To further complicate things, we don't hear alike. Some are capable of detecting smaller differencies than others. This can be tested and hearing-evaluation can be trained! Dr. Sean Olive, chief of Harman Inc. R&D Acoustic research, has done lots of studies
Audio Musings by Sean Olive: Harman's "How to Listen" - A New Computer-based Listener Training Program
http://www.aes.org/tmpFiles/elib/20141026/12206.pdf
AES E-Library Differences in Performance and Preference of Trained versus Untrained Listeners in Loudspeaker Tests: A Case Study
http://web.arch.usyd.edu.au/~wmar0109/DESC9090/old/BechZach_doc/115_Tutorials/5%20Listening%20Test%20Workshop_Listener%20Training%20(Olive).pdf
Harman Innovation Hub | The Science and Marketing of Sound Quality
Audio Musings by Sean Olive: Harman's "How to Listen" - A New Computer-based Listener Training Program
http://www.aes.org/tmpFiles/elib/20141026/12206.pdf
AES E-Library Differences in Performance and Preference of Trained versus Untrained Listeners in Loudspeaker Tests: A Case Study
http://web.arch.usyd.edu.au/~wmar0109/DESC9090/old/BechZach_doc/115_Tutorials/5%20Listening%20Test%20Workshop_Listener%20Training%20(Olive).pdf
Harman Innovation Hub | The Science and Marketing of Sound Quality
I forgot to mention an interesting thesis about the binaural decoloration :
http://repository.tudelft.nl/assets/uuid:7f0331e3-bc1a-4d7f-8d2a-eb5d6cc04fbf/as_salomons_19951220.PDF
I think that the presented experiments adding electronic signals are sometimes a bit "crude" : the coloration is allways worse than in experiments adding signals acoustically.
But the comparison between diotic and dichotic situations is very interesting and can explain why some kind of reflections are much less audible than others.
http://repository.tudelft.nl/assets/uuid:7f0331e3-bc1a-4d7f-8d2a-eb5d6cc04fbf/as_salomons_19951220.PDF
I think that the presented experiments adding electronic signals are sometimes a bit "crude" : the coloration is allways worse than in experiments adding signals acoustically.
But the comparison between diotic and dichotic situations is very interesting and can explain why some kind of reflections are much less audible than others.
jlo
I know that I should actually read that thesis, but I am too lazy (and too busy, but that's just a cop-out.) Could you summarize for me. What is diotic and dichotic situations? My dictionary says that there is no such word as diotic.
If I could express a suggestion, when someone mentions a piece of research, its fundamental conclusions should always be mentioned. Then if a reader wants further details he or she knows where to go for further clarification.
I know that I should actually read that thesis, but I am too lazy (and too busy, but that's just a cop-out.) Could you summarize for me. What is diotic and dichotic situations? My dictionary says that there is no such word as diotic.
If I could express a suggestion, when someone mentions a piece of research, its fundamental conclusions should always be mentioned. Then if a reader wants further details he or she knows where to go for further clarification.
To further complicate things, we don't hear alike. Some are capable of detecting smaller differencies than others. This can be tested and hearing-evaluation can be trained! Dr. Sean Olive, chief of Harman Inc. R&D Acoustic research, has done lots of studies.
I sat through an Olive paper and a Toole paper at the LA AES and they made a point of saying that trained listeneres would give a wider range of scores (higher highs and lower lows) and greater consistency and speed, but that all groups would give the same rank ordering of tested systems (headphones or speakers).
Yes, I noticed only one exception to that. Hifi-addicts have many vague terms to decribe sound of speakers, if the criteria are not harmonized, discussion is pointless - this happens often at these forums. It was also noted that rapid changes between speakers makes it easier to detect differencies.
It would be interesting to see a study of same set of speakers evaluated in different rooms, with also room curves measured in addition to direct sound. Would the rank order still be same?
It would be interesting to see a study of same set of speakers evaluated in different rooms, with also room curves measured in addition to direct sound. Would the rank order still be same?
Last edited:
I am too lazy (and too busy, but that's just a cop-out.) Could you summarize for me. What is diotic and dichotic situations? My dictionary says that there is no such word as diotic.
Diotic means that the same stimuli is present at both ears, dichotic means that stimuli is different between ears.
You're right but I was too lazy to write a summary !If I could express a suggestion, when someone mentions a piece of research, its fundamental conclusions should always be mentioned. Then if a reader wants further details he or she knows where to go for further clarification.
In a few words :
this thesis is about coloration due to reflections and decoloration from binaural hearing.
As studies about binaural hearing are mainly focused on localization, we can read here about a less well known side of binaurality : decoloration.
Study of threshold of audibility with various signals in diotic and dichotic situations, and also monaural (one ear), clearly states that when the signal is dichotic (different at both ears), the coloration is less audible than when the coloured signal is the same at both ears.
This is coherent to the fact that floor and ceiling reflections are more audible than side reflections.
There are also comparisons with monaural listening and everyone can easily do a listening test with one ear closed : the room coloration from reflections is more audible than while listening with both ears.
speaker dave; said:But your arguement was that the mixers are moving and so they can ignore the reflection. Toole is saying that the stationary effects are ignored (room) and the variable effects stand out (loudspeaker), quite the opposite.
- if you consider that your head doesn't move, what varies is the acoustical signal, with the room reflections not varying
- but if you move your head (small movements of the head being a known cue for source localization and front/back discrimination), the reflections also change between the ears and become more or less the variable part.
Last edited:
Diotic means that the same stimuli is present at both ears, dichotic means that stimuli is different between ears.
You're right but I was too lazy to write a summary !
In a few words :
Thanks, that helps. So one might also take away from this that a reflection off a far wall to the ear opposite the direct signal is likely to be less colored than a reflection off the near wall where the direct and reflected signals mix external to the ear and coloration cannot be removed cognitively. I have long held this to be true and why high directivity is so important - to avoid the near wall reflection.
jlo
...... What is diotic and dichotic situations? My dictionary says that there is no such word as diotic.
.....
QUOTE]
You have go to be kidding. This is standard stuff for anyone even remotely interested in psychoacoustics. I am surprised, really.
Perhaps folks involved in electroacoustics / consumer audio should take a course in "Hearing 101". It might be an eye-opener.
Really!? Are you kidding? That's sinking pretty low.
No I am not. You frequently tell us you are involved in psychoacoustics, but you are unaware of standard terminology. This does not add up.
As studies about binaural hearing are mainly focused on localization, we can read here about a less well known side of binaurality : decoloration.
Study of threshold of audibility with various signals in diotic and dichotic situations, and also monaural (one ear), clearly states that when the signal is dichotic (different at both ears), the coloration is less audible than when the coloured signal is the same at both ears.
This is coherent to the fact that floor and ceiling reflections are more audible than side reflections.
I'd say the explanation is this. Your brain doesn't have any data basis for discriminating colourations from direct sound with one ear, since it just gets a single sound stream from wherever. With stereo listening, it has the data and can "learn" the room and adjust perceptions accordingly.
Ben
Last edited:
Hi jlo
I have been thinking about MMM and now conclude that there is a unique situation where the direct field is enhanced in these measurements.
Consider that the results that we obtain have to be independent of the signal that we use to obtain them - it is a linear and time-invariant system. So instead of thinking about measuring noise, think about measuring impulses. If we measure impulses at several locations and average them then different things can happen depending on the distances from the source to the mic. If these distances vary at the measurement points then the direct response will average down proportional to 1/N (but not completely of course) just as the reverberant field will. BUT, if the distance from the source to the microphone is maintained at a constant distance and the angle off axis of the speaker is not too large then the direct response impulse will actually not average down, it will remain constant while the reverberation field will average down as 1/N to the steady state level. Thus the direct field is enhanced in this measurement.
This difference is identical to normal averaging versus synchronous averaging in an FFT. If the mic sweep plane's normal points to the speaker and is basically on axis then the direct impulses will be nearly identical and in synch, but the reflections etc. will not. Hence, the direct field is enhanced in this measurement, but only in this unique measurement, all others sweep planes will not enhance the direct signal.
One could also synch the impulse responses at individual points before averaging.
I have been thinking about MMM and now conclude that there is a unique situation where the direct field is enhanced in these measurements.
Consider that the results that we obtain have to be independent of the signal that we use to obtain them - it is a linear and time-invariant system. So instead of thinking about measuring noise, think about measuring impulses. If we measure impulses at several locations and average them then different things can happen depending on the distances from the source to the mic. If these distances vary at the measurement points then the direct response will average down proportional to 1/N (but not completely of course) just as the reverberant field will. BUT, if the distance from the source to the microphone is maintained at a constant distance and the angle off axis of the speaker is not too large then the direct response impulse will actually not average down, it will remain constant while the reverberation field will average down as 1/N to the steady state level. Thus the direct field is enhanced in this measurement.
This difference is identical to normal averaging versus synchronous averaging in an FFT. If the mic sweep plane's normal points to the speaker and is basically on axis then the direct impulses will be nearly identical and in synch, but the reflections etc. will not. Hence, the direct field is enhanced in this measurement, but only in this unique measurement, all others sweep planes will not enhance the direct signal.
One could also synch the impulse responses at individual points before averaging.
Whether we listen to mono with one source or two we still are listening binaurally. I think the best analogy is with the eyes eg if we jam an earplug in either ear while listening to a mono source beit a single point or two can we still percieve depth and time? Are we effectively depraved of depth perception like with single sighted vision? I think yes and thus voice speakers in mono from a single source. Stereo is fluff and icing on the cake often times masking underlying problems.I'd say the explanation is this. Your brain doesn't have any data basis for discriminating colourations from direct sound with one ear, since it just gets a single sound stream from wherever. With stereo listening, it has the data and can "learn" the room and adjust perceptions accordingly.
Ben
From the moment we first hear, our entire lifetime has been learning. We have that stored knowledge ready for fight or flight response. Now the finer degrees of hearing perception is variable amounst us all. I would trust Earls ear as much as my own as our experiences are similar enough. I do actually listen to live symphonic music and as good and bad as it can be HS band... no choice, they're nextdoor!
Hi jlo
I have been thinking about MMM and now conclude that there is a unique situation where the direct field is enhanced in these measurements.
Consider that the results that we obtain have to be independent of the signal that we use to obtain them - it is a linear and time-invariant system. So instead of thinking about measuring noise, think about measuring impulses. If we measure impulses at several locations and average them then different things can happen depending on the distances from the source to the mic. If these distances vary at the measurement points then the direct response will average down proportional to 1/N (but not completely of course) just as the reverberant field will. BUT, if the distance from the source to the microphone is maintained at a constant distance and the angle off axis of the speaker is not too large then the direct response impulse will actually not average down, it will remain constant while the reverberation field will average down as 1/N to the steady state level. Thus the direct field is enhanced in this measurement.
This difference is identical to normal averaging versus synchronous averaging in an FFT. If the mic sweep plane's normal points to the speaker and is basically on axis then the direct impulses will be nearly identical and in synch, but the reflections etc. will not. Hence, the direct field is enhanced in this measurement, but only in this unique measurement, all others sweep planes will not enhance the direct signal.
Hi Earl
Just checking for understanding, if we measure along the red line (which is 10 degrees to the left and the right in this example) the direct field in the measurement is enhanced? If yes, by how much?
One could also synch the impulse responses at individual points before averaging.
You mean measure at random spatial points and zero out the impulse response delays before averaging?
Attachments
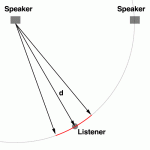
By how much? I have no idea. Clearly it depends on the number of averages.
Yes zero out any time differences before averaging.
I would think that you would want to turn the speaker so that it points to the measuring area because most speakers are their smoothest spatially towards the listening axis.
Yes zero out any time differences before averaging.
I would think that you would want to turn the speaker so that it points to the measuring area because most speakers are their smoothest spatially towards the listening axis.
We see depth perfectly well with one eye. Haven't you noticed this? It always comes as a surprise to persons from engineering to learn that the stereopsis cue is actually low in the "trust me" hierarchy despite the math certainty of it.Whether we listen to mono with one source or two we still are listening binaurally. I think the best analogy is with the eyes eg if we jam an earplug in either ear while listening to a mono source beit a single point or two can we still percieve depth and time? Are we effectively depraved of depth perception like with single sighted vision? I think yes and thus voice speakers in mono from a single source. Stereo is fluff and icing on the cake often times masking underlying problems.
From the moment we first hear, our entire lifetime has been learning. We have that stored knowledge ready for fight or flight response. !
We also have some degree of spatial localization (mostly direction) with one ear. I know this because I volunteered for just that kind of experiment at the University of Chicago in 1961.
I can't say what hearing knowledge is learned in childhood or if some aspect of that is anything but a hindrance to enjoying a stereo music which is, after all, just an illusion. We are talking about things like "learning" a room after you walk into it and "learning" your music room as you listen to music in it.
Stereo records are indeed fluff. They are stimuli contrived by manipulating available cues (loudness, timbre, timing...) to give people a sense of spatial location. Sadly, (1) not all the cues that contribute to spatial localization are available to the recording engineer (or that he/she would know what to do with them if they were) and (2) on coming out of the loudspeakers in your room, there will be many other cues which ALWAYS conflict with the desired illusion (and hence, diminish the illusion).
Ben
Last edited:
Thanks Earl, this is very interesting, I appreciate the idea.Consider that the results that we obtain have to be independent of the signal that we use to obtain them - it is a linear and time-invariant system. So instead of thinking about measuring noise, think about measuring impulses. If we measure impulses at several locations and average them then different things can happen depending on the distances from the source to the mic. If these distances vary at the measurement points then the direct response will average down proportional to 1/N (but not completely of course) just as the reverberant field will. BUT, if the distance from the source to the microphone is maintained at a constant distance and the angle off axis of the speaker is not too large then the direct response impulse will actually not average down, it will remain constant while the reverberation field will average down as 1/N to the steady state level. Thus the direct field is enhanced in this measurement.
This difference is identical to normal averaging versus synchronous averaging in an FFT. If the mic sweep plane's normal points to the speaker and is basically on axis then the direct impulses will be nearly identical and in synch, but the reflections etc. will not. Hence, the direct field is enhanced in this measurement, but only in this unique measurement, all others sweep planes will not enhance the direct signal.
One could also synch the impulse responses at individual points before averaging.
The following methods give me same results :
- with log sine sweeps, get the impulses, do FFT and an average the spectrums
- with log sine sweeps, get the impulses, average the aligned impulses (must do a bit of process and get rid of min/max values at each sample) and do FFT
- with MMM : record the noise, do an FFT of the whole recording and filter at -3dB/oct
In no case, my sweep plane is kept constantly normal to the axis of the speaker but I really have to think about your idea.
Last edited:
- with log sine sweeps, get the impulses, average the aligned impulses (must do a bit of process and get rid of min/max values at each sample) and do FFT
If this gives the same result as non-aligned impulses then my idea doesn't work. Not sure what "must do a bit of process and get rid of min/max values at each sample" means.
If the impulse are aligned but the reflections are random you should get a different result than if the impulses and the reflections are random. Not sure why you didn't. Maybe you processed away the differences?
No it only works with aligned impulses. So your idea is still valid.If this gives the same result as non-aligned impulses then my idea doesn't work
In fact, normally I only used the standard way : log sine sweep, FFT of each IR and then average of spectrums.Not sure what "must do a bit of process and get rid of min/max values at each sample" means.
But as I also wanted to get an average phase (because spectrum averaging or MMM do not give phase), I tried following : log sine sweep, recover each IR, align IRs, average IRs and do an FFT from the average IR.
But as I wanted to smooth out a bit the IR average, I "cleaned" by removing at each sample the max and min values (ie at sample nr 1234, get rid of the global max and min of all N IR and average by N-2) . It is certainly not an elegant solution but it gave me a smoother phase response, easier to analyze.
Hi jlo
I have been thinking about MMM and now conclude that there is a unique situation where the direct field is enhanced in these measurements.
Consider that the results that we obtain have to be independent of the signal that we use to obtain them - it is a linear and time-invariant system. So instead of thinking about measuring noise, think about measuring impulses. If we measure impulses at several locations and average them then different things can happen depending on the distances from the source to the mic. If these distances vary at the measurement points then the direct response will average down proportional to 1/N (but not completely of course) just as the reverberant field will. BUT, if the distance from the source to the microphone is maintained at a constant distance and the angle off axis of the speaker is not too large then the direct response impulse will actually not average down, it will remain constant while the reverberation field will average down as 1/N to the steady state level. Thus the direct field is enhanced in this measurement.
This difference is identical to normal averaging versus synchronous averaging in an FFT. If the mic sweep plane's normal points to the speaker and is basically on axis then the direct impulses will be nearly identical and in synch, but the reflections etc. will not. Hence, the direct field is enhanced in this measurement, but only in this unique measurement, all others sweep planes will not enhance the direct signal.
One could also synch the impulse responses at individual points before averaging.
I really don't think this works at all. You are trying to make something analogous to time averaging and defining the direct sound as synchronous and the reverberant field as random noise.
In practice your system will not remain time coherent at multiple angles, even if you keep a constant distance from system to mic. The acoustic center of the speaker is not a compact point, so coherence will drift. If you stay on a horizontal plane (assuming the elements are vertically displaced) you will still have problems as the high frequency phase shift as you move off axis will add delay. The woofer and tweeter may have different effective depths so you can't keep a constant distance from both.
I have tried time synchronous averages when the timing could not be well maintained and the HF loss is considerable.
We also have to assume that the reverberant field is random (unrelated from point to point) It may be at high frequencies, but I'm not so sure about low frequencies. The SNR gain of time averaging is 3dB for every 2 to the n samples increase. How many samples can you take before the HF coherence between measurements is lost? What Direct to Reflected improvement would come from that?
Anyhow, the Direct to Reflected energy mix is not about signal vs. noise, rather early vs. late of a repeating waveform (the impulse response of a room is repeatable, late energy is not noise). This is an inappropriate application of time averaging.
Before you start squawking about how wrong I am, how about a trial measurement?
David
- Home
- Loudspeakers
- Multi-Way
- Moving Mic Measurement