It is playing 🙂
One question - is buffer half of the chunksize?
In the config I have:
chunksize: 16384
and in the log there is:
Buffer frames 8192, module: camillalib::alsadevice
..
Current buffer level: 16699.550847457627, corrected capture rate: 99.991796875%, module: camillalib::audiodevice
Playback buffer level: 16699.550847457627, signal rms: [-25.775124, -26.27856, -60.60185, -61.3479, -1000.0, -1000.0, -43.94819, -45.491413], module: camillalib::alsadevice
Thanks
One question - is buffer half of the chunksize?
In the config I have:
chunksize: 16384
and in the log there is:
Buffer frames 8192, module: camillalib::alsadevice
..
Current buffer level: 16699.550847457627, corrected capture rate: 99.991796875%, module: camillalib::audiodevice
Playback buffer level: 16699.550847457627, signal rms: [-25.775124, -26.27856, -60.60185, -61.3479, -1000.0, -1000.0, -43.94819, -45.491413], module: camillalib::alsadevice
Thanks
Thanks, please let me know if it stops 😀It is playing 🙂
That is the initial size of a buffer it uses for storing samples when reading from the capture device. Are you running with resampling? The buffer size is set to 1.2*chunksize*capture_samplerate/samplerate, and then rounded up to the nearest power of two. It also checks while running and increases the size if needed. I added that debug print when implementing the resampling, I should probably remove it or change it to trace level.One question - is buffer half of the chunksize?
In the config I have:
chunksize: 16384
and in the log there is:
Buffer frames 8192, module: camillalib::alsadevice
..
Current buffer level: 16699.550847457627, corrected capture rate: 99.991796875%, module: camillalib::audiodevice
Playback buffer level: 16699.550847457627, signal rms: [-25.775124, -26.27856, -60.60185, -61.3479, -1000.0, -1000.0, -43.94819, -45.491413], module: camillalib::alsadevice
Thanks
I have changed to Synchronous.
devices:
capture:
channels: 2
device: hw:Loopback,1
format: FLOAT32LE
type: Alsa
capture_samplerate: 44100
chunksize: 16384
enable_rate_adjust: true
enable_resampling: true
playback:
channels: 8
device: hw:1,11,0
format: S32LE
type: Alsa
resampler_type: Synchronous
samplerate: 192000
So 1.2*chunksize*capture_samplerate/samplerate
1.2*16384*44100/192000 = 4515.84
devices:
capture:
channels: 2
device: hw:Loopback,1
format: FLOAT32LE
type: Alsa
capture_samplerate: 44100
chunksize: 16384
enable_rate_adjust: true
enable_resampling: true
playback:
channels: 8
device: hw:1,11,0
format: S32LE
type: Alsa
resampler_type: Synchronous
samplerate: 192000
So 1.2*chunksize*capture_samplerate/samplerate
1.2*16384*44100/192000 = 4515.84
If you where to be overwhelmed by energy and blessed with endless amount of time - an OS X build? 🙂
//
//
Yes, and then rounded up to the nearest power of two, 4515 --> 8192.So 1.2*chunksize*capture_samplerate/samplerate
1.2*16384*44100/192000 = 4515.84
Of 0.5.0-beta5? Already done, just check the link.If you where to be overwhelmed by energy and blessed with endless amount of time - an OS X build? 🙂
//
I don't actually spend any time at all on building the released binaries, it's all automatic. When I create a new release in github, that triggers build jobs for all the configurations. Then the finished binaries are compressed and added as assets in the release. They all run in parallel and each build takes a couple of minutes. So a new release uses something like 20-30 minutes of compute time on the github servers. Github offers this service for free for open source projects. I hope they don't decide to change that..
I don't actually spend any time at all on building the released binaries, it's all automatic. When I create a new release in github, that triggers build jobs for all the configurations. Then the finished binaries are compressed and added as assets in the release. They all run in parallel and each build takes a couple of minutes. So a new release uses something like 20-30 minutes of compute time on the github servers. Github offers this service for free for open source projects. I hope they don't decide to change that..
Now that is cool.
Like what I am seeing here. Might have to try it out.
Trouble is I need more than 8 channels of DSP. This I will have to investigate. See what is configurable. I keep watching as a fly on the wall.
This is really cool! I'm wondering, is there any chance for VST support in the future? I know from JRiver this is extremely useful because it opens up a whole world of possibilities with audio processing. I really want to migrate from JRiver, and this is all that's missing.
This is really cool! I'm wondering, is there any chance for VST support in the future? I know from JRiver this is extremely useful because it opens up a whole world of possibilities with audio processing. I really want to migrate from JRiver, and this is all that's missing.
FWIW, I am using CamillaDSP underneath JRMC instead of their convolution engine and Parametric EQ filters. JRMC does not support muti-pass convolution even though multiple people have requested it over various versions.
Last edited:
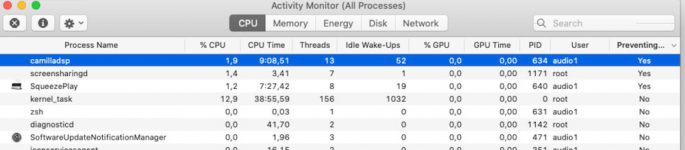
In OS X, Camilla is preventing sleep when looking in. Is this permanent as in 24/7? I'm thinking power consumption and environment here... Could a sleep be OK after a certain time with silence?
After asking the mini to sleep it seems indeed to have had a good night rest.
//
Camilladsp can handle any number of channels, but I guess finding an interface with more than 8 channels might be difficult (and/or expensive).Trouble is I need more than 8 channels of DSP. This I will have to investigate. See what is configurable. I keep watching as a fly on the wall.
Plugin support is mention in this issue: Add LV2/LADSPA/VST filters * Issue #74 * HEnquist/camilladsp * GitHubThis is really cool! I'm wondering, is there any chance for VST support in the future? I know from JRiver this is extremely useful because it opens up a whole world of possibilities with audio processing. I really want to migrate from JRiver, and this is all that's missing.
The only rust library I have found for hosting vst plugins doesn't support plugins with guis, and I guess that severely limits the usefulness.
Good! Once I move away from cpal and talk to coreaudio directly I will have a chance to control stuff like this. Now it's all hidden by the cpal api.After asking the mini to sleep it seems indeed to have had a good night rest.
//
Maybe to do channel "arithmetics" like add/multiply etc - notch notch... 😉
To be able to create something like:
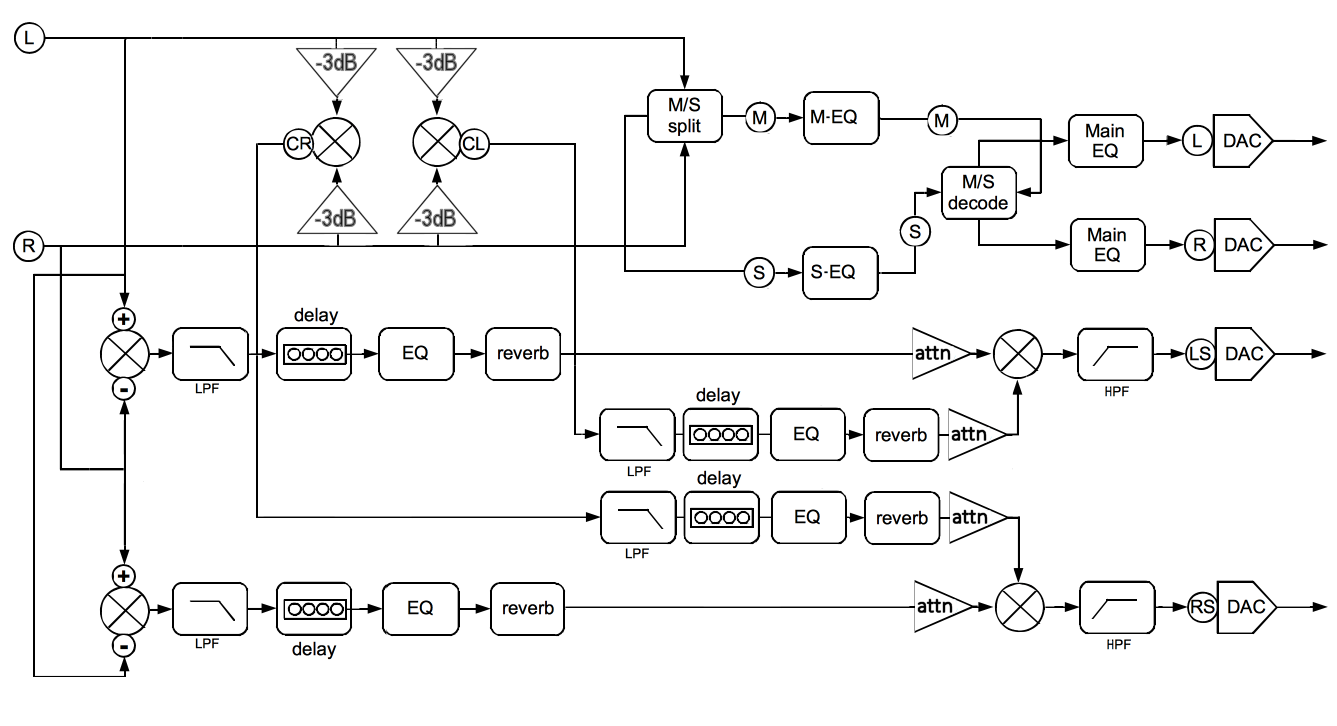
from:
The making of: The Two Towers (a 25 driver Full Range line array)
//
To be able to create something like:
from:
The making of: The Two Towers (a 25 driver Full Range line array)
//
Last edited:
Don't know what M/S split and encode means here, but at least the rest can be done with the building blocks available in camilladsp.
Probably Left-Right stereo to Mid-Side stereo ("M/S split"), then selective processing of the S (side) and the M (mono) channels/information, and then converting everything back to a Left-Right signal again ("M/S decode").
Mid/Side-Stereofonie – Wikipedia
With this technique, you can e.g. spread or narrow the stereo basis for different frequencies by selectively convolving the S signal with an appropriate filter. An example of this is e.g. implemented in the AcourateConvolver of Uli Brüeggemann, as "Flow": High frequencies are shifted more towards the center of the stereo basis, and low frequencies are shifted more towards the sides
AcourateNAS mit AcourateFLOW - aktives-hoeren.de
Also Frankl (the author of the playhrt/resample-soxr/bufhrt/writeloop programs) has a similar solution within his software bundle:
LoCo - Localization Correction - aktives-hoeren.de
And here is also a theory about manipulating the stereo width as a frequency dependent value:
http://www.sengpielaudio.com/FrequenzabhHoerereignisrichtung.pdf
Selectively processing the S info allows for many other different effects affecting the stereo rendering. Therefore this M/S-encoding-decoding option can indeed be an interesting playfield
Mid/Side-Stereofonie – Wikipedia
With this technique, you can e.g. spread or narrow the stereo basis for different frequencies by selectively convolving the S signal with an appropriate filter. An example of this is e.g. implemented in the AcourateConvolver of Uli Brüeggemann, as "Flow": High frequencies are shifted more towards the center of the stereo basis, and low frequencies are shifted more towards the sides
AcourateNAS mit AcourateFLOW - aktives-hoeren.de
Also Frankl (the author of the playhrt/resample-soxr/bufhrt/writeloop programs) has a similar solution within his software bundle:
LoCo - Localization Correction - aktives-hoeren.de
And here is also a theory about manipulating the stereo width as a frequency dependent value:
http://www.sengpielaudio.com/FrequenzabhHoerereignisrichtung.pdf
Selectively processing the S info allows for many other different effects affecting the stereo rendering. Therefore this M/S-encoding-decoding option can indeed be an interesting playfield
Last edited:
Forgot to ask.. What is it you need vst plugins for?
The main thing I need VSTs for dynamic equalization. For example, I want to limit bass at high volumes to avoid distorting/damaging my speakers.
I've also played with things like tube amp emulators, which was cool, and dynamic EQ for cutting treble at higher volumes, which was also neat.
- Home
- Source & Line
- PC Based
- CamillaDSP - Cross-platform IIR and FIR engine for crossovers, room correction etc