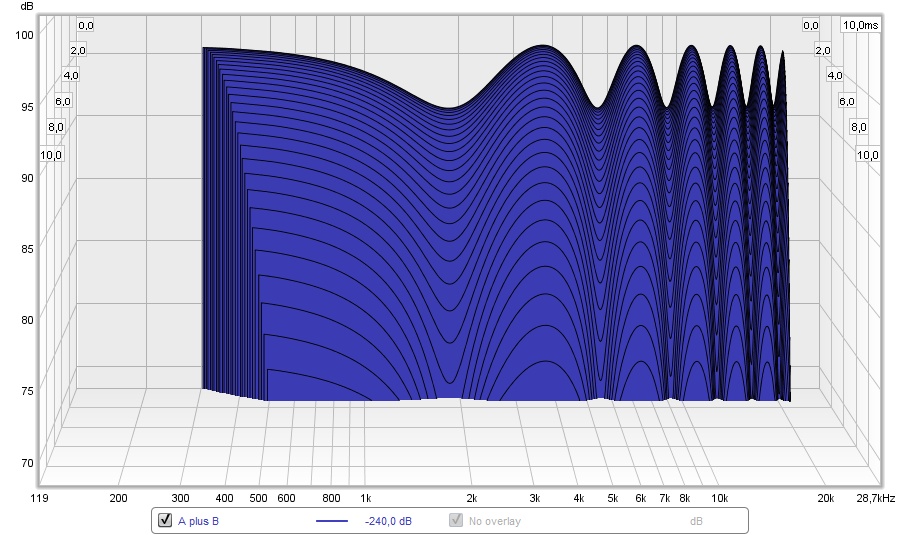
Summing these results in the wavy shape we've seen before. I took that shape and EQ-ed it back to a straight line, using minimum phase EQ. After creating a pulse of that in RePhase, I summed these with again an 11 dB of head shading.
End result: a clear straight line with straight phase.
I stopped EQ-ing just over 10 KHz, as is evident here.
This leads me to the conclusion that I don't need to include a cross talk signal, instead I can just EQ the phantom sum at the ear back to straight (or any desired target, really) and the end result will be very flat in that position.
It would be a lot less intrusive this way, even making it possible to EQ for each ear, though with the note that these measurements were made with a dummy, not my actual head 😉.
Until now I've always used linear phase EQ in my mid/side processing. This little exercise shows that was a mistake.
It also makes me wonder about the true target being used. The B&K curve comes to mind, as well as the Preferred curve from trained listeners at Harmon. I think the curve, without having cross talk in mind, should show a gentle bend. However in listening I always made it bend up at about ~1500 Hz a bit more as I preferred that in listening.
Slowly but surely things fall into place 🙂. Which still means nothing 😀.
Regular readers may remember that some time, quite a while ago I noticed a big change in perception by making that upwards bend centered at 1500 Hz.
The thing I still don't quite know is what to do with the side EQ. Should I just stick to adding mid EQ and have the sides sum as they do? Do I counter act the side part that is present in the phantom sum? That last 'logic' is what I've used so far, though I've done countless variations to "hear" how the perception of side panned sounds changed. For instance, if I roll off the side a bit more aggressive than the phantom sum, I get a more "wrap around" presentation, the stage feels more like 150 degree or even wider with some of the side material imaging way in front of the speakers. All the while wile retaining the depth feel at the sides. The hardest thing to get was to have close mic'ed vocals image closer, I've had that, but never completely "at my will" (lol). In other words, I could never play with that as I could play with the side positions.
For instance, the Shuffler, where you change the sum of left and right ear by varying the phase, tended to push vocals to the back/rear. No matter how loud you made it. The cross talk compensation did retain position or even bring it slightly closer to you.
I've got to make my mind up about how to create the FIR files too. The most captivating results have always come from one measurement position based FIR files. But the multi position method might have had an edge in overall room balance. That's proof i don't quite get the room out of the picture far enough. Which is logical by itself, it still looks like an ordinary living room 🙂.
I still think I will go back to that single point, but maybe this time by introducing that foam ball and mimic an ear position? 😱
I could even go as far as to do mid/side EQ separately for each ear!
Whatever I choose to do, it will be a lot of work, again...
Summing these results in the wavy shape we've seen before. I took that shape and EQ-ed it back to a straight line, using minimum phase EQ. After creating a pulse of that in RePhase, I summed these with again an 11 dB of head shading.
End result: a clear straight line with straight phase.
I stopped EQ-ing just over 10 KHz, as is evident here.
This leads me to the conclusion that I don't need to include a cross talk signal, instead I can just EQ the phantom sum at the ear back to straight (or any desired target, really) and the end result will be very flat in that position.
It would be a lot less intrusive this way, even making it possible to EQ for each ear, though with the note that these measurements were made with a dummy, not my actual head 😉.
Until now I've always used linear phase EQ in my mid/side processing. This little exercise shows that was a mistake.
It also makes me wonder about the true target being used. The B&K curve comes to mind, as well as the Preferred curve from trained listeners at Harmon. I think the curve, without having cross talk in mind, should show a gentle bend. However in listening I always made it bend up at about ~1500 Hz a bit more as I preferred that in listening.
Slowly but surely things fall into place 🙂. Which still means nothing 😀.
Regular readers may remember that some time, quite a while ago I noticed a big change in perception by making that upwards bend centered at 1500 Hz.
The thing I still don't quite know is what to do with the side EQ. Should I just stick to adding mid EQ and have the sides sum as they do? Do I counter act the side part that is present in the phantom sum? That last 'logic' is what I've used so far, though I've done countless variations to "hear" how the perception of side panned sounds changed. For instance, if I roll off the side a bit more aggressive than the phantom sum, I get a more "wrap around" presentation, the stage feels more like 150 degree or even wider with some of the side material imaging way in front of the speakers. All the while wile retaining the depth feel at the sides. The hardest thing to get was to have close mic'ed vocals image closer, I've had that, but never completely "at my will" (lol). In other words, I could never play with that as I could play with the side positions.
For instance, the Shuffler, where you change the sum of left and right ear by varying the phase, tended to push vocals to the back/rear. No matter how loud you made it. The cross talk compensation did retain position or even bring it slightly closer to you.
I've got to make my mind up about how to create the FIR files too. The most captivating results have always come from one measurement position based FIR files. But the multi position method might have had an edge in overall room balance. That's proof i don't quite get the room out of the picture far enough. Which is logical by itself, it still looks like an ordinary living room 🙂.
I still think I will go back to that single point, but maybe this time by introducing that foam ball and mimic an ear position? 😱
I could even go as far as to do mid/side EQ separately for each ear!
Whatever I choose to do, it will be a lot of work, again...
Attachments


Last edited:
On the BMR thread someone posted a link to this speaker: HYLIXA • Node Audio Research

When I read this quote...
a big smile appeared on my face... 🙂
I may have confessed to this before, but when trying to come up with a shape/size of my speakers I actually figured: if we're used to something, diffraction wise, it should be our own head shape and size...
So here's a sketch of a human head with a slice my speaker projected upon it:
Anyway, looks like an interesting speaker, do I see a Vifa ring radiator there?
When I read this quote...
By replicating the sonic signature of a human head, voices sound startlingly convincing; full of intent and emotion, as if the artist was in the room with you.
a big smile appeared on my face... 🙂
I may have confessed to this before, but when trying to come up with a shape/size of my speakers I actually figured: if we're used to something, diffraction wise, it should be our own head shape and size...
So here's a sketch of a human head with a slice my speaker projected upon it:
Anyway, looks like an interesting speaker, do I see a Vifa ring radiator there?
Attachments

I also saw the price of that speaker! 😱
Your speakers are more like the Coneheads! 🙂

Your speakers are more like the Coneheads! 🙂
Last edited:
- Home
- Loudspeakers
- Full Range
- The making of: The Two Towers (a 25 driver Full Range line array)