yes wimms, you've got a point
wavelets, window Fourier and other time-frequency transforms are mathematically closest to what we hear. Look at compression algorithms. I read that someone compared wavelet time-frequency analysis to musical notes, which are basically root freqency as a function of time, with all these Italian strange words to describe tone and 'sound' (=~spectrum and harmonics).
Thus, it would be wise I think to test amps with several test signals (like parts of music) and find a metric based on differences in wavelet representation (it could be simple metric).
Only thoughts....
Even if it would be most appropiate way to test amps, people will still believe in THD😀
best regards to all
wavelets, window Fourier and other time-frequency transforms are mathematically closest to what we hear. Look at compression algorithms. I read that someone compared wavelet time-frequency analysis to musical notes, which are basically root freqency as a function of time, with all these Italian strange words to describe tone and 'sound' (=~spectrum and harmonics).
Thus, it would be wise I think to test amps with several test signals (like parts of music) and find a metric based on differences in wavelet representation (it could be simple metric).
Only thoughts....
Even if it would be most appropiate way to test amps, people will still believe in THD😀
best regards to all
I think this is spot on. Wavelets may provide a very good way of focussing down onto those parts of the the information that actually matter.
The manner the ear detects sound is really quite something, but what it doesn't do is a Fourier transform. In fact a Fourier transform makes no sense in its most pedantic form.
The success of compression algorithms gives us some real hope for understanding where to put the real effort. It is very clear that there is a lot of information that the ear simply ignores, and yet some information that it is critically attuned to. We do need to be somewhat careful however. These algorithms (i.e. wavlet and related compression) are still based upon easy to implement and arithmetically tractable implementations. The ear operates in a number of domains, not all of them easily represented in an easy algorithmic form. So we can fall into some unfortunate traps - much akin to over reliance on Fourier transforms.
One think to consider is the manner that the ear is able to extract a huge amount of information very quickly from the transient attack of a sound. It has been shown that the noise like attack components in a piano sound convey totally crucial information to the ear, and we are able to extract it in near real time. The manner this is done is not totally understood, but some parts are, and it is pretty stunning.
The manner the ear detects sound is really quite something, but what it doesn't do is a Fourier transform. In fact a Fourier transform makes no sense in its most pedantic form.
The success of compression algorithms gives us some real hope for understanding where to put the real effort. It is very clear that there is a lot of information that the ear simply ignores, and yet some information that it is critically attuned to. We do need to be somewhat careful however. These algorithms (i.e. wavlet and related compression) are still based upon easy to implement and arithmetically tractable implementations. The ear operates in a number of domains, not all of them easily represented in an easy algorithmic form. So we can fall into some unfortunate traps - much akin to over reliance on Fourier transforms.
One think to consider is the manner that the ear is able to extract a huge amount of information very quickly from the transient attack of a sound. It has been shown that the noise like attack components in a piano sound convey totally crucial information to the ear, and we are able to extract it in near real time. The manner this is done is not totally understood, but some parts are, and it is pretty stunning.
Wavelets for Dummies??
Wavelets for Dummies?
Professing gross ignorance of this topic. Is there a concise and direct (preferably in "English") that can be provided for this?
I suspect I am not alone in this.
_-_-bear
Wavelets for Dummies?
Professing gross ignorance of this topic. Is there a concise and direct (preferably in "English") that can be provided for this?
I suspect I am not alone in this.
_-_-bear
Wimms,
Well, I have no experience with wavelets. I have the impression wavelets would consist of single frequency elements. A toneburst a la Linkwitz however contains clearly identifiable sidebands that generate HD and IMD. Anway Linkwitz uses and discusses tonebursts of different lengths and nature and their respective pros and cons. The million dollar question remains, which test closely reflects our hearing sensitivities and why.
I don't follow here. Not that I have an authoritative grasp on the subject, but to me, the release of the energy, while unrelated to the excitation spectrum and magnitude , would still relate to a form of resonance. Any energy storage implies an absence of damping at the release frequency, and thus a resonance - regardless of the excitation.
Francis,
Well, here my short list of "main surprising features of the ear to consider in any distortion audibility discussion":
-single-ended response: only the "in-stroke" gets transduced into nerve impulse, implying a fairly low sensitivity to wave form, with however, detectable polarity
- a time domain element, due to recovery time of the nerves, which one could see as / translate into, a "digital" sampling process with associated restricitons - frequency response and time resolution for instance, and associated sensitivity to specific time and frequency domain errors (those which occur at the vicinity of the sampling rate or multiples thereof)
- nonlinear active amplification of the signal, up to 40-60 dB (!!). The initial curve at the cochlear cells apparently follows a second order S- shaped transfer function. To me this implies a much increased sensitivity specifically to low-level signal components and thus, specifically, low-level signal errors. Just as jitter turned out more bothersome in CD than wow and flutter in analog.
Bottom line, one could get a good guess of those distortions that would matter most, out of first principles of the hearing process. In other words, a short list of "what windows of detectability can we can expect from human hearing".
Does anybody have actual numbers to flesh this out? I admit I don't - except for the amplification factor. I guess one could deduct some time scale elements from the audibility of jitter - does anybody have the current state of the art numbers on jitter audibility?
- except for the amplification factor. I guess one could deduct some time scale elements from the audibility of jitter - does anybody have the current state of the art numbers on jitter audibility?
Missing is time resolution. Transient response.
Spectral analysis must change to wavelet transform to dig into that realm, imo.
Well, I have no experience with wavelets. I have the impression wavelets would consist of single frequency elements. A toneburst a la Linkwitz however contains clearly identifiable sidebands that generate HD and IMD. Anway Linkwitz uses and discusses tonebursts of different lengths and nature and their respective pros and cons. The million dollar question remains, which test closely reflects our hearing sensitivities and why.
Note that energy storage isn't necessarily resonance. Energy stored could be released in totally unrelated spectrum, thus FR shows very little about it directly.
I don't follow here. Not that I have an authoritative grasp on the subject, but to me, the release of the energy, while unrelated to the excitation spectrum and magnitude , would still relate to a form of resonance. Any energy storage implies an absence of damping at the release frequency, and thus a resonance - regardless of the excitation.
Francis,
One think to consider is the manner that the ear is able to extract a huge amount of information very quickly from the transient attack of a sound. It has been shown that the noise like attack components in a piano sound convey totally crucial information to the ear, and we are able to extract it in near real time. The manner this is done is not totally understood, but some parts are, and it is pretty stunning.
Well, here my short list of "main surprising features of the ear to consider in any distortion audibility discussion":
-single-ended response: only the "in-stroke" gets transduced into nerve impulse, implying a fairly low sensitivity to wave form, with however, detectable polarity
- a time domain element, due to recovery time of the nerves, which one could see as / translate into, a "digital" sampling process with associated restricitons - frequency response and time resolution for instance, and associated sensitivity to specific time and frequency domain errors (those which occur at the vicinity of the sampling rate or multiples thereof)
- nonlinear active amplification of the signal, up to 40-60 dB (!!). The initial curve at the cochlear cells apparently follows a second order S- shaped transfer function. To me this implies a much increased sensitivity specifically to low-level signal components and thus, specifically, low-level signal errors. Just as jitter turned out more bothersome in CD than wow and flutter in analog.
Bottom line, one could get a good guess of those distortions that would matter most, out of first principles of the hearing process. In other words, a short list of "what windows of detectability can we can expect from human hearing".
Does anybody have actual numbers to flesh this out? I admit I don't
- except for the amplification factor. I guess one could deduct some time scale elements from the audibility of jitter - does anybody have the current state of the art numbers on jitter audibility?Re: Wavelets for Dummies??
But I think this one is sorta wannabe: http://perso.wanadoo.fr/polyvalens/clemens/wavelets/wavelets.html
There is pun in the title, but heck, Fourier isn't exactly trivial matter either.
When you find one, let me know too.bear said:Wavelets for Dummies?
I suspect I am not alone in this.
But I think this one is sorta wannabe: http://perso.wanadoo.fr/polyvalens/clemens/wavelets/wavelets.html
There is pun in the title, but heck, Fourier isn't exactly trivial matter either.
Wavelets can not consist of single frequency. But they are waves, sum of their points in time-domain add up to zero. Toneburst is basically a variant of wavelet, I believe. I'm not sure of that one, but imo toneburst testing is a limited case of wavelet transform.MBK said:Well, I have no experience with wavelets. I have the impression wavelets would consist of single frequency elements. A toneburst a la Linkwitz however contains clearly identifiable sidebands that generate HD and IMD. Anway Linkwitz uses and discusses tonebursts of different lengths and nature and their respective pros and cons. The million dollar question remains, which test closely reflects our hearing sensitivities and why.
Issue with energy storage is, that there are zillions of mechanical microresonances that depend on excitation signal, that all together add up to some static FR. It takes a single look at waterfall plot to see the limitation of FR.I don't follow here. Not that I have an authoritative grasp on the subject, but to me, the release of the energy, while unrelated to the excitation spectrum and magnitude , would still relate to a form of resonance. Any energy storage implies an absence of damping at the release frequency, and thus a resonance - regardless of the excitation.
http://www.geocities.com/kreskovs/Stored-energy2.html
Take look, could you even remotely extract from the FR alone that waterfall plot like that would be measured?
http://physrev.physiology.org/cgi/content/full/81/3/1305 to get a glimpse of what a crazy field this truely is.Bottom line, one could get a good guess of those distortions that would matter most, out of first principles of the hearing process. In other words, a short list of "what windows of detectability can we can expect from human hearing".
Does anybody have actual numbers to flesh this out? I admit I don't
http://www.tnt.uni-hannover.de/org/whois/wissmit/baumgart/publications.html for relevant work on physiological masking.
Hi Wimms
thanks for the links. I read the wavelet paper, I have t admit that I give up on the math here. But at least I got a picture of the theory...
Re: physiology of hearing, yes, this field has a lot to give yet.
My question about data aimed at getting some generally accepted limits of human hearing, the current textbook opinion so to speak, especially for :
- time domain precision (beyond the often cited phase recognition, head transfer function which both relate more to signal processing tham theoretical resolution). What timing errors do we actually perceive? I vaguely remember 13 us as the cutoff before we can distinguish between direct sound and echo, but the jitter discussion shows that this may also relate more to a signal processing limit than a sensory time domain resolution issue.
- low level signal resolution. Or in other words, how many bits do we actually perceive , especially at low level?
thanks for the links. I read the wavelet paper, I have t admit that I give up on the math here. But at least I got a picture of the theory...
Re: physiology of hearing, yes, this field has a lot to give yet.
My question about data aimed at getting some generally accepted limits of human hearing, the current textbook opinion so to speak, especially for :
- time domain precision (beyond the often cited phase recognition, head transfer function which both relate more to signal processing tham theoretical resolution). What timing errors do we actually perceive? I vaguely remember 13 us as the cutoff before we can distinguish between direct sound and echo, but the jitter discussion shows that this may also relate more to a signal processing limit than a sensory time domain resolution issue.
- low level signal resolution. Or in other words, how many bits do we actually perceive , especially at low level?
Brain processing
Francis,
I have followed this thread with great interest, thank you. I would like to ask you if you have any references for your exposition on "hearing fatigue," re. brain processing. I have heard about this from multiple sources, but I was wondering if there is any scientific evidence to support it.
Graham,
Re: harmonic distortions. Professionally I have made the observation that adding certain amounts HD in recordings can actually IMPROVE spatial imaging in loudspeaker playback. A certain three-dimensional effect is evoked with added "overtones". This effect is quite well-known in the recording industry and has been utilized in some early analog signal processing (Aphex "Exciter"), and perhaps "overutilized" in a number of recent plugins for computer recording programs. It would certainly explain to some extent why amplifiers with a high low-order harmonic distortion content can sound more "pleasing" to the listener.
Thank you for all of your help
Cheers
Francis,
I have followed this thread with great interest, thank you. I would like to ask you if you have any references for your exposition on "hearing fatigue," re. brain processing. I have heard about this from multiple sources, but I was wondering if there is any scientific evidence to support it.
Graham,
Re: harmonic distortions. Professionally I have made the observation that adding certain amounts HD in recordings can actually IMPROVE spatial imaging in loudspeaker playback. A certain three-dimensional effect is evoked with added "overtones". This effect is quite well-known in the recording industry and has been utilized in some early analog signal processing (Aphex "Exciter"), and perhaps "overutilized" in a number of recent plugins for computer recording programs. It would certainly explain to some extent why amplifiers with a high low-order harmonic distortion content can sound more "pleasing" to the listener.
Thank you for all of your help
Cheers
A couple of comments. My brain is fried - I just got off the plane from Singapore.
Energy storage. You need more than simple storage to resonate. An RC circuit has no resonant mode. If you put a brick on a table, or even drop it off, there is no resonance. For resonance you need energy exchange between two storage mechanisms. Like and L and C, a spring and moving mass; and the energy storage mechanisms must be out of phase (so that the energy can be exchanged without loss.)
To store wave energy you can put it into a delay line, but the line itself does not resonate. If you do this the system is no longer minimum phase.
Jitter. You need to be very careful. There is no chance at all that the ear is capable of resolving the timing errors that a CD system (even the worst designs) exhibit as jitter in a DAC. Rather if you have a signal correlated timing jitter you end up with energy in new frequencies that are related to the signal in horrid ways. Things like sum and difference terms that involve the sample clock, S/PDIF clock, other clocks, as well as the signal frequency. Very nasty and in-harmonic. Better termed intermodulation. If the jitter was truly random all you would see is a raised noise floor.
Single ended nerve impulses. Again care needed here. When quiet the nerves emit at a basis pulse rate (or rather an average rate, since the rate is noisy) and movement of the basilar membrane toward the scala tympani results in enhanced firing, and away results in inhibited firing. The rate of firing is also partially related to position as well, but that is second order. It is not true to say that all movement towards the scala vestibuli results in no firing at all. You can regard the base pulse rate as the bias. Secondly, even the maximum firing rate is quite low, low enough that above a few hundred Hertz there is less than one firing per period of the signal being measured, and the waveform is essentially being sub-sampled with a temporally dithered pulse stream. At these frequencies the waveform sampling is thus fully symmetric. The enhancement and inhibition rates may well not be symmetric (I don't have figures to hand) so there is likely some absolute phase information at low frequencies. Unfortunately there is no evidence that the brain actually uses this information in the form needed to extract absolute phase. The distribution of firings seems to get temporally binned, and the pattern of the binning yields some information. Absolute phase information would get lost in this process.
Energy storage. You need more than simple storage to resonate. An RC circuit has no resonant mode. If you put a brick on a table, or even drop it off, there is no resonance. For resonance you need energy exchange between two storage mechanisms. Like and L and C, a spring and moving mass; and the energy storage mechanisms must be out of phase (so that the energy can be exchanged without loss.)
To store wave energy you can put it into a delay line, but the line itself does not resonate. If you do this the system is no longer minimum phase.
Jitter. You need to be very careful. There is no chance at all that the ear is capable of resolving the timing errors that a CD system (even the worst designs) exhibit as jitter in a DAC. Rather if you have a signal correlated timing jitter you end up with energy in new frequencies that are related to the signal in horrid ways. Things like sum and difference terms that involve the sample clock, S/PDIF clock, other clocks, as well as the signal frequency. Very nasty and in-harmonic. Better termed intermodulation. If the jitter was truly random all you would see is a raised noise floor.
Single ended nerve impulses. Again care needed here. When quiet the nerves emit at a basis pulse rate (or rather an average rate, since the rate is noisy) and movement of the basilar membrane toward the scala tympani results in enhanced firing, and away results in inhibited firing. The rate of firing is also partially related to position as well, but that is second order. It is not true to say that all movement towards the scala vestibuli results in no firing at all. You can regard the base pulse rate as the bias. Secondly, even the maximum firing rate is quite low, low enough that above a few hundred Hertz there is less than one firing per period of the signal being measured, and the waveform is essentially being sub-sampled with a temporally dithered pulse stream. At these frequencies the waveform sampling is thus fully symmetric. The enhancement and inhibition rates may well not be symmetric (I don't have figures to hand) so there is likely some absolute phase information at low frequencies. Unfortunately there is no evidence that the brain actually uses this information in the form needed to extract absolute phase. The distribution of firings seems to get temporally binned, and the pattern of the binning yields some information. Absolute phase information would get lost in this process.
Francis,
not bad for a fried brain... so what were you doing in Singapore that fried it? 🙂
Energy storage: I see the point, I was thinking about this much too narrowly. I also found Wimms' link to energy storage of a crossover very enlightening.
Jitter: probably a bad example. I didn't mean we actually heard the timing error of the digital stage. I brought it up as an example how seemingly minute technical tolerances can translate into very audible effects. I did actually not know why exactly (correlated) jitter sounds so bad ( the mechanisms). So it creates bad harmonics. Extrapolated to HD and IMD in feedback amps and following Graham's line of thought about time delay in error correction, what you say about "horrid HD" arising from jitter would then also apply to analog feedback amp timing errors I assume? And could one apply a similar cure as to the correlated jitter problem - decorrelate the error? (I have read at least one company's pamphlet for a product claiming that simply decorrelated jitter, even of higher magnitude, sounds as good as reduced jitter).
Human hearing:
well, here I do remember the graphs of this recent paper:
hearing study
and my comments on it in a different thread: (quotes are quoting the paper's authors)
-----------
"Here we show that asymmetrical transducer currents and receptor potentials are significantly larger than previously thought, they possess a highly restricted dynamic range and strongly depend on cochlear location."
The authors show graphs of "steady-state transducer current plotted as a function of basilar membrane displacement" and fitted them with "second order Boltzmann functions".
The graphs clearly show transducer current only on positive basilinear membrane displacement (the membrane displacement itself looks symmetrical). Current starts at about 25% of maximum measured displacement (100 nm) after zero crossing and does saturate at a certain level.
Several nonlinearities stick out - apparent sensitivity difference between basal and apical cells (about 6 fold), saturation of course, and differences in amplification depending on cell location (estimated at 45 dB at low frequencies to approximately 60 dB at high frequencies)
Bottom line: the ear works on positive displacement only, and selectively amplifies the signal to a varying but very high degree. This amplification reaches saturation after a certain point. The transfer function as a whole fits a second order function (S-shaped).
-------------
This is about transducer current though, not resulting nerve impules. Also, the asymmetry would apply to polarity, not phase - and ultimate audibility would depend on an asymmetrical waveform.
I see two possible approaches anyway as to human hearing: actual transducer mechanisms, as above, and empirical psychoacoustics.
The first points at theoretical limits and can give order-of-magnitude kinds of estimates. Disadvantage, the field can hold significant surprises still. The active amplification was not proven until very recently, though hinted at as early as the 60's.
The empirical approach gives a direct shot at what we want to know, "can we hear it", but has a lot of credibility and study design problems, as shown by the many endless subjectivist/objectivist debates in this forum.
not bad for a fried brain... so what were you doing in Singapore that fried it? 🙂
Energy storage: I see the point, I was thinking about this much too narrowly. I also found Wimms' link to energy storage of a crossover very enlightening.
Jitter: probably a bad example. I didn't mean we actually heard the timing error of the digital stage. I brought it up as an example how seemingly minute technical tolerances can translate into very audible effects. I did actually not know why exactly (correlated) jitter sounds so bad ( the mechanisms). So it creates bad harmonics. Extrapolated to HD and IMD in feedback amps and following Graham's line of thought about time delay in error correction, what you say about "horrid HD" arising from jitter would then also apply to analog feedback amp timing errors I assume? And could one apply a similar cure as to the correlated jitter problem - decorrelate the error? (I have read at least one company's pamphlet for a product claiming that simply decorrelated jitter, even of higher magnitude, sounds as good as reduced jitter).
Human hearing:
well, here I do remember the graphs of this recent paper:
hearing study
and my comments on it in a different thread: (quotes are quoting the paper's authors)
-----------
"Here we show that asymmetrical transducer currents and receptor potentials are significantly larger than previously thought, they possess a highly restricted dynamic range and strongly depend on cochlear location."
The authors show graphs of "steady-state transducer current plotted as a function of basilar membrane displacement" and fitted them with "second order Boltzmann functions".
The graphs clearly show transducer current only on positive basilinear membrane displacement (the membrane displacement itself looks symmetrical). Current starts at about 25% of maximum measured displacement (100 nm) after zero crossing and does saturate at a certain level.
Several nonlinearities stick out - apparent sensitivity difference between basal and apical cells (about 6 fold), saturation of course, and differences in amplification depending on cell location (estimated at 45 dB at low frequencies to approximately 60 dB at high frequencies)
Bottom line: the ear works on positive displacement only, and selectively amplifies the signal to a varying but very high degree. This amplification reaches saturation after a certain point. The transfer function as a whole fits a second order function (S-shaped).
-------------
This is about transducer current though, not resulting nerve impules. Also, the asymmetry would apply to polarity, not phase - and ultimate audibility would depend on an asymmetrical waveform.
I see two possible approaches anyway as to human hearing: actual transducer mechanisms, as above, and empirical psychoacoustics.
The first points at theoretical limits and can give order-of-magnitude kinds of estimates. Disadvantage, the field can hold significant surprises still. The active amplification was not proven until very recently, though hinted at as early as the 60's.
The empirical approach gives a direct shot at what we want to know, "can we hear it", but has a lot of credibility and study design problems, as shown by the many endless subjectivist/objectivist debates in this forum.
MBK said:...
In other words, with FR, phase, and HD/IMD, ideally from multitone bursts, we should have a lot of information already. What is missing?
I think what I was alluding to in earlier posts is missing. This is
that "standard" IM tests that have been used for years are
inadequate. They give us a false sense of security when we
use them and show that IM is well under THD. This is false and
only true in the special conditions of the test case. For instance
using two toneswith one of the two being 4:1 lower in level than
the other.
IM is really a much bigger problem when looked at
using (equal level) multitones as a magnifying glass.
Multitone bursts (as you point out) along the lines of equal level
multitones (see Czerwinski) would be good.
Mike
Hi, Francis,
With your knowledge, which amp design (hundreds which you can see here in DIYAUDIO) you consider good?
With your knowledge, which amp design (hundreds which you can see here in DIYAUDIO) you consider good?
With your knowledge, which amp design (hundreds which you can see here in DIYAUDIO) you consider good?
Really, I'm no expert - like everyone else I simply have opinions. To a very large extent the point of this conversation is to look for new ways of looking at amplifier performance, to either justify our preferences, or better, to understand where to place our efforts. With that, none of the current designs are the right answer (maybe.)
That said, there is a Pass Aleph X in my life soon. I just have a gut feeling that Nelson's designs are more intrinsically resistant to a lot of the problems than others. But that is without any real justification from deep understanding, and this opinion is no more valuable than many others you will hear, many that may well disagree.
Also, part of the point of these forums is to explore new, and perhaps slightly whacky ideas and topologies. (I have a few, and they are whacky 🙂 ) Discussions about the important distortion mechanisms seems to me to be well overdue, as a way of guiding our thoughts in narrowing down the range of interesting whacky designs.
They give us a false sense of security when we
use them and show that IM is well under THD. This is false and
only true in the special conditions of the test case.
This is very true. The problem with IM is that it is intrinsically a dynamic issue. You need a time varying change in operational characteristics of the amplifier to create them. The SMTPE test seems to be designed to test for one particular mode. Indeed I would guess (with no real justification) that it is intended to look for power supply induced modulation effects. It has the smell of a test intended to see if the PSRR was good enough to prevent ripple modulating the signal. If it got into a differential pair (which if unbalanced works as a multiplier) you would see intermodulation sum and difference bands, which is what the test looks for. That is all well and good, but it is not an IM test, it is a test for the extent of one particular IM modality.
Tests involving short tone bursts also test other modalities - i.e. TIM. But there are probably a huge number of modalities that one could find, and each would really require a targeted test to elicit. Then we would want to look to our models of hearing to decide on the impact of the modality and how best to construct a meaningful metric.
Also, part of the point of these forums is to explore new, and perhaps slightly whacky ideas and topologies. (I have a few, and they are whacky ) Discussions about the important distortion mechanisms seems to me to be well overdue, as a way of guiding our thoughts in narrowing down the range of interesting whacky designs.
Yes, it would be nice if this thread results in a real cct as outcome, as result of discussion.
What "whacky" designs do you have?
May I throw a spanner in the cogwheels?
Contributing whacky ideas:
I sometimes suspect that an optimal system should *not* perfectly reproduce the recording to technical perfection. This under the tacit assumption that one listens for the purpose of enjoyment rather than analysis of the recording.
Explanation: besides such occasional comments by professional sound engineers on forums who have "analytical" and precise systems at work, but prefer "relaxed" systems for their home use, I have also noticed that as my system gets more detailed / cleaner / "better", more and more CDs sound like a bunch of asterisks ("*****"). In some cases the recording may have defects from improper mastering, less than ideal technology etc. In other cases the sound engineers may have purposely tailored it to sound good on an *average* system, not on a *precise* system. But most importantly, the entire recording and playback chain suffers from insoluble problems: either you record by more or less close mike, and a detailed system will pick up things never meant to be heard. In addition to that, multi miking produces better detail but leads to insoluble mixing problems (phase? time delays?). Or you record "ambient", using just 2 microphones. In all but the most simple sound sources, this will lead to a recording of basically the recording venue's acoustics, not the direct source of the sound itself. As for reproduction, as said before a stereo system produces insoluble problems of positioning oneself, and without knowing how the recording was done any radiation pattern of the speaker must necessarily compromise for an "average" - some room interaction, for recordings with little ambiance of themselves, but not too much, for those recording that do have significant ambiance information. etc etc.
So, a healthy dose of muddle, noise floor and harmonics may positively contribute to a more garceful sound on the great majority of recordings. And I don't mean euphonic effects, or simply the masking effect of low order harmonic distortions onto high order ones. I simply mean, a majority of recordings may sound better on a system with modest resolution power. The optimum technology for actual musical enjoyment may lie below the best technically feasible. And maybe the olden technology (tubes, vinyl, tapes) sounds better to some than the more recent one. for this very reason.
As an alternative one could push for ultimate fidelity in reproduction, but introduce some saving grace distortions for the majority of recordings that don't benefit from it. Someone a long time ago (was it Baxandall himself? can't remember) jokingly called for a "niceness" knob. Siegfried Linkwitz, who does push for lowest possible distortion in his speakers, somewhere on his website literally says "with such a system, you can actually hear what's on the recording - and it's not always pretty". He then goes on to describe a -3 dB / decade low pass filter for relief for those kind of recordings...
Conversely, what I just said implies, and this I start suspecting more and more often, that many recordings don't sound bad to me because of my system. What I hear and don't like may actually be part of the recording.
No cynicism here, in case you wonder... just looking for the *optimal* way.
Contributing whacky ideas:
I sometimes suspect that an optimal system should *not* perfectly reproduce the recording to technical perfection. This under the tacit assumption that one listens for the purpose of enjoyment rather than analysis of the recording.
Explanation: besides such occasional comments by professional sound engineers on forums who have "analytical" and precise systems at work, but prefer "relaxed" systems for their home use, I have also noticed that as my system gets more detailed / cleaner / "better", more and more CDs sound like a bunch of asterisks ("*****"). In some cases the recording may have defects from improper mastering, less than ideal technology etc. In other cases the sound engineers may have purposely tailored it to sound good on an *average* system, not on a *precise* system. But most importantly, the entire recording and playback chain suffers from insoluble problems: either you record by more or less close mike, and a detailed system will pick up things never meant to be heard. In addition to that, multi miking produces better detail but leads to insoluble mixing problems (phase? time delays?). Or you record "ambient", using just 2 microphones. In all but the most simple sound sources, this will lead to a recording of basically the recording venue's acoustics, not the direct source of the sound itself. As for reproduction, as said before a stereo system produces insoluble problems of positioning oneself, and without knowing how the recording was done any radiation pattern of the speaker must necessarily compromise for an "average" - some room interaction, for recordings with little ambiance of themselves, but not too much, for those recording that do have significant ambiance information. etc etc.
So, a healthy dose of muddle, noise floor and harmonics may positively contribute to a more garceful sound on the great majority of recordings. And I don't mean euphonic effects, or simply the masking effect of low order harmonic distortions onto high order ones. I simply mean, a majority of recordings may sound better on a system with modest resolution power. The optimum technology for actual musical enjoyment may lie below the best technically feasible. And maybe the olden technology (tubes, vinyl, tapes) sounds better to some than the more recent one. for this very reason.
As an alternative one could push for ultimate fidelity in reproduction, but introduce some saving grace distortions for the majority of recordings that don't benefit from it. Someone a long time ago (was it Baxandall himself? can't remember) jokingly called for a "niceness" knob. Siegfried Linkwitz, who does push for lowest possible distortion in his speakers, somewhere on his website literally says "with such a system, you can actually hear what's on the recording - and it's not always pretty". He then goes on to describe a -3 dB / decade low pass filter for relief for those kind of recordings...
Conversely, what I just said implies, and this I start suspecting more and more often, that many recordings don't sound bad to me because of my system. What I hear and don't like may actually be part of the recording.
No cynicism here, in case you wonder... just looking for the *optimal* way.
MBK,
What you are searching for is Convolution DSP, and a bunch of "nicyfier" impulse responses. With that you could recreate perceived sonic character of any system you like, including one you cannot afford by far. The only requirement - you need *transparent* system to feed it through. And thats the toughest one.
What you are searching for is Convolution DSP, and a bunch of "nicyfier" impulse responses. With that you could recreate perceived sonic character of any system you like, including one you cannot afford by far. The only requirement - you need *transparent* system to feed it through. And thats the toughest one.
lumanauw said:What "whacky" designs do you have?
Forgive me if the "you" was meant to be specific 🙂
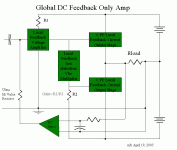
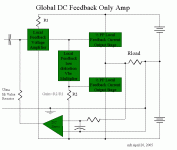
I had some thoughts on an amp that used lots of local feedback
and only global DC feedback.
The design isn't especially going to have ultra low IM. The idea
of a local feedback only amp was very intriguing before I read
the Czerwinski paper. After reading Czerwinski, I'm starting to
think again about global feedback as a means to lower IM.
Here is a block diagram.
Mike
Attachments
Now here is a really interesting paper. Hawksford again. 🙂 But this is very much the lines I was thinking about.
http://www.essex.ac.uk/ese/research... System measurement with noise and music .pdf
Interpretation could be an interesting problem, but the data will be there.
Building a system to do this as a general measurment tool would be a bit of work, but not out of the question. Some reasonsbly heavy duty calculations needed, which rather points to why such ideas are only just coming of age. (We have a site license for Matlab, but if you don't have easy access it could be an expensive proposition. But hard coding the algorithms is quite straightforward.)
http://www.essex.ac.uk/ese/research... System measurement with noise and music .pdf
Interpretation could be an interesting problem, but the data will be there.
Building a system to do this as a general measurment tool would be a bit of work, but not out of the question. Some reasonsbly heavy duty calculations needed, which rather points to why such ideas are only just coming of age. (We have a site license for Matlab, but if you don't have easy access it could be an expensive proposition. But hard coding the algorithms is quite straightforward.)
- Status
- Not open for further replies.
- Home
- Amplifiers
- Solid State
- Nature of Distortion