Wesayso,
I guess if all you are going by is some old reference material that was created in the 1950's about the problems of those early line arrays you would believe that what you are doing can't work. But the approach you have taken and the advances in processing have made what you are now doing practical and actually functional where the early work was so flawed in so many respects that we really aren't talking about the same thing anymore. Most Pro-audio systems today in large venues are line arrays even if they are curved arrays with steering when used. We have come a long way from the early straight limited bandwidth arrays of the 50's in the AES journals.
Keep up the great work. Lines may not be for everyone just because of there size but you have shown many of us that they are indeed a practical solution that can be made to work well at a very high level.
Steven
I guess if all you are going by is some old reference material that was created in the 1950's about the problems of those early line arrays you would believe that what you are doing can't work. But the approach you have taken and the advances in processing have made what you are now doing practical and actually functional where the early work was so flawed in so many respects that we really aren't talking about the same thing anymore. Most Pro-audio systems today in large venues are line arrays even if they are curved arrays with steering when used. We have come a long way from the early straight limited bandwidth arrays of the 50's in the AES journals.
Keep up the great work. Lines may not be for everyone just because of there size but you have shown many of us that they are indeed a practical solution that can be made to work well at a very high level.
Steven
Last edited:
Thanks, Derek, perceval and Steven...
I'll continue with my regular scheduled program again, it seems the biggest storm is over 😛.
Still playing with phase shuffling, oddly enough it does seem to be very effective at brightening up the phantom center without additional EQ.
Sadly it will be a while before I have the house fully to myself again. I'll have to sneak in a few listening sessions.
I'll quote myself from another thread to show an easy way to merge FIR corrections (with a thank you to Barleywater for the basic idea):
The beauty is this merges two stereo FIR files without much work.
I'll continue with my regular scheduled program again, it seems the biggest storm is over 😛.
Still playing with phase shuffling, oddly enough it does seem to be very effective at brightening up the phantom center without additional EQ.
Sadly it will be a while before I have the house fully to myself again. I'll have to sneak in a few listening sessions.
I'll quote myself from another thread to show an easy way to merge FIR corrections (with a thank you to Barleywater for the basic idea):
wesayso on merging two FIR corrections said:I set up a clean zone in JRiver, without any processing active, except the output Format with volume set to 100%. Next I set the output to Disk Writer. I took my current FIR filter into the Cool Edit wave editor and put some extra blank space in front and after the FIR impulse.
Next step I set convolution in JRiver to Pano's Rephase Shuffle2.wav and played back my FIR filter. Opened up the file JRiver wrote to disk and carefully edited the blank space out again. I put that blank audio in there because I noticed sometimes the exact file length changes when writing to disk. The intro had the exact length I had set but it was cut a little on the end of the file, so that was good practice. This merged the 2 FIR files perfectly when judged in REW. The phase angles changed exactly as set by Pano's shuffler FIR correction.
The beauty is this merges two stereo FIR files without much work.
This translates into the real world as following: "We still do exactly the old mean stuff as we ever did, as Wesayso's son can attest, if he is not deaf, except we now have our computers to turn it into candy for consumption by the ones who sit by their own computers and prolly do similar old mean stuff." At least you are not calling this HiFi. Thanks for this honesty!kindhornman said:Advances in processing
Once again you show how little you really know about this stuff. I do expect this to be your last thunder? Go listen to your setup, it might actually make you feel better, it always works for me (and my family).
Wesayso,
My best response to that was not to answer back. I didn't want a flame war, it would be easy to make many snide remarks about what I saw as his ideal, it wasn't worth the effort, some won't listen and just need to learn the hard way. I appreciate what you have done and even if I would do some things a bit different that doesn't in any way discount your efforts and fine results. The test plots alone should make some rethink what they assume they know. I will say I do hate the newer color graphs and would rather look at older discrete waterfall type of graphs but that just shows my age! I can see more detail with the discrete graphing, the colors are to smoothed to me as far as fine details but I can and do understand them. A troglodyte I guess.
My best response to that was not to answer back. I didn't want a flame war, it would be easy to make many snide remarks about what I saw as his ideal, it wasn't worth the effort, some won't listen and just need to learn the hard way. I appreciate what you have done and even if I would do some things a bit different that doesn't in any way discount your efforts and fine results. The test plots alone should make some rethink what they assume they know. I will say I do hate the newer color graphs and would rather look at older discrete waterfall type of graphs but that just shows my age! I can see more detail with the discrete graphing, the colors are to smoothed to me as far as fine details but I can and do understand them. A troglodyte I guess.
Wesayso, Thanks for the biggest laugh I've had in a while; your Shakespear comment. I feel a little sorry for Grasso. Being too sure of your beliefs can stunt learning badly. Not that we all don't do that sometimes, but enough is enough I guess.
And thanks for that comment a few pages back in the other thread on phantom center, about delays and/or decorrelation possibly damaging the stereo imagery in between L and R. I'll listen for that when I get this latest "Extractor" project together. Decorrelation makes all the difference in stereo reverb synthesis, so it seems worth researching and experimenting with.
And thanks for that comment a few pages back in the other thread on phantom center, about delays and/or decorrelation possibly damaging the stereo imagery in between L and R. I'll listen for that when I get this latest "Extractor" project together. Decorrelation makes all the difference in stereo reverb synthesis, so it seems worth researching and experimenting with.
Last edited:
Excuse me, i got angry. Courtesy of Peter Krips here is, what an EDGE-simulated 40 x 120 cm big flat piston without baffle does, with the listening position in center at distances of 12.5, 25, 50 and so on up to 3200 cm: Plots We see, that all responses roughly look like lowpasses of first order, the limit frequency doubling, as distance is doubled. There is not much comb filtering, if the listener stays within the length of the line, such as in Wesayso's setup. Severe comb filtering only starts at listening positions outside of the line.
Thanks Grasso789, it corresponds with what ra7 concluded with his corner array distance tests. Something I couldn't do within the space I have available.
This really isn't such a bad idea as most make it out to be. It has a few quite unique advantages. Due to not being a single large flat piston it won't be completely perfect but with a bit of help it gets close.
The FIR filtering makes it possible to correct little time anomalies. This is not a brute force solution as I only correct over a few cycles. The correction is more than you could create with IIR alone, though for a large part it's minimum phase. Only some room effects are softened (but not completely solved over 3 cycles) with linear phase. That makes the combined stereo sum look close to the ideal band pass device from 17 Hz to 18000 Hz.

This really isn't such a bad idea as most make it out to be. It has a few quite unique advantages. Due to not being a single large flat piston it won't be completely perfect but with a bit of help it gets close.
The FIR filtering makes it possible to correct little time anomalies. This is not a brute force solution as I only correct over a few cycles. The correction is more than you could create with IIR alone, though for a large part it's minimum phase. Only some room effects are softened (but not completely solved over 3 cycles) with linear phase. That makes the combined stereo sum look close to the ideal band pass device from 17 Hz to 18000 Hz.
Excuse me, i got angry. Courtesy of Peter Krips here is, what an EDGE-simulated 40 x 120 cm big flat piston without baffle does, with the listening position in center at distances of 12.5, 25, 50 and so on up to 3200 cm: Plots We see, that all responses roughly look like lowpasses of first order, the limit frequency doubling, as distance is doubled. There is not much comb filtering, if the listener stays within the length of the line, such as in Wesayso's setup. Severe comb filtering only starts at listening positions outside of the line.
Grasso, I didn't quite understand what you meant in your last post, quoted above.
The plot you showed us, what is it about? If I understand correctly, it is the frequency responses of a 40 x 120cm simulated driver at different listening distances, right? ( and are all the measurements on the same axis?).
If yes, why would you mention that here? I don't see any relation between what you showed us and what we are discussing over here. You getting angry ( as you have said) with something pretty irrelevant and trolling here is really disgusting, isn't it? Kindly read this thread atleast upto page 60. You may want to build one of these.
Wesayso, I think the plot this guy posted shows increasing comb filtering and strong attenuation with increasing listening distance, exactly opposite to your array as Ra7 has shown earlier. or am I missing something?
Ah, but you accept the super lobing of a simple line array in the nearfield, just because you turn the loudspeaker into the vertical??? Yes, my statements are blank, because they are new, and other statements may become written on top of them. I eat the stuff.
Just show a polar of the speaker you showed a photo of, and I will tell you why it ain't working, a d'Apollito on its side.
Back to the regular scheduled program.
I've been playing with Pano's phase shuffler with surprising results. I pré-converted 3 (very different) songs with the phase shuffler (PrePhase Shuffle-2.wav) and compared those to the original songs letting JRiver handle the average SPL.
I listened to these and without having a clue which was which I was able to pick out the treated files. Somehow they had a more open sound in the phantom center.
Here's a half way link to provide some background info: http://www.diyaudio.com/forums/multi-way/277519-fixing-stereo-phantom-center-27.html
After that test I included the shuffler to my FIR correction, (see a few posts back how to do that) and enjoyed listening to music for quite a while.
There's been a lot of activity on the phantom center thread lately with each of us trying to figure out an ideal shuffler for our setup.
I researched my prior work on cross talk canceling and compared it to the shuffler from Pano to try to find the answer there.
Based on the combined results I'm planning to run another test. I prepared a new shuffler with RePhase which combines ideas from my earlier work with this shuffler.

This shuffler, compared here to the original shuffler from Pano, should relate well to a cross talk cancelation signal delayed 0.270 ms.
Time will tell 🙂. Not running any tests soon had me spamming the phantom center thread with prior tests so I figured to bring some of my enthusiasm here instead. Who knows, it may even get this thread back on topic again 🙂.
I've been playing with Pano's phase shuffler with surprising results. I pré-converted 3 (very different) songs with the phase shuffler (PrePhase Shuffle-2.wav) and compared those to the original songs letting JRiver handle the average SPL.
I listened to these and without having a clue which was which I was able to pick out the treated files. Somehow they had a more open sound in the phantom center.
Here's a half way link to provide some background info: http://www.diyaudio.com/forums/multi-way/277519-fixing-stereo-phantom-center-27.html
After that test I included the shuffler to my FIR correction, (see a few posts back how to do that) and enjoyed listening to music for quite a while.
There's been a lot of activity on the phantom center thread lately with each of us trying to figure out an ideal shuffler for our setup.
I researched my prior work on cross talk canceling and compared it to the shuffler from Pano to try to find the answer there.
Based on the combined results I'm planning to run another test. I prepared a new shuffler with RePhase which combines ideas from my earlier work with this shuffler.
This shuffler, compared here to the original shuffler from Pano, should relate well to a cross talk cancelation signal delayed 0.270 ms.
Time will tell 🙂. Not running any tests soon had me spamming the phantom center thread with prior tests so I figured to bring some of my enthusiasm here instead. Who knows, it may even get this thread back on topic again 🙂.
No measurements but simulations, and yes, on axis.The plot you showed us, what is it about? If I understand correctly, it is the frequency responses of a 40 x 120cm simulated driver at different listening distances, right? ( and are all the measurements on the same axis?).
Yes, thou do not see, that the plots, which i posted, show on-axis responses of a simple line array. They differ much with listening distance. For a nice presentation, in which plots do not cross each other, the one for nearest distance, the one which really is the loudest, has been attentuated the most. The response dependance on distance is a reason, why simple line arrays are not necessarily the best tools for understanding room- and psycho-acoustics, even if the array is as high, as the room is.Wesayso, I think the plot this guy posted shows increasing comb filtering and strong attenuation with increasing listening distance, exactly opposite to your array as Ra7 has shown earlier. or am I missing something?
Vacuphile, a symmetrical arrangement is not necessarily a D'Apollito but may be a Krassolito one. The difference mostly is the filtering, third order for classic D'Apollito and first order for Krassolito. The slow transit reduces lobing strength, as well as a crossover point below the classic D'Apollito one does. I will post measurements in free field.
Last edited:
Which makes the output at greater distance more free from comb effects and in line with what ra7's plots showed.
Room and psycho-acoustics have nothing to do with this though. You need to be at a certain distance, and avoid or absorb early reflections for best results. The plots do not lie.
Nothing to do with understanding room behavior as every speaker in a room suffers from that to a degree. I've shown the late arrival wave front to be very similar in FR response indicating good power response. I've also shown measurements along the listening area. I'm not digging those up again, they are all here in this thread.
Are we agreeing or is it time for you to move on to another thread, Grasso789?
One thing: I won't do short arrays. I chose the long array for a reason and stand by that choice. Also explained more than once on this thread.
May I move on to the normal program material again? And hopefully stay there this time....
Room and psycho-acoustics have nothing to do with this though. You need to be at a certain distance, and avoid or absorb early reflections for best results. The plots do not lie.
Nothing to do with understanding room behavior as every speaker in a room suffers from that to a degree. I've shown the late arrival wave front to be very similar in FR response indicating good power response. I've also shown measurements along the listening area. I'm not digging those up again, they are all here in this thread.
Are we agreeing or is it time for you to move on to another thread, Grasso789?
One thing: I won't do short arrays. I chose the long array for a reason and stand by that choice. Also explained more than once on this thread.
May I move on to the normal program material again? And hopefully stay there this time....
We are not fully agreeing, Wesayso, and thou see, that i have not moved to another thread yet. There may be a third option, a quieter one.
Only if you promise to read this whole thread. You're not the first to suggest shading for a line array. I'd suggest reading up on posts by speaker dave too. Especially the one with his papers on line array behavior. I've read most papers from Don Keele, except the latest one (I'm not an AES member).
There are reasons for every step I made on this journey. Reading this thread will highlight some of it, not even all of it. I understand what direction you want to go. But I have valid (for me) reasons to do what I do. And it's working. I have called this project finished at one point. I'm just too curious about it all to stop experimenting with my setup.
I haven't even tried half of what I wanted to try originally. All based on a lot of reading, simulating and thinking. So if you want a conversation about this, come with valid and clear suggestions and examples. This thread is full of just that. Lots of examples for every step along the way.
One more question to add;
How can you say you do not agree with me without investigating what I did first and why? And do we really need to agree? Ok. that was a second question 🙂.
What I was hoping for, is for you to add even half as much real life measurements to your thread, showing the potential of your specific ideas as I have tried to show in my thread here. Then we would have something to talk about, all just in my opinion of coarse.
There are reasons for every step I made on this journey. Reading this thread will highlight some of it, not even all of it. I understand what direction you want to go. But I have valid (for me) reasons to do what I do. And it's working. I have called this project finished at one point. I'm just too curious about it all to stop experimenting with my setup.
I haven't even tried half of what I wanted to try originally. All based on a lot of reading, simulating and thinking. So if you want a conversation about this, come with valid and clear suggestions and examples. This thread is full of just that. Lots of examples for every step along the way.
One more question to add;
How can you say you do not agree with me without investigating what I did first and why? And do we really need to agree? Ok. that was a second question 🙂.
What I was hoping for, is for you to add even half as much real life measurements to your thread, showing the potential of your specific ideas as I have tried to show in my thread here. Then we would have something to talk about, all just in my opinion of coarse.
Last edited:
Back to reality... the Phantom Shuffler, what is it and how does it work? That question intrigued me so I went on a crusade to figure it out. It all started with BYRTT posting some Dirac pulses summed with a slight time delay.
That triggered me to start investigating what it was that I liked about the shuffler. If you want to see what I tried, follow this link...
I'll try and explain what I think is happening... First we start with a picture of what cross talk is:
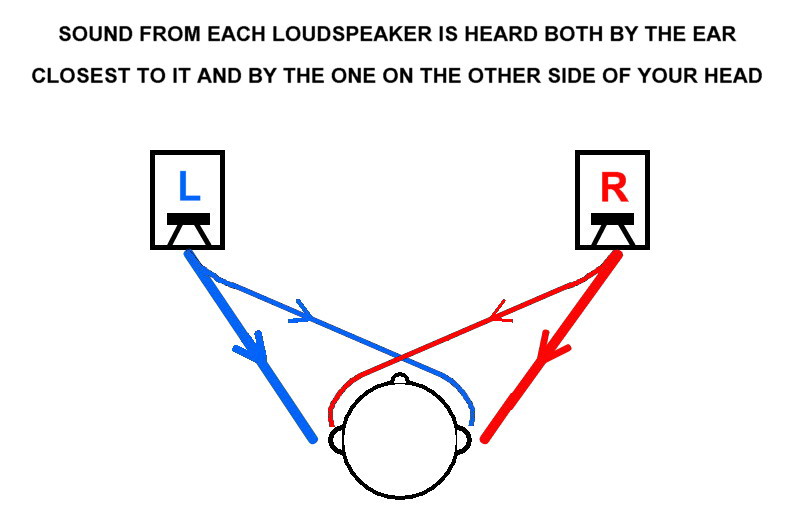
(picture "borrowed" from Steve Hoffman forums)
The thick red and blue lines are the direct sound. They will arrive at your ears first. The thin lines cannot be avoided though, sound from the left channel is going to reach the ear on the right side and vice versa. There will be a time difference between those two sounds. Depending on how the speakers are setup and even your head size plays a role.
If we listen to phantom information both our left and right channel are playing the same information. But we saw above that sound also travels around your head reaching the other ear. That's where the sound will interfere and will cause comb filtering to happen (oh no, not that again 😀).
So what does it look like, you may ask. If we stick with an average delay of 0.270 ms we can figure it out.
Sound travels from the left speaker to the left ear, the wave continues and reaches the right one 0.27 ms later. But that particular ear just received the same info as the left if the content was panned to the center. This is where the combing starts. If we assume a Dirac pulse, arriving at that right ear we would get the delayed content of the left ear interfering with that pulse 0.27 ms later.
On to REW, we take 2 Dirac pulses and delay one of them with 0.27 ms. This will give us a view of our comb pattern:

So we get a first wave front, free from combing and 0.27 ms later it starts combing (at both ears) and creates the above pattern at our ears.
It actually fitted my experience, I've told you guys I cut 2 frequencies in my mid/side processing. Guess what they are!
One cut is at 3700 Hz, Q = 2.5 and gain = -1.4 dB and the second one is at 7270 Hz, Q = 2.5 and gain = -1 dB. Those settings were a "left over" from my earlier cross talk cancelation experiments. I found it cleared up some center panned vocals that were harder to follow without the cuts. It's in this thread somewhere.
Good fit right? If you look at the summed Dirac comb filter pattern it makes perfect sense. I even cut a tiny bit in the sides signal to fine tune my balance. But it wouldn't/shouldn't be absolutely necessary.
Now why does the phase shuffle work? What does it do to the above situation?
To find out we start to sum the shuffler IR instead of that perfect Dirac pulse.
Again we offset one of the pulses by 0.27 ms and look at the comb filter result.

Red trace is the shuffler called "Rephase Shuffle-2.wav" from Pano's thread. Purple trace is the Dirac again to compare.
Do you see the difference? By alternating the phase, which is what the shuffler does (see a couple of posts above), we move the dips to a different location. We created a phase difference at ~2000 Hz between both channels of 60 degree (or slightly more).
The signal still sums, but the dip is moved in frequency by that subtle phase turn. Because the phase is opposite on the other channel the result at the other ear will look different.
Here's a view of both results. One trace would represent the left ear signal and the other one the right ear:

Now we see the magic! You either get that Dirac comb pattern at both ears (without shuffle) or we get the above combing, slightly different for each ear but together creating a better balance. Remember, we already heard the direct (non disturbed) wave front for 0.270 ms before this happens.
So the choice is to listen to the Dirac combing at left and right ear, screwing up our balance or use a shuffler to shift the dips and get a more even balance to process in our head.
Let's look at an average of the shuffler combing and the Dirac combing as we get to process it in our head:

See how most dips are filled in? This actually brightens the phantom center. Making it sound more real. The dips eat away less of the signal arriving at the ears. It even gave me more sense of depth. Earlier I quoted material that told us boosting at 2 KHz gives more sense of depth. Care to guess why that is if you look at this story? 🙄
Now why would it only work on the phantom center material? If you look at the sounds panned hard to the left, they don't have an equivalent sound wave comming from the right channel to interfere with the left channel sounds that's leaking to the right ear. And if we combine the left shuffle IR with a delayed left shuffle IR we end up with: the exact same shape as the Dirac comb pattern. So for panned sounds we get some cross talk, possibly coloring what we hear but not the combing, eating away at our wave front.
In other words: no change to the left or right panned sounds, only a perceptual change of the phantom center. Except for the possibility of hearing the small phase shifts we introduced to the signal chain. Some sounds will be a bit early (by about 0.16 ms max) or late (by the same amount). I'll have to admit, I couldn't hear that difference.
I was more in awe of what the shuffler did for the phantom center! 😱
I hope you guys like this theory, it's the best I can do right now 🙂.
Ronald
That triggered me to start investigating what it was that I liked about the shuffler. If you want to see what I tried, follow this link...
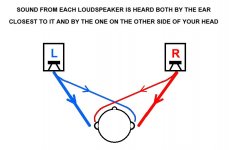
I'll try and explain what I think is happening... First we start with a picture of what cross talk is:
(picture "borrowed" from Steve Hoffman forums)
The thick red and blue lines are the direct sound. They will arrive at your ears first. The thin lines cannot be avoided though, sound from the left channel is going to reach the ear on the right side and vice versa. There will be a time difference between those two sounds. Depending on how the speakers are setup and even your head size plays a role.
If we listen to phantom information both our left and right channel are playing the same information. But we saw above that sound also travels around your head reaching the other ear. That's where the sound will interfere and will cause comb filtering to happen (oh no, not that again 😀).
So what does it look like, you may ask. If we stick with an average delay of 0.270 ms we can figure it out.
Sound travels from the left speaker to the left ear, the wave continues and reaches the right one 0.27 ms later. But that particular ear just received the same info as the left if the content was panned to the center. This is where the combing starts. If we assume a Dirac pulse, arriving at that right ear we would get the delayed content of the left ear interfering with that pulse 0.27 ms later.
On to REW, we take 2 Dirac pulses and delay one of them with 0.27 ms. This will give us a view of our comb pattern:
So we get a first wave front, free from combing and 0.27 ms later it starts combing (at both ears) and creates the above pattern at our ears.
It actually fitted my experience, I've told you guys I cut 2 frequencies in my mid/side processing. Guess what they are!
One cut is at 3700 Hz, Q = 2.5 and gain = -1.4 dB and the second one is at 7270 Hz, Q = 2.5 and gain = -1 dB. Those settings were a "left over" from my earlier cross talk cancelation experiments. I found it cleared up some center panned vocals that were harder to follow without the cuts. It's in this thread somewhere.
Good fit right? If you look at the summed Dirac comb filter pattern it makes perfect sense. I even cut a tiny bit in the sides signal to fine tune my balance. But it wouldn't/shouldn't be absolutely necessary.
Now why does the phase shuffle work? What does it do to the above situation?
To find out we start to sum the shuffler IR instead of that perfect Dirac pulse.
Again we offset one of the pulses by 0.27 ms and look at the comb filter result.
Red trace is the shuffler called "Rephase Shuffle-2.wav" from Pano's thread. Purple trace is the Dirac again to compare.
Do you see the difference? By alternating the phase, which is what the shuffler does (see a couple of posts above), we move the dips to a different location. We created a phase difference at ~2000 Hz between both channels of 60 degree (or slightly more).
The signal still sums, but the dip is moved in frequency by that subtle phase turn. Because the phase is opposite on the other channel the result at the other ear will look different.
Here's a view of both results. One trace would represent the left ear signal and the other one the right ear:
Now we see the magic! You either get that Dirac comb pattern at both ears (without shuffle) or we get the above combing, slightly different for each ear but together creating a better balance. Remember, we already heard the direct (non disturbed) wave front for 0.270 ms before this happens.
So the choice is to listen to the Dirac combing at left and right ear, screwing up our balance or use a shuffler to shift the dips and get a more even balance to process in our head.
Let's look at an average of the shuffler combing and the Dirac combing as we get to process it in our head:
See how most dips are filled in? This actually brightens the phantom center. Making it sound more real. The dips eat away less of the signal arriving at the ears. It even gave me more sense of depth. Earlier I quoted material that told us boosting at 2 KHz gives more sense of depth. Care to guess why that is if you look at this story? 🙄
Now why would it only work on the phantom center material? If you look at the sounds panned hard to the left, they don't have an equivalent sound wave comming from the right channel to interfere with the left channel sounds that's leaking to the right ear. And if we combine the left shuffle IR with a delayed left shuffle IR we end up with: the exact same shape as the Dirac comb pattern. So for panned sounds we get some cross talk, possibly coloring what we hear but not the combing, eating away at our wave front.
In other words: no change to the left or right panned sounds, only a perceptual change of the phantom center. Except for the possibility of hearing the small phase shifts we introduced to the signal chain. Some sounds will be a bit early (by about 0.16 ms max) or late (by the same amount). I'll have to admit, I couldn't hear that difference.
I was more in awe of what the shuffler did for the phantom center! 😱
I hope you guys like this theory, it's the best I can do right now 🙂.
Ronald
Attachments
Last edited:

.....I hope you guys like this theory, it's the best I can do right now 🙂......
Nice presentation and work there 🙂
So after figuring out the above, I spend a little time trying to optimize the shuffler. Now that "I got" what it does I could make a better guess on what to try.
Here's a picture showing some details:

Cyan line is the Dirac comb sum we all get for our phantom center summation.
Red line is Pano's shuffler, upon which I based the story above.
Dark blue is my attempt to "better" the shuffler, based on the 0.27 ms time difference.
Green is an actual measurement from Toole (traced by BYRTT for import into REW) from a phantom center measured at a dummy head. That FR curve is the result of the direct wave front, followed by the Dirac comb filter pattern eating away valuable information.
My attempt to better the shuffler can be found here...
If you're intrigued by this story and like to try without setting up a FIR filter in your chain you can listen to samples made by (dyno)Mike here: Comparison tracks by dynomike
Be sure to listen on well balanced speakers in an equilateral 60 degree Stereo setup with care to avoid/absorb early reflections. I cannot stress that point enough. Read the paper linked in the second post of the Fixing the Stereo Phantom Center thread for more background.
Disclaimer: Try this in a reflective room (causing early reflections, some speakers avoid that, like horns) and it might work against you...
Here's a picture showing some details:
Cyan line is the Dirac comb sum we all get for our phantom center summation.
Red line is Pano's shuffler, upon which I based the story above.
Dark blue is my attempt to "better" the shuffler, based on the 0.27 ms time difference.
Green is an actual measurement from Toole (traced by BYRTT for import into REW) from a phantom center measured at a dummy head. That FR curve is the result of the direct wave front, followed by the Dirac comb filter pattern eating away valuable information.
My attempt to better the shuffler can be found here...
If you're intrigued by this story and like to try without setting up a FIR filter in your chain you can listen to samples made by (dyno)Mike here: Comparison tracks by dynomike
Be sure to listen on well balanced speakers in an equilateral 60 degree Stereo setup with care to avoid/absorb early reflections. I cannot stress that point enough. Read the paper linked in the second post of the Fixing the Stereo Phantom Center thread for more background.
Disclaimer: Try this in a reflective room (causing early reflections, some speakers avoid that, like horns) and it might work against you...
Last edited:
Nice presentation and work there 🙂
Thanks to you, Pano and dynomike! 😉
This was very much a joint effort... I'm just trying to connect the dots... Hope it makes as much sense to you guys.
Last edited:
- Home
- Loudspeakers
- Full Range
- The making of: The Two Towers (a 25 driver Full Range line array)