A digital expander does work on simultaneous sounds loud and soft. If it didn't it wouldn't be an expander. It would just be ducking volume and gaining volume in time. It functions continuously.
Please explain how it can function continuously given that digital is an inherently discontinuous process.
That might explain how you can possibly think that an expander works on loud and soft signals simultaneously when there can only be one discrete level at any one time. This is true of digital and analogue signals by the way.
Yes digital signals are discrete points. The deq works continuously throughout all points. Or for a more technical description successively. From point to point . It works on both loud and soft sounds because the filter Itself is always active. I takes a sound below threshold and increases it , and sound above threshold is passed. Those are the two action of the filter . Just because it doesn't change anything in output two doesn't mean a comparison wasnt made. Filter is continuously active.
Now you do make a point about discrete volume levels . Because the FFT combines all signals into one summed level.
There is only one volume at a moment in time . So yes I will admit I described that wrong . My apologies 🙁
Now you do make a point about discrete volume levels . Because the FFT combines all signals into one summed level.
There is only one volume at a moment in time . So yes I will admit I described that wrong . My apologies 🙁
I don want to presume to know how the DEQ works exactly. Your question about discrete points had me second guessing that statement about simaltaneous compression. On second thought I would assume that it does analysis of a consecutive set of discrete points. I am a little confused on that point and want to investigate and reply. But if you read the description of how it works in the manual it does imply a functionality like a crossover. Perhaps a filter like a crossover in the frequency time domain works to separate out loudness instead of frequencies like with a pressure time domain ? I have to review this point.
If you can identify a frequency and separate it out it has it's own relative amplitude which is distinguishable from other larger amplitude wave forms. If the DEQ couldn't do this it would only work when loud and soft sounds play seperatly. And that wouldn't be very useful. I really don't think it works that way. For an analogue filter to separate loud and soft simaltaneous sound it would be harder if not impossible . But for a digital filter I think it's easy. It can analyze before it outputs and it's not restricted to make a decision at each for each discrete point each moment , it can analyze sets of data . Groups of discrete points, a window of data to partially reconstruct the signal.
So I do think my original statement is true. Anyone have any info on this?
If you can identify a frequency and separate it out it has it's own relative amplitude which is distinguishable from other larger amplitude wave forms. If the DEQ couldn't do this it would only work when loud and soft sounds play seperatly. And that wouldn't be very useful. I really don't think it works that way. For an analogue filter to separate loud and soft simaltaneous sound it would be harder if not impossible . But for a digital filter I think it's easy. It can analyze before it outputs and it's not restricted to make a decision at each for each discrete point each moment , it can analyze sets of data . Groups of discrete points, a window of data to partially reconstruct the signal.
So I do think my original statement is true. Anyone have any info on this?
Last edited:
ya so the answer is actually very simple the signal is decomposed into separate frequency and amplitude components, the signal can be adjusted based on frequency and amplitude, of simultaneous sounds, or separately played sounds.
Im just reviewing the text. engineering noise control theory and practice, David A Bies.
Someone has probably already explained this on the forum somewhere but I wanna go over it anyway for fun. Let me review and get back.
Im just reviewing the text. engineering noise control theory and practice, David A Bies.
Someone has probably already explained this on the forum somewhere but I wanna go over it anyway for fun. Let me review and get back.
so charles darwin ......digital signals are frequency time domain signals, they have been transformed to the frequency domain, and each frequency is stored with its own amplitude. The signal is decomposed and stored in frequency and amplitude components. So there is no one single amplitude level in a digital signal, there are multiple different signals of different frequency and amplitude stored separately. It would be very simple to filter them based on amplitude and make some gain or cut.
You have to do a Fourier transform , and replot a signal in the frequency time domain to understand it, but basically these multiple frequency components are recombined when you do the inverse Fourier transform, and this give you again an amplitude time function which only has a single discrete volume level at a given instant.
It is the principle of superposition that this is described as. Reconstruction of any complex wave form out of sinusoidal components.
You have to do a Fourier transform , and replot a signal in the frequency time domain to understand it, but basically these multiple frequency components are recombined when you do the inverse Fourier transform, and this give you again an amplitude time function which only has a single discrete volume level at a given instant.
It is the principle of superposition that this is described as. Reconstruction of any complex wave form out of sinusoidal components.
Last edited:
Google Fourier transform and think about it. When you come back consider this article about how a hearing aid is designed for dynamic compression.
if you still think i am talking nonsense and making this all up please note this paragraph which verifies the idea I have presented is valid.
Frequency-Domain Compression
The filter bank represents an approach to timedomain
processing. The input sequence is convolved
with the filters one sample at a time, and
the output sequence is formed by summing the
filter outputs. The compressor operates independently
on the signal levels estimated for each filter.
An alternative approach is to divide the signal
into short segments, transform each segment into
the frequency domain, compute the compression
gains from the computed input spectrum and
apply them to the signal, and then inverse transform
to return to the time domain.
see pg 65 of the following article
- Principles of Digital Dynamic-Range Compression
if you still think i am talking nonsense and making this all up please note this paragraph which verifies the idea I have presented is valid.
Frequency-Domain Compression
The filter bank represents an approach to timedomain
processing. The input sequence is convolved
with the filters one sample at a time, and
the output sequence is formed by summing the
filter outputs. The compressor operates independently
on the signal levels estimated for each filter.
An alternative approach is to divide the signal
into short segments, transform each segment into
the frequency domain, compute the compression
gains from the computed input spectrum and
apply them to the signal, and then inverse transform
to return to the time domain.
see pg 65 of the following article
- Principles of Digital Dynamic-Range Compression

note post 83 should say the "inverse FFT" sums all components to form the amplitude time signal. From the FFT of the original signal.
This is the form which has one amplitude level at a moment in time.
The FFT of the original signal is the form that we can manipulate the loud and soft sounds separately at specific frequencies of simultaneously played sounds.
This is the form which has one amplitude level at a moment in time.
The FFT of the original signal is the form that we can manipulate the loud and soft sounds separately at specific frequencies of simultaneously played sounds.
Last edited:
Thanks klhsx, this is some really neat stuff and probably has a lot to do with how DAC's convert the data to analog. The only difference is Beringer has allowed us to adjust it. Super Cool. 🙂
If you don't understand superposition or Fourier transforms it would explain why you could possibly think there is only one discrete volume level.
It's not the same for digital and analogue by the way.
It's not the same for digital and analogue by the way.
Moving along then. I want to start to talk more about the effects on the speaker. We have covered the compression due to thermal losses, yes this is at high volumes for the extreme case and this is where it becomes most prominent.
However by trial and error I have found that my woofer benefits from a digital dynamic compression especially at low to med volumes (probably even semi loud volumes to because I have such an intense array of woofers they never become stressed into the thermal compressive range).
So what is going on? Perhaps there is some expansion effect that occurs at low to mid volumes. If we think about it, transients, and low level information are small displacements of the cone, and displacements from rest.
This means that all the speaker elements have to overcome static friction, which is greater than kinetic friction. Means once you get something moving the friction is less than when you first push it from a rested position.(technically each time the cone changed direction it would have a different internal friction from static to kinetic for an instant) I would guess there is an analogue of this in the motor force from the voice coil, and amp as well. That would be interesting to explore, prove or disprove.
This would fight against the initial driving force, and result in decreased output for transients when they start. Maybe this is part of why stiff speaker cones can sound brighter or faster or more dynamic, is because they have less bending, and less of this expander effect. (expander being the reduction of low level sound in proportion to high level sound). For example focal polyglass W cones. Obviously stiffer cones have higher resonance frequencies and , and higher freq response, and that is the primary contributor to the bright sound, so we keep that in mind.
But if you know focal you know that they sound dynamic at low volumes......
Why is it so hard to match a ribbon speaker to a cone speaker? hmmmm different dynamic response!
Eq the woofer separately from the ribbon with Dynamic EQ and they will have a much better integration? Yes I am going to try it and see what the DCX can offer.
I have noticed that the scan speak carbon fibre woofers have a harder time integrating with ribbons than the focal W series. I think after playing the DEQ the gap would be much reduced.
This could really optimize the process of driver integration. Maybe we can develop a method involving REW that removes some of the guess work?
Lots to consider!
However by trial and error I have found that my woofer benefits from a digital dynamic compression especially at low to med volumes (probably even semi loud volumes to because I have such an intense array of woofers they never become stressed into the thermal compressive range).
So what is going on? Perhaps there is some expansion effect that occurs at low to mid volumes. If we think about it, transients, and low level information are small displacements of the cone, and displacements from rest.
This means that all the speaker elements have to overcome static friction, which is greater than kinetic friction. Means once you get something moving the friction is less than when you first push it from a rested position.(technically each time the cone changed direction it would have a different internal friction from static to kinetic for an instant) I would guess there is an analogue of this in the motor force from the voice coil, and amp as well. That would be interesting to explore, prove or disprove.
This would fight against the initial driving force, and result in decreased output for transients when they start. Maybe this is part of why stiff speaker cones can sound brighter or faster or more dynamic, is because they have less bending, and less of this expander effect. (expander being the reduction of low level sound in proportion to high level sound). For example focal polyglass W cones. Obviously stiffer cones have higher resonance frequencies and , and higher freq response, and that is the primary contributor to the bright sound, so we keep that in mind.
But if you know focal you know that they sound dynamic at low volumes......
Why is it so hard to match a ribbon speaker to a cone speaker? hmmmm different dynamic response!
Eq the woofer separately from the ribbon with Dynamic EQ and they will have a much better integration? Yes I am going to try it and see what the DCX can offer.
I have noticed that the scan speak carbon fibre woofers have a harder time integrating with ribbons than the focal W series. I think after playing the DEQ the gap would be much reduced.
This could really optimize the process of driver integration. Maybe we can develop a method involving REW that removes some of the guess work?
Lots to consider!
Last edited:
oh and back to the discussion on dynamic eq and how it works, I would still like to hear why you can't manipulate loud and quiet simultaneous sounds separately?
I think its just conceptually difficult to see how it works when you are used to amplitude time signals.
If you just look at how a frequency time signal works it seems really simple that you could manipulate any frequency based on its amplitude.
http://www.slideshare.net/WayneJonesJnr/chapter-3-data-and-signals
I think its just conceptually difficult to see how it works when you are used to amplitude time signals.
If you just look at how a frequency time signal works it seems really simple that you could manipulate any frequency based on its amplitude.
http://www.slideshare.net/WayneJonesJnr/chapter-3-data-and-signals
Attachments
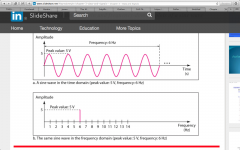
The next thing you have to understand is with math you can take apart any signal and make a bunch of simple sin waves like this, when you put them back together it makes the original signal.
this is the principle of superposition
this is the principle of superposition
Attachments
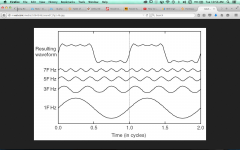
Let's say 2 instruments are playing a constant note. The deq seperates all the freq and then boosts the louder ones? How's it know which harmonics belong to which instrument? This will change the harmonic balance of your instruments.
How does it know which harmonics belong to the loud sounds and which to the quiet , the loud sound may have softer harmonics than the quiet one. A loud flute over a quiet very distorted guitar.
- Status
- Not open for further replies.
- Home
- Source & Line
- Digital Source
- DEQ 2496 and why everyone should play with dynamic EQ