Thanks your work and sharings PMA, myself then prefer your good builded tube amp : ) but couldn't differiantate them in ABX test.
Think down the road i became aware my preference was the tube amp, it was at the time where Max Headroom made some noice i decided lookup spectrum plot for those two fruit files into Audacity and import spectrum into REW for making overlays and in that frq resonse for tube amp was shared in post 20 being about -2dB down at 20kHz it looked clear which fruit was tube amp, below graphs was using REW to divide their spectrum with each other and the red one makes most sence so that avocado is the neutral reference file.
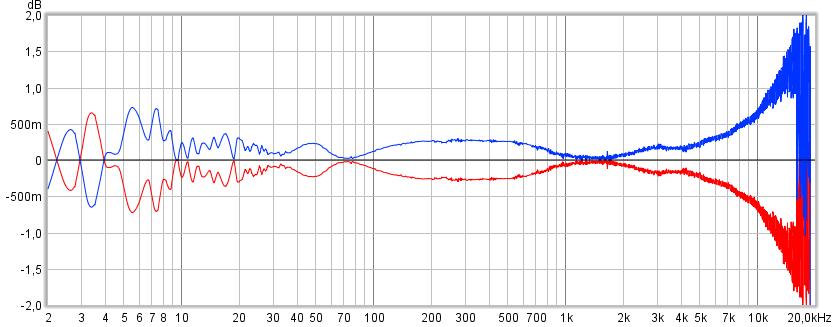
Thank you for the analysis, yes it reflects the hybrid amp amplitude response posted at
Can you tell original file from tube amp record? - test
Yes.
Cumulative probability:
P(X > x) 0.04935036366
We have the same maths.
I am not an expert on test procedures, so is it possible to take results of 8 different people and make a simple sum of trials, to get the final probability of guessing?
Actually there is a slight difference, as it is not "X>x" but "X >= x" .
Sometimes it feels like wasting a lot of time as i explained that in an answer to your questions before (as usual zero response as with other recent explanations, lately even asking for a follow-up fails) .
The important point is the premise "under the assumption that the null hypothesis is true" (H0 = 0.5) .
That is the common misconception with the usual analysis of this kind of tests (didn´t i mention it already in this thread?), we don´t "get the final probability of guessing" but we just calculate the probability for the observed data _under_ the _assumption_ that the participants were randomly guessing.
Obviously this analysis breaks down, if the participants are _not_randomly guessing, which in fact is the reason why we can´t conclude that our null hypothesis is true, if we observe negative results.
All we are doing is to evaluate if the observed data is compatible to our null-hypothesis; we don´t really examine _if_ the null-hypothesis _is_ true.
@Jakob2: Thank you for being patient with my terminology inaccuracies. So, can I conclude, that, based on member's ABX reports posted (and assuming there were no other ABX trials of the same members remaining unpublished), we may say that a sum of the members was able to tell the difference? Or, in another way, what would be your conclusion from the results posted. Thank you.
...Apricot is the file that was recorded through the open-loop hybrid tube-SS power amplifier, with transistor class A unity gain output stage.
Avocado is the original CD rip.
Again, a new test passed thanks to avoid the use of foobar2000 and the ABX plugin.
Can you tell original file from tube amp record? - test
And with speakers and not with my tweaked and very cheap open dynamic headphones Takstar ts671 (cheap but very good sound, with more bass and more clean sound after the tweak -not only the cable).PC -> ODAC -> AV Marantz SR4500 -> KEF Q100, all tweaked
Win 10 Pro 1709 64 bits, very optimized to play multimedia.
J River MC 64 bits, Kernel Streaming
The best sound is Apricot. More natural, credible but not perfect. The double bass rumbles too much. Voice is credible, sweet.
The original must be Avocato. More thin sound. Double bass with less rumble. Voice more clear but less credible to me. Lifeless.
Apricot with with lower level harmonics would sound better.
Off topic,
Off course, a very good (and cheap) starquad cable and Neutrik jack. Van Damme Tour Grade Classic XKE microphone cable.
Off course, a very good (and cheap) starquad cable and Neutrik jack. Van Damme Tour Grade Classic XKE microphone cable.
I have read this about Direct Sound, vade retro satana.
They have detected clicks problems/noise with the new dac + headphone Topping DX3Pro:
Review and Measurements of Topping DX3Pro DAC and Headphone Amp | Page 35 | Audio Science Review (ASR) Forum
They have detected clicks problems/noise with the new dac + headphone Topping DX3Pro:
Review and Measurements of Topping DX3Pro DAC and Headphone Amp | Page 35 | Audio Science Review (ASR) Forum
Again, vade retro.Yes with DS: Primary Sound Driver in foobar2000 and in browsers relay cliсks also present, problem not in ASIO or WASAPI.
I hope there will be a new firmware with fix.
Maty, you aren't adding anything to the discussion. Since we have have no way to know that you've picked the files blind, none of what you post has any value in this thread.
I also hear differences - or think I do - until put to the test.
I also hear differences - or think I do - until put to the test.
even though there's arguably not enough data points to analyze it statistically i'm wondering why more people thought that Apricot was the original?
on a subjective level i drew a conclusion that Avacado was the "tube" version, was my thinking influenced by the mantra of "tubes are warm sounding"?
on a subjective level i drew a conclusion that Avacado was the "tube" version, was my thinking influenced by the mantra of "tubes are warm sounding"?
Last edited:
You are wrong. I have write many times that foobar2000 has problems with the ABX plugin. And it is a bad player to enjoy the music too. Only as a tool and to play ISO (thanks to the SACD plugin that is very very good).
I DO NOT TRUST IN FOOBAR2000 like a player.
foobar2000 (32 bits), Kernel streaming
Apricot sounds worse than before (JRMC).
Avocado sounds a little better than Apricot.
Again, JRMC is better player in my system. foobar2000 like a tool and to play ISO.
I DO NOT TRUST IN FOOBAR2000 like a player.
because the sample size is too smalli'm wondering why more people thought that Apricot was the original?
Could it be that they thought it was the original because they preferred it? That's what I probably did.
Why not? There is no hum or noises or something from what to tell. Only the sine test makes clear what is the original.
No, no I'm not.You are wrong.
I have write many times that foobar2000 has problems with the ABX plugin
Yes Maty, we know, we know. But you have no proof of it.
Years ago I did a test of audio transfer from a WIN XP laptop to another Win XP laptop. The signal path was USB>SPDIF -- SPDIF>USB. The transfers were bit perfect at at 44.1 and at 48 kHz. What more can you ask for than bit perfect? It didn't matter which player was used. Now if you want to use DSP in your player, that could make a difference. Otherwise I could not find one any fault. Not 1 bit in many millions
If you suspect something wrong with the Foobar ABX plugin, please investigate and find proof. It can't be that difficult to find - you know your way around computer audio. Providing proof of a flaw would be useful to everyone. Unless you can do that, it just hand waving.
Maty's rant about Foobar would that explain why the "sine" files where indistinguishable to me?
any other ABX software i could try? cause like Scott alluded to earlier if i can't hear a difference i should go see my audiologist!
any other ABX software i could try? cause like Scott alluded to earlier if i can't hear a difference i should go see my audiologist!
Easy question:
The people who have liked Avocado can specify:
* Soft player and OS
* If Win, Output mode?
Btw, I used Kernel Streaming in JRMC and foobar2000 to make the test. Why?
http://jplay.eu/forum/index.php?/topic/1143-why-kernel-streaming/#entry18613
The people who have liked Avocado can specify:
* Soft player and OS
* If Win, Output mode?
Btw, I used Kernel Streaming in JRMC and foobar2000 to make the test. Why?
http://jplay.eu/forum/index.php?/topic/1143-why-kernel-streaming/#entry18613
Kernel Streaming is lowest 'audio' layer in Windows: Why go through more layers (=WASAPI) if direct access is possible? In audio, less is usually more. (unlike WASAPI, ASIO _can_ be direct although it's not a given: there are 'ASIO' drivers out there which are using KS internally…) KS also allows for things that WASAPI does not: whereas both ASIO & WASAPI require memory copy operation per design, KS does not. Again, less is more. ASIO usually has _fixed_ Buffer size – it has been established from experience that various Buffer sizes can have sonic impact with smaller values sounding 'better' for most. Not being able to manipulate Buffer size is a clear restriction for ASIO. In addition, ASIO may require even more memory copy operations then WASAPI as it expects left & right channel to be 'separated' (WAV format has samples interleaved). WASAPI allows for different Buffer sizes but requires certain 'minimal' size – Usually this is 192/256 samples for CD and 512+ for HiRez. One cannot go below that minimum. Kernel streaming, on the other had, has no such restrictions: one can even use Buffer of a single sample! ('DirectLink' as unique feature of JPLAY) Hopefully this makes it clear now why we recommend KS: Lowest layer, no restrictions on Buffer size, zero-copy scenarios possible. Again, we believe 'less is more': not everyone agrees this makes a sonic difference and that is ok – but it does not change the factsWhy JRiver (=Matt) does not recommend KS is something you will have to ask him: links you posted do not have a single reason mentioned.
Not likely until he provides some proof. See my post above.Maty's rant about Foobar would that explain why the "sine" files where indistinguishable to me?
There used to be a Java player called HQ that had an ABX plugin. Long gone, I thinkany other ABX software i could try?
I don't think so. Those hearing it may have an advantage of playback gear with a peak at 2K. Certainly the case for Grado headphones. That could push H2 up by as much as 10dB. Remember, H2 is 48dB below the 1K fundamental. One would expect it to be masked. Or it could just be our playback equipment has too much distortion. I suspect that mine does. Time to measure it.cause like Scott alluded to earlier if i can't hear a difference i should go see my audiologist!
That's certainly a possibility, I will attempt to measure that peak....with my Panasonic WM61a mic and oscilloscope, best I can do.
Those hearing it may have an advantage of playback gear with a peak at 2K. Certainly the case for Grado headphones. That could push H2 up by as much as 10dB. Remember, H2 is 48dB below the 1K fundamental. One would expect it to be masked. Or it could just be our playback equipment has too much distortion. I suspect that mine does. Time to measure it.
I do not agree. H2 is 43 - 44dB below fundamental. THD = 0.64%. This is audible, for 1kHz tone. I am attaching the spectrum again and the thresholds as well. For 60dB SPL, audibility threshold for 1kHz is 0.2%. Try again at proper level with reasonable headphones. I do not think that Grado elevates the H2. Remember if the headphones have H2 of some 0.5%, the test would not pass. If SPL is too high or too low the test would not pass as well. I know you mean rather freq. resp. peak.
Attachments

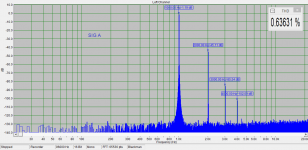
That's certainly a possibility, I will attempt to measure that peak....with my Panasonic WM61a mic and oscilloscope, best I can do.
This will be difficult to measure.
- Home
- General Interest
- Everything Else
- Can you tell original file from tube amp record? - test