I won't bite 🙂
That's OK. Audio is a more difficult study than video just because we can't see it.
You're right though that the way our brains processe audio is completely different than the way we process vision. Our audio circuitry is a much older and more direct part of our brain. Linkwitz recommended a good book on the subject on his site, "This Is Your Brain On Music" by Daniel J. Levitin. Neat stuff.
SUM, here's a good paper for you to read when you have some time:
http://www.aes.org/tmpFiles/elib/20100707/5270.pdf
This was linked by Rob in the WG thread.
Dan
http://www.aes.org/tmpFiles/elib/20100707/5270.pdf
This was linked by Rob in the WG thread.
Dan
Last edited:
Singers formants
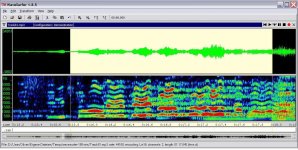
Hi FrankWW,
attached a colored sonagram taken from a recording at
Libussa von Jena - Opernsaengerin
go to "Aufnahmen" (Recordings)
The text passage of the marked voice (soprano) signal goes:
"... Staunen sieht das Wunderwerk ..."
You can download the underlying file from there if you like.
As you see clearly, the higher formants are fully pronounced
only at the phases during open articulation:
During the sung consonants they fade out, even the formats present
around the 3 Khz region, fade in and out during articulation.
The vocal tract of a singer can be seen as a filter, modifying
the glottal input signal during articulatory movement.
The "filter coefficients" change with same speed as the articulatory
movement.
As a phonetician i have seen and analysed lots of speech tracks and
this is pretty much what i expected.
Of course singing is not speaking, but during sung consonants the
higher formants fade out.
When following the formant cues, you see them rather smoothly
fading in and out, reaching a maximum in the center of the
vowel (red cues).
Pretty similar to speech i would say, but the formants itself have
more energy and there are additional and higher formants than in speech.
Voice itself and the lower formants are even maintained during
the voiced consonants like 'n', 'v' for the voiceless consonants
"t" even voice and lower formants fade out.
Not too different from speech ...
In fact speech - think of political speech ! - could have much higher
requirements in transient response of a loudspeaker
(especially at high frequencies) , because the consonants are more
pronounced.
A singer always tries to maintain voicing and keeps an aperture of the
vocal tract even for most consonants.
Nevertheless i fully agree in the range of 1..6 Khz being very important
even concerning spectral decay, this is for singing as well as for most
kinds of music.
Kind Regards
Oliver
Hi Oliver,
Actually i think i did not quote the most relevant part of that article because i was too intrigued by the information about the second formant. I didn't do a very good job. It's the 1st formant that's critical and it's usually in the area of around 3000Hz.
In my understanding it's not vowel formation which needs be the focus of attention but the singer's formant which exists "independently".
In the case of sopranos the singer's formant remains even if the vowel can no longer be produced.
We should remember singer's sounds are sustained just like any other wind instrument. This is not the same as in ordinary human speech.
If a loudspeaker has poor decay characteristics in that range, then the colour, timbre of the singer's sound will be modified audibly.
...
Hi FrankWW,
attached a colored sonagram taken from a recording at
Libussa von Jena - Opernsaengerin
go to "Aufnahmen" (Recordings)
The text passage of the marked voice (soprano) signal goes:
"... Staunen sieht das Wunderwerk ..."
You can download the underlying file from there if you like.
As you see clearly, the higher formants are fully pronounced
only at the phases during open articulation:
During the sung consonants they fade out, even the formats present
around the 3 Khz region, fade in and out during articulation.
The vocal tract of a singer can be seen as a filter, modifying
the glottal input signal during articulatory movement.
The "filter coefficients" change with same speed as the articulatory
movement.
As a phonetician i have seen and analysed lots of speech tracks and
this is pretty much what i expected.
Of course singing is not speaking, but during sung consonants the
higher formants fade out.
When following the formant cues, you see them rather smoothly
fading in and out, reaching a maximum in the center of the
vowel (red cues).
Pretty similar to speech i would say, but the formants itself have
more energy and there are additional and higher formants than in speech.
Voice itself and the lower formants are even maintained during
the voiced consonants like 'n', 'v' for the voiceless consonants
"t" even voice and lower formants fade out.
Not too different from speech ...
In fact speech - think of political speech ! - could have much higher
requirements in transient response of a loudspeaker
(especially at high frequencies) , because the consonants are more
pronounced.
A singer always tries to maintain voicing and keeps an aperture of the
vocal tract even for most consonants.
Nevertheless i fully agree in the range of 1..6 Khz being very important
even concerning spectral decay, this is for singing as well as for most
kinds of music.
Kind Regards
Oliver
Attachments
Last edited:
That sonogram also illustrates why the "telephone band" works so well. 🙂
Marcel Proust used to listen to the opera live over the telephone.
Marcel Proust used to listen to the opera live over the telephone.
You say it ! This is because human hearing is very well matched
for the perception of speech.
Although for making the formants or energy peaks around the 8Khz
region visible a more wideband sonagram would have been nice but
i had to use that software as it is.
btw. the menu entry in the above website is "The Voice" ... not "Aufnahmen",
there you can download the piece.
Kind Regards
for the perception of speech.
Although for making the formants or energy peaks around the 8Khz
region visible a more wideband sonagram would have been nice but
i had to use that software as it is.
btw. the menu entry in the above website is "The Voice" ... not "Aufnahmen",
there you can download the piece.
Kind Regards
Last edited:
What I find interesting on that graph is that although the fundamental of the note stays mostly steady, the harmonics do not. They change in pitch and amplitude during each phoneme.
Hi Panomaniac,
unfortunately i am no singer ...
But sopranists often have to sing very high tones, where the
pitch is even higher than the "normal" 1. formant for the
particular vowel would be.
Only possibility is to shift the formant frequency, so that it falls
together with the pitch or is above. Indeed the sonagram looks
like most of the intonation is realised by shifting the formants
using mandibular aperture, tongue and lips form. You can be sure
that no 2 singers sonagrams in the world look alike when singing
the same piece of music ...
The harmonics of the glottal signal are due to the waveform
of the airstream formed by the glottal vibration itself. The
airstream is a pulse sequence somewhat similar to a sawtooth
signal.
The formants are frequency regions of maximum gain and
are determined by the form of the vocal tract
(mandibular aperture, position/form of tongue, form and
aperture of the lips).
Harmonics of the glottal signal which fall into the formant
regions are gained.
There is a book from Scientific American
"Die Physik der Musikinstrumente" , is the german title
"Physics of musical instruments" might be the english one (?)
where also some basics of the singers voice are explained.
That book in total is a good read and very well illustrated.
unfortunately i am no singer ...
But sopranists often have to sing very high tones, where the
pitch is even higher than the "normal" 1. formant for the
particular vowel would be.
Only possibility is to shift the formant frequency, so that it falls
together with the pitch or is above. Indeed the sonagram looks
like most of the intonation is realised by shifting the formants
using mandibular aperture, tongue and lips form. You can be sure
that no 2 singers sonagrams in the world look alike when singing
the same piece of music ...
The harmonics of the glottal signal are due to the waveform
of the airstream formed by the glottal vibration itself. The
airstream is a pulse sequence somewhat similar to a sawtooth
signal.
The formants are frequency regions of maximum gain and
are determined by the form of the vocal tract
(mandibular aperture, position/form of tongue, form and
aperture of the lips).
Harmonics of the glottal signal which fall into the formant
regions are gained.
There is a book from Scientific American
"Die Physik der Musikinstrumente" , is the german title
"Physics of musical instruments" might be the english one (?)
where also some basics of the singers voice are explained.
That book in total is a good read and very well illustrated.
Last edited:
SUM, here's a good paper for you to read when you have some time:
http://www.aes.org/tmpFiles/elib/20100707/5270.pdf
This was linked by Rob in the WG thread.
Dan
From mentioned Toole Paper:
"A woofer under the sofa, a midrange in the ashtray,
and a tweeter in the chandelier could be equalized
to yield good sound-power or listening-room responses.
The sound quality, however, would be abysmal."

Seems like on axis response is a very important aspect, as we already know.😀SUM, here's a good paper for you to read when you have some time:
http://www.aes.org/tmpFiles/elib/20100707/5270.pdf
This was linked by Rob in the WG thread.
Dan
Seems like on axis response is a very important aspect, as we already know.😀
And i think no one seriously doubted that ...
"
Interpreting the data, after that much processing, is
relatively straightforward, involving looking for a flat
bandwidth on-axis response, and for consistently
repeated patterns in the family of progressively off-
axis measurements. The importance of the deviations
from the underlying smooth contours must be weighted
according to a set of rules that take account of the
direction, shape, and magnitude of the irregularities
and the frequencies at which they occur. The result,
is a ranking of loudspeaker performance
that has about the same resolution and order
as listening tests conducted with the utmost of care,
and with considerably more time and expense.
This is not to say that amplitude response is the only
important measurement. It is, however, indicating that
through this one dimension it is possible to indirectly
observe behavior in another. ...
"
I like the formulation "consistently repeated patterns" in
off axis responses.
This formulation does not call for a certain type of dispersion pattern.
Such consistent behaviour can also be matched by a wide range
driver without severe breakup modes e.g. which narrows smoothly
with frequency. Furthermore it does not exclude dipoles or omnis,
as far as i understand it. In fact it includes waveguided designs
because they can match the formulation very good if implemented
in "CD like" manner. But it does not call for a certain technique.
It imposes serious doubts on the still common 2- or 3-way box
speaker having no means to harmonize directivity of the drivers
at crossover. And that is the point which should let us start thinking:
The most common designs on the market - even in the upper price
regions - do NOT conform to these more than 20 year old findings.
Last edited:
Toole himself states that there is little here not already known; the value lies in sorting and prioritizing what correlates with listener preference.... 
Toole himself states that there is little here not already known; the value lies in sorting and prioritizing what correlates with listener preference....
... and also any thing that might be dear to some audiophile's (or manufacturer's) heart but doesn't correlate with listener preference.
Some people will rush to judgment, pointing out correspondences between what they think they hear and what they think they see on data-pictures. These correspondences can be accidental.
In some preference tests - like Olive's, truly awful speakers could be in the test mix. They might show this or that yuccky trace (say, off-axis lobes or lack bass) but they might also have a great many other defects of design. In which case, no conclusions ought to be drawn about what particular defect made them sound lousy. In this case, we say the shortcomings are either all from a common cause or they are simply present randomly.
Last edited:
Do not assume the work ended 25 years ago.
Literally thousands of tests have validated its findings since, and the metric is continually refined....
Literally thousands of tests have validated its findings since, and the metric is continually refined....
Last edited:
I'm curous, has anyone looked into Modulation Transfer Function? I came across this while reading the Newell and Holland book on Loudspeakers, but really could not find much application of it in audio. Seems the only papers written about it was by DRA labs and implemented in MLSSA. So it's either too usefull that it's a killer, or it's too useless to care about, or even it's so complicated an issue that people have not studied it in depth.
Ben, that's an interesting point. It's interesting that some poor measuring speakers in those tests are extremely expensive and do much better subjectively during sighted listening than blind. The fact that so many studies have been done with the same results definitely suggests something. When you think about it, it seems common sense that evenly loading the room should work well. It may not be the end all be all, just a very useful bit of info that is so often overlooked or completely ignored in the commercial and DIY sector. That seems to be changing in DIY and some of the commercial sector as well. Just look at how many threads have headed toward smooth off axis responses on so many boards and how long and often heated those discussions become. Typically not love fests from what I've read.
Dan
Dan
Ben, that's an interesting point. It's interesting that some poor measuring speakers in those tests are extremely expensive and do much better subjectively during sighted listening than blind. The fact that so many studies have been done with the same results definitely suggests something. When you think about it, it seems common sense that evenly loading the room should work well. It may not be the end all be all, just a very useful bit of info that is so often overlooked or completely ignored in the commercial and DIY sector. That seems to be changing in DIY and some of the commercial sector as well. Just look at how many threads have headed toward smooth off axis responses on so many boards and how long and often heated those discussions become. Typically not love fests from what I've read.
Dan
Yeah, what I said is just plain research logic of the most ordinary sort.
As you say, any speaker test not done blind/anonymously has little value. Called in the trade "halo effect." (Of course, there may be some test designs that are exceptions or where reputation or group-evaluation is used deceptively.)
And doubly so, when our own egos are on-the-line.
A Geddes speaker, just for illustration, may be superior in a great many ways (very impressive crossovers, air-core of the best sort if I recall). So hard to say which factors matter... or factors not yet identified or even just overlooked.
That is why when things are complex like speakers and rooms, it is often the absolutely simplest "experiments" can be the most discerning when just a single factor is varied in a plain and/or systematic way. And when thought-out carefully, piece of cake to run.
I spent all day today at a respected Canadian Defence lab (Downsview) so I am real logical tonight. Seems the lab at Shirley Bay (Ottawa) has an under-used anechoic chamber - they rent it out but couldn't tell me the rate. Lotsa Canadian speaker interest... might bring some bucks to DND.
Last edited:
When you think about it, it seems common sense that evenly loading the room should work well. It may not be the end all be all, just a very useful bit of info that is so often overlooked or completely ignored in the commercial and DIY sector.
There are just two distinct schools of thought. When you get a chance browse through the Stereophile Speaker reviews and have a look at the measurements. It's clear where companies stand and frankly just how far apart they stand as far as what makes a good speaker. Some of the most expensive systems look not too good in the measurements section. I think the point from the designers view that it is a "Statement Speaker" so it's voiced to a unique personal view. The kicker is some of these designs have elaborate driver aiming capability that is not as effective as it could be if they paid more attention to the off axis response. You can see the off axis issues in the room averages that JA does.
Rob🙂
Just got to say this- been in audio for ever and have surveyed around 2500 people who have money to spend. Statistically the only decent correlation I have ever found is the groups I keep mentioning. Those who prefer the podium and all that it brings with it, front row center, row five center, row 13 center, and the one in the back or under the balcony. People often want to reproduce in their rooms what they experience in live performance. This has pretty much always been the result breaking into these sub groups from listeners with money to spend. Now I know that is not everyone. It does speak to room acoustics and speaker performance preferences and it is back to this one size does not fit all.. Consider the experience of the listener and it only seems natural that any particular listener might well want to create in their home the sound they hear in the performance spaces they experience. Of those 2500 about 100 have said outright "I want it to sound like what I hear at the hall."
With this in mind let us focus on the group we each belong to and quit trying to beat the square peg into the round hole, as the saying goes. I am the up at the podium guy. Ladies and gentlemen, choose your seats!
=SUM
With this in mind let us focus on the group we each belong to and quit trying to beat the square peg into the round hole, as the saying goes. I am the up at the podium guy. Ladies and gentlemen, choose your seats!
=SUM
No such thing as playing Carnegie Hall in my living room. No such thing. Not definable. About as meaningful as asking if an old man dying will be an old man when he wakes in heaven.
About criteria of quality, there's a whole field called "experimental esthetics."....
There are kind of two kinds of parameters. First, there are some that certain people agree are worthwhile, like low distortion (except my son, the rocker who LIKES distortion). So you can look for physical correlates that people seem to mean when they say "low distortion" which may or may not be same as your distortion meter. Sometimes "accuracy" is a proxy for quality.
Then there are some which really are matters of taste and there's just no disputing those values even if you can establish measurements. Gosh, I love my ESL tweeters that sizzle guitar strings like Martin Logan's in good weather.
A further issue is the extremely complex question of stuff like Fletcher-Munson curves which have no simple resolution. There is no defensible engineering solution to how loud my woofer should be at 30 Hz. Purely a matter of ????
About criteria of quality, there's a whole field called "experimental esthetics."....
There are kind of two kinds of parameters. First, there are some that certain people agree are worthwhile, like low distortion (except my son, the rocker who LIKES distortion). So you can look for physical correlates that people seem to mean when they say "low distortion" which may or may not be same as your distortion meter. Sometimes "accuracy" is a proxy for quality.
Then there are some which really are matters of taste and there's just no disputing those values even if you can establish measurements. Gosh, I love my ESL tweeters that sizzle guitar strings like Martin Logan's in good weather.
A further issue is the extremely complex question of stuff like Fletcher-Munson curves which have no simple resolution. There is no defensible engineering solution to how loud my woofer should be at 30 Hz. Purely a matter of ????
Last edited:
- Status
- Not open for further replies.
- Home
- Loudspeakers
- Multi-Way
- Measurements: When, What, How, Why