Hi Ken,Hi, Kostas,
A typical transmitted 2-channel digital audio data frame is serial, and consists of a total of 64-bits per 2-channel data frame. That's 32-bits (called a, half-frame) for each of the two channels. Together, the 64-bit frame represents a single matching pair of stereo samples, transmitted serially one after the other in a time-multiplexed fashion. For example, serially, 1Left/1Right, 2Left/2Right, 3Left/3Right, etc. The three samples above represent a total of 3X64-bits = 192 serial audio bits.
This 64-bit frame per 2-channel sample pair format is the same for 16-bit CD samples, as it is for up to 32-bit high-rate samples. When the received sample data resolution exceeds that of a given DAC chip's ability to quantize, the extraneous bits are either dithered (the proper way) to fit the quantizer's capability, or are simply truncated (ignored) to fit. So, for example, should the maximum 32-bit sample be sent to a 16-bit capable DAC, the sample will typically be accepted by the DAC, but will be reduced to 16-bits either by dithering or by truncation before arriving at the DAC chip's 16-bit quantizer unit.
Allow me to give some comment to your contribution.
Sending PCM Audio is defined in the AES-3 protocol, which is indeed 32bits per sample, but contains in standard form only 20 bits for audio with the option to extend this to 24 bit.
The rest of the bits are reserved for synchronisation etc.
So it seems not possible to send 32 bit audio at all over USB, AES/EBU or SPDIF, because all are conforming to AES-3.
After having decoded the AES-3 protocol in the DIR (Digital audio Interface Receiver) , data can be converted into I2S, which has a separate BCK, LRCK and Data and can handle up to 32 bits data.
So it seems that when you don't have a direct I2S connection to DAC, which requires three wires, without any USB or whatever converter in between, that you have to conform to the 24 bits max that AES-3 can transmit.
I must say, this is a complex and slippery road, because if true, the ratio of using 32 bit audio files would become questionable.
Hans
This is what Bob Katz, a famous recording engineer has to say on the subject:
I won't say I am an absolute expert on dithering, but I am known as an "authority". Clearly, the longer the wordlength is that you truncate to, the less the potential difference between dithering and truncation. For example, the processing in Pro Tools HD is 48 bits fixed point. This can be either dithered to 24 bits using one mixing module or truncated to 24 bits using another. The sonic differences between the two are very subtle, but the dithered mixer wins. There are some crazies out there who prefer the truncated mixer, I say, just as a disclaimer.
Also, keep in mind that the noise of dither is usually inaudible, but the artifacts of not dithering (distortion, loss of depth, loss of soundstage and loss of warmth) are audible. It's also a matter of ear-training. Most people are first trained to recognize timbre, but soundstage depth and dimension, far more subtle quantitles, are what are lost first when truncation is performed instead of dithering.
Next, keep in mind that it doesn't matter if it's a 64-bit engine or a 24-bit engine if it isn't doing any calculation, that is, if there are no filters, EQ, convolution or volume control in the chain. It will take in up to 24-bit information and put it out. But if there is calculation, then all the low-level information in the source is EXPANDED downward into the low level bits of the resulting wordlength, with each little bit being 6 dB less significant. At some point, truncation versus dithering becomes an inaudible difference. But as long as JRiver has a 64-bit engine, then why not generate 64-bits worth of dither information with the amplitude set to 24-bit, and truncate at 24 and not worry where it's safe to cut off.
Hey, wait a minute? Did you know that all current Lame and Fraunhofer and Apple AAC and MP3 decoders run internally at 32-bit floating point? In fact, if you take a "16-bit" source AAC file and reproduce it through the AAC decoder, it produces a 32-bit float output word! If it was a very good encoding, you will lose audible depth if you reproduce it at 16-bit because more than 16-bits come out of the decoder. The output of an AAC decoder should therefore be dithered down from 32-bit float to 24-bits for best reproduction. Almost NO ONE does that, but they should, and I've heard the audible difference when I play AAC in an engine that permits that. I can only do this to a limited extent when I'm doing some test encoding in OSX, I'm not sure how to handle this on the PC, but I'll bet Matt has an inkling. Anyway, in the case of JRiver, I don't know how they handle floating point, perhaps they just take the information from the decoder and turn it into fixed point, but at the least you should take 24-bit fixed from the decoder, and preferably, work in floating point until the end, when you should dither from 64-bits down to 24 for reproduction. Even a so-called "bit-transparent volume control" can't defy the laws of physics and mathematics. When it's a 0 dB it can be EXACTLY bit-transparent, and that does test the accuracy of the code. But, for example, when taking a 16-bit source and attenuating it 1 dB, the output of the volume control will be, potentially, as much as 64-bit, the length of his calculation engine. But certainly the math error truncating at such a long wordlength will be very small. At that point it must be dithered down. Then I would call it a "high resolution volume control" rather than "bit transparent" and it would more accurately reflect what is really going on. And that's what we want anyway, since bit-transparency is not technically possible if any multiplication takes place, it's against the laws of math.
Can we hear truncation at 24 bits (versus dithering)? I can --- on a good day I can pass a blind test on it, with the right musical material. Is it a hard test to pass? YES IT IS! It is the hardest and probably one of the most subtle differences that you will ever be asked to hear or judge. Does this mean that it's insignificant? I like to think that any sonic difference which some small percentage of the population can hear is significant. At least it should be important to an audio engine as critical and designed for critical listeners as JRiver is. It's not a big deal to take an engine which already properly dithers to 16-bit and extend it to 24-bit, so I think it should be done, and then give the users the opportunity to choose truncation or dithering and decide for themselves. Or, better yet, leave dithering on and just enjoy. You won't hear the noise (24-bit dither is at -141 dBFS RMS!) but you will hear a reduction of artifacts, if your system is good enough to reproduce them.
I won't say I am an absolute expert on dithering, but I am known as an "authority". Clearly, the longer the wordlength is that you truncate to, the less the potential difference between dithering and truncation. For example, the processing in Pro Tools HD is 48 bits fixed point. This can be either dithered to 24 bits using one mixing module or truncated to 24 bits using another. The sonic differences between the two are very subtle, but the dithered mixer wins. There are some crazies out there who prefer the truncated mixer, I say, just as a disclaimer.
Also, keep in mind that the noise of dither is usually inaudible, but the artifacts of not dithering (distortion, loss of depth, loss of soundstage and loss of warmth) are audible. It's also a matter of ear-training. Most people are first trained to recognize timbre, but soundstage depth and dimension, far more subtle quantitles, are what are lost first when truncation is performed instead of dithering.
Next, keep in mind that it doesn't matter if it's a 64-bit engine or a 24-bit engine if it isn't doing any calculation, that is, if there are no filters, EQ, convolution or volume control in the chain. It will take in up to 24-bit information and put it out. But if there is calculation, then all the low-level information in the source is EXPANDED downward into the low level bits of the resulting wordlength, with each little bit being 6 dB less significant. At some point, truncation versus dithering becomes an inaudible difference. But as long as JRiver has a 64-bit engine, then why not generate 64-bits worth of dither information with the amplitude set to 24-bit, and truncate at 24 and not worry where it's safe to cut off.
Hey, wait a minute? Did you know that all current Lame and Fraunhofer and Apple AAC and MP3 decoders run internally at 32-bit floating point? In fact, if you take a "16-bit" source AAC file and reproduce it through the AAC decoder, it produces a 32-bit float output word! If it was a very good encoding, you will lose audible depth if you reproduce it at 16-bit because more than 16-bits come out of the decoder. The output of an AAC decoder should therefore be dithered down from 32-bit float to 24-bits for best reproduction. Almost NO ONE does that, but they should, and I've heard the audible difference when I play AAC in an engine that permits that. I can only do this to a limited extent when I'm doing some test encoding in OSX, I'm not sure how to handle this on the PC, but I'll bet Matt has an inkling. Anyway, in the case of JRiver, I don't know how they handle floating point, perhaps they just take the information from the decoder and turn it into fixed point, but at the least you should take 24-bit fixed from the decoder, and preferably, work in floating point until the end, when you should dither from 64-bits down to 24 for reproduction. Even a so-called "bit-transparent volume control" can't defy the laws of physics and mathematics. When it's a 0 dB it can be EXACTLY bit-transparent, and that does test the accuracy of the code. But, for example, when taking a 16-bit source and attenuating it 1 dB, the output of the volume control will be, potentially, as much as 64-bit, the length of his calculation engine. But certainly the math error truncating at such a long wordlength will be very small. At that point it must be dithered down. Then I would call it a "high resolution volume control" rather than "bit transparent" and it would more accurately reflect what is really going on. And that's what we want anyway, since bit-transparency is not technically possible if any multiplication takes place, it's against the laws of math.
Can we hear truncation at 24 bits (versus dithering)? I can --- on a good day I can pass a blind test on it, with the right musical material. Is it a hard test to pass? YES IT IS! It is the hardest and probably one of the most subtle differences that you will ever be asked to hear or judge. Does this mean that it's insignificant? I like to think that any sonic difference which some small percentage of the population can hear is significant. At least it should be important to an audio engine as critical and designed for critical listeners as JRiver is. It's not a big deal to take an engine which already properly dithers to 16-bit and extend it to 24-bit, so I think it should be done, and then give the users the opportunity to choose truncation or dithering and decide for themselves. Or, better yet, leave dithering on and just enjoy. You won't hear the noise (24-bit dither is at -141 dBFS RMS!) but you will hear a reduction of artifacts, if your system is good enough to reproduce them.
So in the uncertainity where truncation and/or dithering from 32 bits to 24 bits is taking place, the safest thing to do seems the use of 24 bit dithered files.
Hans
P.S. the use of digital volume control is also not advised because the all important dither will be pushed below the LSB level.
Hans
P.S. the use of digital volume control is also not advised because the all important dither will be pushed below the LSB level.
Last edited:
This is what Bob Katz, a famous recording engineer has to say on the subject: .......Can we hear truncation at 24 bits (versus dithering)?..... You won't hear the noise (24-bit dither is at -141 dBFS RMS!) but you will hear a reduction of artifacts, if your system is good enough to reproduce them.
How can the human brain perceive noise artefacts at such low levels?
.....
So it seems not possible to send 32 bit audio at all over USB, AES/EBU or SPDIF, because all are conforming to AES-3......
AES-3 is pre-USB tech. Why would AES-3 be used for USB?
Last edited:
It is very well possible that USB has more options.
I think that many would be interested if you could tell the details
But anyhow, in all cases where USB is translated into SPDIF, AES/EBU, Toslink, ST fiber or whatever, AES-3 will be leading.
And as Bob Katz mentions, it is not the dither he heard in a 24bit file but the absence of dither causing sound modulated noise.
Hans
.
P.S. when is your PM to be expected with your findings from comparing 88.2 versus 176.4?
I think that many would be interested if you could tell the details
But anyhow, in all cases where USB is translated into SPDIF, AES/EBU, Toslink, ST fiber or whatever, AES-3 will be leading.
And as Bob Katz mentions, it is not the dither he heard in a 24bit file but the absence of dither causing sound modulated noise.
Hans
.
P.S. when is your PM to be expected with your findings from comparing 88.2 versus 176.4?
.... I use the digital volume control in my system via the keyboard. ....I can't tell if this could make any difference between 24 and 32bit either.
All digital volume control alters the bit encoding. The signal then falls into the noise floor. If you cant hear noise it doesnt matter for recreational listening. However if doing critical testing of files with different bit depths using digital volume will create validity issues.
This is a bit abstract when your DAC chip only accepts 24bits max anyway.
My Denafrips DAC upsamples everything. Seems like Denafrips "NOS" mode is actually OS 768khz upsampling from independent measurements! As I dont have a NOS DAC I disqualified myself being able to compare your files with the care they deserve. Is that OK?when is your PM to be expected with your findings from comparing 88.2 versus 176.4?
Please see below a copy and paste of a highly relevant report from John Swenson, on a different forum nearly ten years ago. Ive bolded and underlined important points for speed readers convenience. I hope this copying isn't out of order and hope John and diyaudio folk don't object to this? Please ask a moderator to kindly delete this if it offends.
RE: Question about DSP and Filtering
I have been thinking hard about how to reply to this, it's a complex subject.
- Posted by John Swenson (A) on July 20, 2012 at 15:54:49 In Reply to: Question about DSP and Filtering posted by Dynobot on July 14, 2012 at 09:42:38:
I think I'm going to go with the abreviated version and try and keep it short. That means there is going to be a lot left out unfortunately, but hopefully it will cast some light on how I'm thinking about this.
It all goes back to a bunch of experiments I did many years ago with regards to digital filters in DAC chips and NOS DACs etc. I won't bore you with the details, but the conclusion was that done right NOS significantly improves the sound IN SOME WAYS, and makes it worse in others. The sound is richer, more alive, conveys more of the emotional impact from the performers, BUT it sounds "dirty" around the edges, particularly in the high frequencies. Some people think it's a good compromise, others do not. The dirtiness is obviously the results of the high frequency aliasing caused by the unfiltered output. But why does getting rid of aliasing get rid of the "richness, emotional impact etc"?
After a lot of experimentation I came to the conclusion it was the digital filters themselves. Every single one of the hardware filters I looked at in DAC chips (and external ones as well, such as the DF1704) were compromised in some way. My supposition is that in order to cut costs in the chips the designers cut corners in the implemention. They are required to meet certain numbers in the spec sheet, and they can't do it properly and still stay on budget, so they cheat and play tricks in order to get good numbers.
In this forum there have been a lot of statements along the lines of "Shannon says that the filter will accurately reproduce the original waveform", but many are saying it doesn't sound that way, and others keep on saying the theorum is correct, I think this is reason for the dichotomy, the actual hardware implementations in most cases are NOT properly implementing the filter.
I have tested this hypothesis in two ways: creating my own digital filter in an FPGA and using software to do the filtering on the file. In both cases I have used two different DACs that I have built myself. One uses 1704 DAC chips (which do not have a filter) and the other uses a 1794 which does have a digital filter, but it can be turned off. Both use very low jitter local clocks, very low noise power supplies etc. For the 1704 I can feed the data directly (NOS), from a FPGA digital filter, or through a DF1704. For the 1794 DAC I can use either its internal filter, or bypass the internal filter and send direct, or use the FPGA filter.
The results of all this was that with both DACs using either the internal filter or the DF1704 produced very clean sound but it was lacking richness, aliveness etc. Stright NOS in both cases gave the richness, aliveness, but dirty sound. Using either the FPGA filter or filtering in software gave the best of both worlds, it still had the richness and aliveness, but was clean. This sound difference is NOT subtle it is almost starteling. Everyone who has heard this invariabley says something along the lines of "now THIS is what it is supposed to sound like".
I tried several programs to do the filtering in software, and they all did similar things. I wan't using any special audiophile programs, just the normal resampling algorithms in programs such as SOX etc. Yes you can hear slight differences between them, but they all sounded way better than straight NOS or filtering in the DAC chip.
Now all that was the explanation for my comments about filtering and Tony's player. To get the best sound I don't want to use filtering in the DAC chip, that leaves implementing my own filter in an FPGA or resampling in software external to the player. Doing it in the FPGA takes a lot of hardware resources and fast clocks which flies in the face of the concept "absolutely as little going on as possible", so the best bet would be resampling in software and sending the higher sample rate files to the player. The higher sample rate files take more memory accesses, it will be interesting to see if that is any better than the extra stuff going on in the FPGA for a hardware filter. My guess is that the esternal software filtering will sound slightly better.
Whew, that was long winded, but that was about as concise as I could get and still cover the material.
John S.
John had a similar question to this thread about what makes NOS sound different and built two NOS DACs one R2R and one noise-shaping (PCM1794 just like DDAC in above posts) to test his hypothesis:
Very interesting post, thanks for sharing. FYI for those who don't know, the Bottlehead DAC produced a few years back was designed by John Swenson, and is exactly that, an XMOS processor running his digital filter, and feeding the output to a PCM5142 in pass though mode for the output stage. Wonderfull sounding little DAC that is little understood or appriciated.
So in the uncertainity where truncation and/or dithering from 32 bits to 24 bits is taking place, the safest thing to do seems the use of 24 bit dithered files.
Hans
P.S. the use of digital volume control is also not advised because the all important dither will be pushed below the LSB level.
All digital volume control alters the bit encoding. The signal then falls into the noise floor. If you cant hear noise it doesnt matter for recreational listening. However if doing critical testing of files with different bit depths using digital volume will create validity issues.
This is a bit abstract when your DAC chip only accepts 24bits max anyway.
I'm aware of the digital volume control issues, that is in general of course. That's why I wanted to make clear I'm using it. From there on decisions have to be made about the type of volume control that is best to use. No doubt you know these things better, I just strive for decent sound more close to "high resolution" rather than "bit transparent". In other words, some noise is OK as long as dynamic range is not lost. How much could afford to loose? It's a big discussion to fit in this thread.
I wouldn't say I can hear any difference between 16 and 24 bit files... again in general. I wouldn't qualify my system and ears capable to tell the difference between 24 and 32 bit. Especially since theory is against to that. I just thought I heard something 😱
I'm aware of the digital volume control issues, that is in general of course. That's why I wanted to make clear I'm using it. From there on decisions have to be made about the type of volume control that is best to use.
Within the scope of digital volume control (that is, not going into digital vs. analog volume control) you again have controls that work in floating point, and controls that work in integer math.
Usually, but not always, the floating point types will be done in software, and the integer ones in hardware (FPGA or when your DAC has "hardware volume control").
And again, when outputting in whatever bit-depth integer samples, you have controls that dither and controls that don't. When you look at volume control as a "filter" in a processing chain, that could entail other filters and possibly float to int conversion, you'd ideally only want to dither once during playback and that is at the very end of the chain.
Doing it in floating point is better than in integer math for the reasons that Bob Katz was cited with.
Note that this is about dithering in the playback chain. Recordings may and usually will have dithering and/or noise shaping applied to them. So Hans' advice on picking the 24-bit file still applies... or pick the 32-bit file, attenuate by 48 dB and again find yourself with 24 bit but having lost the recorded dither that is probably only 1-2 LSB. (just to be clear, that's not what I'm advocating 🙂)
No doubt you know these things better, I just strive for decent sound more close to "high resolution" rather than "bit transparent". In other words, some noise is OK as long as dynamic range is not lost. How much could afford to loose?
I did some reading into this subject, and think it's a tricky beast. Some people love vinyl (possibly a significant overlap with those that seek "NOS sound"?) and that only has like 70 dB DNR.
Human range can be from 120-140 dB depending on frequency and ear condition, but don't forget to take background noise into account which can be 20-30 dB even for critical listening.
Some reliably pass ABX tests between 96 dB CD-quality DNR and higher.
Others say it's not the absolute DNR figure that counts, but more the *stability* in DNR. When digital volume control is applied with integer math, you can work out that the loss in DNR is proportional to the PCM value. And as music varies in PCM value, you will have varying DNR.
Myself I'd say I'm a "rational audiophile": I take stock in theory (and am bent on good quality dithering and floating point filters), use that to discern what's snake oil and what's not, but also feel the weight of that 70 dB vinyl argument.
I may not post much, but am loving this thread.
Last edited:
Thank you very much! So, to summarize in a small post before I'm accused for thread hijacking... Since usb can only pass up to 24bit, setting Foobar output for 32bit most likely results to truncation so, better 24bit output. WaveIO is capable for 32bit. Could the remaining depth be useful when attenuating? It would mean a conversion right there to start with. Would it be floating point and dithered? I can only say that the digital volume control seems to be at the Xmos microcontroller's drivers. From my side, I built my system with a gain structure that keeps the volume control slider higher than half way.
USB can pass 32-bits. I2SoverUSB and most other USB boards output 32-bits by default. ESS dac chips do internal processing at 32-bits (not to say that the dac output operates at more than 24-bits, however). Etc.
The AES-3 standard is for SPDIF/TOSLINK/AES type digital audio interface signals; its not for USB.
AES3 - Wikipedia
The AES-3 standard is for SPDIF/TOSLINK/AES type digital audio interface signals; its not for USB.
AES3 - Wikipedia
Last edited:
Although the I2S word length can be 32-bit, many DACs only accept up to 24-bit PCM packed within those 32 bits. Or they'll just truncate the LSB by 8 bits. Indeed it's better to output 24-bit reduced and dithered in software, then to feed 32-bit to a DAC that'll truncate. So be sure to separate "transport bit depth" from "data bit depth" within that transport and double check how that is for your gear.
I think that holds true for the ESS DACs as well -- 24 bit samples internally processed in 32 bit integer math.
I don't know enough about Foobar or WaveIO to comment. You'd have to research their internals and match that with your gear bit depths.
Don't forget Hans' comment that taking a 32 bit *dithered* file and then attenuating it will throw away that dither, more so when it is reduced to 24 bit, and invalidate comparisons. This is true of course for dithered files of any bit depth.
I think that holds true for the ESS DACs as well -- 24 bit samples internally processed in 32 bit integer math.
I don't know enough about Foobar or WaveIO to comment. You'd have to research their internals and match that with your gear bit depths.
Don't forget Hans' comment that taking a 32 bit *dithered* file and then attenuating it will throw away that dither, more so when it is reduced to 24 bit, and invalidate comparisons. This is true of course for dithered files of any bit depth.
Last edited:
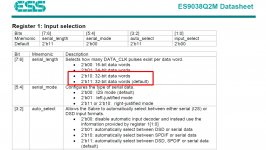
ESS data sheet says 32-bit input data is the default configuration. They also say their internal volume control runs at 32-bits. They don't say anything about truncation although it presumably occurs at some point prior to the switched resistor output.
Attachments
One answer came from Markw4. By example, DSD native transfers are 32-bit, not 24-bit (?). Amanero Combo 384 decoding 32-bit, I2S pass 32-bit as well. Truncation can happen on a DAC. Foobar will truncate 32-bit source if 24-bit outptut option is selected. Dithering option is only available when selecting 16-bit.So, to summarize in a small post before I'm accused for thread hijacking... Since usb can only pass up to 24bit, setting Foobar output for 32bit most likely results to truncation so, better 24bit output. WaveIO is capable for 32bit. Could the remaining depth be useful when attenuating? It would mean a conversion right there to start with. Would it be floating point and dithered? I can only say that the digital volume control seems to be at the Xmos microcontroller's drivers. From my side, I built my system with a gain structure that keeps the volume control slider higher than half way.
To many other questions... I don't know.
WaveIO: Can anyone explain how it interract with Foobar?
Last edited:
OK. I keep that the digital volume control won't work with the files of this test. Nevertheless, very useful info came up! I have some better insight of all this now. Thanks!
ESS data sheet says 32-bit input data is the default configuration. They also say their internal volume control runs at 32-bits. They don't say anything about truncation although it presumably occurs at some point prior to the switched resistor output.
Thanks, I must have thought about earlier versions.
...
WaveIO: Can anyone explain how it interract with Foobar?
WaveIO is a usb to I2S converter like Amanero, the interface of a usb DAC. This is what Foobar will see as output device. But I guess you know that. Is it something else you are asking about?
...before I'm accused for thread hijacking...
Never. 🙂
I think I've mentioned before, anyhow, that I feel these sorts of related digressions are healthy to a thread, as they help keep everyone engaged. Particularly, while thread action naturally slows as it has now while we conduct the 176 experiment.
So, no worries, Kostas.

Last edited:
USB can pass 32-bits. I2SoverUSB and most other USB boards output 32-bits by default. ESS dac chips do internal processing at 32-bits (not to say that the dac output operates at more than 24-bits, however). Etc.
The AES-3 standard is for SPDIF/TOSLINK/AES type digital audio interface signals; its not for USB.
AES3 - Wikipedia
Hi Mark,
Thx for your input regarding USB enabling 32 bit transfer.
And yes I agree, in that case when converting USB to I2S still enables the full 32 bits.
What you will need is a Dac with USB input, hoping that this is directly converted to I2S and not to AES-3 for an SRC that is doing the OS.
The relevant question is though, do we really need this 32 bit.
Of course for intermediate processing you will need much more bits, but isn’t 24 bit more than enough for the final file ?
In my case I have an asynchronous USB to (AES3) ST fiber converter, having its own clean power supply, computer connected via a short USB cable where the outgoing 500Mhz fiber to my Dac is 8 meters long, but could just as well be 1Km.
Excellen galvanic isolation from my “dirty” computer.
Hans
Last edited:
- Home
- Source & Line
- Digital Line Level
- What do you think makes NOS sound different?