My EQ experiments ended up in that yes, 1 dB matter. Even less. This is why it is not accurate enough for development given how it is quite easy to make it differ 1 dB. And given the comparative enormous impact of a room makes it unnecessarily accurate as when you design for the last dB, the room will destroy all your efforts...
//
//
Your messages seem to contradict each other a lot.My EQ experiments ended up in that yes, 1 dB matter. Even less. This is why it is not accurate enough for development given how it is quite easy to make it differ 1 dB. And given the comparative enormous impact of a room makes it unnecessarily accurate as when you design for the last dB, the room will destroy all your efforts...
//
Anyway, there is no way that 0.5-1 dB will be the difference of night and day.
I personally even really doubt (most) people would spot such details clearly and obviously in a double blind ABX test, but that is a whole different story. (not important for the argument)
You even say yourself that the room, even just placing a speaker slightly different, gives a bigger error.
Maybe it's just the way your write it, but I think you mean that this means that all those details don't really matter in measuring systems?
Because that is not really the way you sound atm 😀
Also conflicting, because at the same time you do seem to care about the difference in the graphs?
I downloaded REW and bought a Behringer ECM8000 Measurement Condenser Microphone. I measure outside and in my room which has absorbers and bass trap.
So bloody annoying not being able to edit posts after a while 😡😡😡And that is exactly the point!
It's not about who is better than who.
It's about collecting data and learning from it.
The most important factor in any (scientific) experiment, is being honest about it.
Which very often doesn't mean the whole dataset is wrong, as long as you keep it into consideration.
What's the reason Amir doesn't use calibration files though?
Even mics have a small bafflestep, so data is always different that way.
btw, the 1/20the per octave is the given smoothing.
However on top of that, there is certain line smoothing as well.
This is the interpolation between data points (besides the octave smoothing)
REW does something very similar.
If you measure the same thing with REW vs ARTA and show the data with the same smoothing, REW measurements look a lot "smoother" than ARTA.
As an example, Way WAY back, this used to be a think in Excel as well.
Ever since Excel 2007, there was a graph smoothing applied to data, to make it "less jittery"
Programs use the same kind of code it seems for graphs.
Anyway, what I wanted to add, is that in the Revel measurements, one of the graphs clearly has more "smoothing" on it.
The differences in the graphs (amir vs erin) are big enough to make a SQ difference if you did the same alterations in a EQ session. Yet two different NFS users cant come in within 1 dB measuring the same speaker - that disqualifies it for a designer wanting to know what the speaker will do. Thats one observation. An other is that a speaker designer using NFS would do an adjustment of say 0.8 dB and then a room makes 4 dB one. Cant you see the contradictions....Your messages seem to contradict each other a lot.
Anyway, there is no way that 0.5-1 dB will be the difference of night and day.
I personally even really doubt (most) people would spot such details clearly and obviously in a double blind ABX test, but that is a whole different story. (not important for the argument)
You even say yourself that the room, even just placing a speaker slightly different, gives a bigger error.
Maybe it's just the way your write it, but I think you mean that this means that all those details don't really matter in measuring systems?
Because that is not really the way you sound atm 😀
Also conflicting, because at the same time you do seem to care about the difference in the graphs?
For me thats not accurate enough for a designer with a +/-0,5 dB ambition but way overkill for what happens to the speaker in a room. Its the designer vs. user perspective that is somehow off.
I will end with this 🙂 perhaps I'm wrong in my view... I'll think about it again.
//
Is it the *exact same loudspeaker, or the same model of loudspeaker?
*(..including left vs right loudspeaker.)
*(..including left vs right loudspeaker.)
I don't see how this disqualifies anything? And again it doesn't make sense if you say that it doesn't matter at the same time?The differences in the graphs (amir vs erin) are big enough to make a SQ difference if you did the same alterations in a EQ session. Yet two different NFS users cant come in within 1 dB measuring the same speaker - that disqualifies it for a designer wanting to know what the speaker will do. Thats one observation. An other is that a speaker designer using NFS would do an adjustment of say 0.8 dB and then a room makes 4 dB one. Cant you see the contradictions....
For me thats not accurate enough for a designer with a +/-0,5 dB ambition but way overkill for what happens to the speaker in a room. Its the designer vs. user perspective that is somehow off.
I will end with this 🙂 perhaps I'm wrong in my view... I'll think about it again.
//
It still gives us plenty of other very important information, which is the overal and global performance of a speaker.
Mostly how the directivity and overal frequency response is of a loudspeaker.
Which is far more important than those little discrepancies.
On the other hand, I do agree with the discussion WHY there is such a big difference.
But Erin already explained a little bit.
About the ±0.5dB "ambition". It's a very weird and non-saying argument and goal within the whole context.
As can be read even in your own signature "You listen to a system, not individual components.".
So a system could be "accurate" within ±0.5dB, but when the directivity is still a mess, it's still a bad system.
Besides what does it even mean to be "±0.5dB accurate?" In what context, just the frequency measurements?
Or also the yield and production errors?
In the bigger picture, measuring in different anechoic chambers would most likely get a lot less consistent results.
In other words, there is no person on this planet being able to get 100% percent accurate results.
In fact, although that's a more philosophical/physics argument, that is by definition not even possible.
Same model, not exactly the same speaker.Is it the *exact same loudspeaker, or the same model of loudspeaker?
*(..including left vs right loudspeaker.)
But it's an interesting point, because I would like to see something like at least ten speakers of the same model on the same measuring setup.
Although I already have experience with this. Years ago I did a batch measurement for a certain company.
I think I measured 20-25 speaker in total and did some SD as well as SEM calculations on this.
The total error from that was an awful lot more than the difference we are talking about here.
That was also with high-end major brand parts.
Well then, that can easily account for the difference. (..even between two louspeakers (as a pair) L&R there are often substantive differences.)
It seems to me that you think it is possible to make repeatable acoustic measurements that have zero margin for error or tolerance. It is extremely difficult to calibrate and maintain a tolerance of +/- 0.5dB.The differences in the graphs (amir vs erin) are big enough to make a SQ difference if you did the same alterations in a EQ session. Yet two different NFS users cant come in within 1 dB measuring the same speaker - that disqualifies it for a designer wanting to know what the speaker will do. Thats one observation. An other is that a speaker designer using NFS would do an adjustment of say 0.8 dB and then a room makes 4 dB one. Cant you see the contradictions....
For me thats not accurate enough for a designer with a +/- 0,5 dB ambition but way overkill for what happens to the speaker in a room. Its the designer vs. user perspective that is somehow off.
I will end with this 🙂 perhaps I'm wrong in my view... I'll think about it again.
//
Whilst it is possible to hear the difference of very small level changes when they occur over a large frequency band, measuring that repeatedly even in the same place with the same equipment at the same time is difficult. Check out the Neumann KH80 measurements on ASR and how the temperature of the measuring space affected the bass tuning.
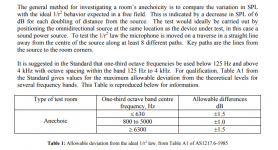
Attached is an image of tolerances for a room to be considered anechoic.
The NFS is not a piece of calibrated lab gear, where you press a button and it spits out a result. Erin has pointed out some of the differences between how he has set his up and Amir chose to do it. Like any piece of equipment the operator still has a decent chance to affect the result.
Attachments
I would like to see ten sets of measurements of the same speaker sample after removing and replacing it on the NFS between each measurement cycle.Same model, not exactly the same speaker.
But it's an interesting point, because I would like to see something like at least ten speakers of the same model on the same measuring setup.
But the graphs aren't measurements of the same speaker sample. One cannot determine the causes of the differences from those graphs.The differences in the graphs (amir vs erin) are big enough to make a SQ difference if you did the same alterations in a EQ session. Yet two different NFS users cant come in within 1 dB measuring the same speaker - that disqualifies it for a designer wanting to know what the speaker will do.
Guys, like Erin, fluid and I keep saying throughout this thread, the operator still matters when using the NFS. The point is that throughout development you would get consistent data with the device. I also don’t think it’s necessary to get full spins throughout the design process. Reliable 0-90 horizontal is all you need for VCad work, the full spin is pretty much final confirmation of the design. Time spent measuring goes from hours to under a minute.
The room won’t make 4dB difference in direct sound though, your brain will distinguish between direct and reflected sound, a microphone won’t.The differences in the graphs (amir vs erin) are big enough to make a SQ difference if you did the same alterations in a EQ session. Yet two different NFS users cant come in within 1 dB measuring the same speaker - that disqualifies it for a designer wanting to know what the speaker will do. Thats one observation. An other is that a speaker designer using NFS would do an adjustment of say 0.8 dB and then a room makes 4 dB one. Cant you see the contradictions....
For me thats not accurate enough for a designer with a +/-0,5 dB ambition but way overkill for what happens to the speaker in a room. Its the designer vs. user perspective that is somehow off.
I will end with this 🙂 perhaps I'm wrong in my view... I'll think about it again.
//
Time to revisit this old clip:
At 13:47 timestamp your above remark is debunked. As speakers which are placed in different places/locations are rated differently in blind tests. There's something called the Haas limit. This Haas limit won't be one exact number in time, it will vary somewhat with frequency, but the room will make a change to the direct sound, big enough for us listeners to pick up on.The room won’t make 4dB difference in direct sound though, your brain will distinguish between direct and reflected sound, a microphone won’t.
Time to revisit this old clip:
Just record your favorite speaker at the listening spot and listen to it over headphones. You'll notice the room while listening to those headphones much more than at that listening spot itself. But that don't make it true that the room itself doesn't change what we hear. We adapt to the room. But just place the speaker at a different spot in the room and the tonal balance you hear will change! But it doesn't change the fact that the room has this much influence, it verifies that the room can change what we hear. It's just that we adapt to the room and it's sound stamp. (see 19:26) Your neighbor will still sound like your neighbor when he walks into your room. That's one of the ways how we learn(ed)...

If we talk about 0.5dB differences even shipping a unit, meaning the product will go mechanical stress, as well as differences in mounting, humidity and temperature could cause these differences (at certain frequencies)Yeah, I would like to ask amir and erin to measure the same sample and compare the result.
But IF it's true that Amir doesn't use a calibration file. That's already a big chunk right there.
I already regret putting up that old video. As you point out one criticism of Olive/Toole is the testing protocol where speakers are pushed out on mechanical sleds at arbitrary positions.At 13:47 timestamp your above remark is debunked. As speakers which are placed in different places/locations are rated differently in blind tests. There's something called the Haas limit. This Haas limit won't be one exact number in time, it will vary somewhat with frequency, but the room will make a change to the direct sound, big enough for us listeners to pick up on.
Just record your favorite speaker at the listening spot and listen to it over headphones. You'll notice the room while listening to those headphones much more than at that listening spot itself. But that don't make it true that the room itself doesn't change what we hear. We adapt to the room. But just place the speaker at a different spot in the room and the tonal balance you hear will change! But it doesn't change the fact that the room has this much influence, it verifies that the room can change what we hear. It's just that we adapt to the room and it's sound stamp. (see 19:26) Your neighbor will still sound like your neighbor when he walks into your room. That's one of the ways how we learn(ed)...
Makes some speakers sound really cr*p.
I've tested hundreds of speakers and raw driver pairs. I can tell you from experience that it is not uncommon to have differences between a pair of speakers/drivers that is greater than +/- 1dB. Even the impedance can vary.
If you look at some of the drive unit test results that Vance Dickason provides in his reviews for Voice Coil Magazine you'll also see that even high-end (high cost as well) drive units from the likes of Scan Speak and BlieSma have differences of at least +/- 0.50dB and many other drivers can have more than +/-1dB variance between sample pairs. Therefore, you can't say that two different speakers, measured by two different sources is different because of user error/environment/setup alone. The fact is, most speaker/driver pairs aren't even matched to within +/-1dB; the difference is there when it leaves the factory.
If you look at some of the drive unit test results that Vance Dickason provides in his reviews for Voice Coil Magazine you'll also see that even high-end (high cost as well) drive units from the likes of Scan Speak and BlieSma have differences of at least +/- 0.50dB and many other drivers can have more than +/-1dB variance between sample pairs. Therefore, you can't say that two different speakers, measured by two different sources is different because of user error/environment/setup alone. The fact is, most speaker/driver pairs aren't even matched to within +/-1dB; the difference is there when it leaves the factory.
- Home
- Loudspeakers
- Multi-Way
- How much would YOU pay for Klippel service?