Could you please expand upon which particular acoustic phenomena have decay times measured in microseconds.Vs the microsecond decay times of the thousands of compression / rarefactions which make up each INDIVIDUAL note.

There are many new studies emerging showing just how incredibly sensitive our ear / brain hearing is... From 6.9 microseconds for trained listeners to 18 microseconds for untrained listeners. (Acoustical Society of America)
“ Localization accuracy is 1 degree for sources in front of the listener and 15 degrees for sources to the sides. Humans can discern interaural time differences of 10 microseconds or less. ] “ https://en.wikipedia.org/wiki/Sound_localization
“It is well-established that the smallest discrimination thresholds for interaural time differences (ITDs) are near 10 μs (microsecond) for normal hearing listeners. However, little is known about the hearing and training status of the test subjects from past studies. Previous studies also did not explicitly focus on the identification of the optimal stimulus and measurement technique to obtain the smallest threshold ITDs. Therefore, the first goal of the current study was to identify the stimulus and experimental method that maximizes ITD sensitivity. The second goal was to provide a precise threshold ITD reference value for both well-trained and un-trained normal hearing listeners using the optimal stimulus and method. The stimulus that yielded the lowest threshold ITD was Gaussian noise, band-pass filtered from 20 to 1400 Hz, presented at 70 dB sound pressure level. The best method was a two-interval procedure with an interstimulus interval of 50 ms. The average threshold ITD for this condition at the 75% correct level was 6.9 μs for nine trained listeners and 18.1 μs for 52 un-trained listeners.” https://pubs.aip.org/asa/jasa/artic...llest-perceivable-interaural-time-differences
“ Localization accuracy is 1 degree for sources in front of the listener and 15 degrees for sources to the sides. Humans can discern interaural time differences of 10 microseconds or less. ] “ https://en.wikipedia.org/wiki/Sound_localization
“It is well-established that the smallest discrimination thresholds for interaural time differences (ITDs) are near 10 μs (microsecond) for normal hearing listeners. However, little is known about the hearing and training status of the test subjects from past studies. Previous studies also did not explicitly focus on the identification of the optimal stimulus and measurement technique to obtain the smallest threshold ITDs. Therefore, the first goal of the current study was to identify the stimulus and experimental method that maximizes ITD sensitivity. The second goal was to provide a precise threshold ITD reference value for both well-trained and un-trained normal hearing listeners using the optimal stimulus and method. The stimulus that yielded the lowest threshold ITD was Gaussian noise, band-pass filtered from 20 to 1400 Hz, presented at 70 dB sound pressure level. The best method was a two-interval procedure with an interstimulus interval of 50 ms. The average threshold ITD for this condition at the 75% correct level was 6.9 μs for nine trained listeners and 18.1 μs for 52 un-trained listeners.” https://pubs.aip.org/asa/jasa/artic...llest-perceivable-interaural-time-differences
This is a commonly held belief... It is wrong... Totally wrong and is in fact one of the major falsehoods in loudspeaker and loudspeaker transducer design which has held back acoustic design for decades!
A trained ear can hear if harmonics have exited their envelope.
But all loudspeakers are a giant set of compromises. This one is often sacrificed.
dave
From 6.9 microseconds for trained listeners
I believe that it is 5 µsec. (ref Kunchar/http://boson.physics.sc.edu/~kunchur//Acoustics-papers.htm)
dave
This is far too strong a statement, and somewhat misleading for a number of reasons.If one accepts (and some still dont!) that the the human ear brain / hearing mechanism is designed to detect and decode ALL sounds using the time domain then one MUST accept that number one goal in sound reproduction is to perfect the time domain performance of the source ie the loudspeaker transducer and the cabinet / loading of the finished design.
Firstly, in a convolution of one or more linear systems, the time domain and frequency domain provide for entirely equivalent representations. Which we chose to target is then simply a choice of which representation is most useful (normally to our eyes). For steady-state signals, the frequency domain representation is typically more useful. You might concur too that the time domain is more useful for transient signals (as it often is). But in any linear analysis, ALL the relevant information is observable in the Wigner Distribution, and via suitable filtering we can end up with any of the common representations in either the time or frequency domain, or both together (subject to the Uncertainty Principle).
However, we are not so simple as to be modelled by a bank of fixed frequency filters or an impulse recorder. Indeed, if we wish to use a filtered Wigner distribution representing the signal simultaneously in both domains, we find the need to employ filters whose bandwidth varies in time. Even in linear analysis then, we have to account for non-linear mechanisms in our hearing. How exactly we perceive Qts is not fully established, although it is likely that even an optimally-filtered Wigner Distribution will not be sufficient. An accurate model may very well involve third-order bispectral analysis and more than consideration of a single frequency therefore.
If we then talk of sources or loudspeakers in different positions, or of the different audible effects of early or late reflections, or their direction, we need take further account of having two ears too, where cross-bispectral analysis appears of relevance. Such third-order models can be used to model well how we discern live sounds from recorded sounds reproduced via a loudspeaker, for example. It is somewhat naive therefore to state that the audibility of different Qts alignments is resolved in the time domain.
More important than any of my above meandering, however, is the hysteretic non-linearity imposed by our ability to learn (voluntarily or otherwise). It means that any individual can exhibit significantly different thresholds in audibility tests according to their experience. As a statement to back this up, I have for many years exploited a linear phase low frequency roll-off (for which Qts has no meaning, but where I use a magnitude target with a Qts of 0.707). I find its advantage clearly audible, and I have learned as a result to also discern a Qts of 0.577 from one of 0.707 or greater. Yet many (but not all) audio professionals who I readily admit have better hearing than me cannot discern any difference at all.
And if I try and account for how I can perceive this loudspeaker roll-off, or if I attempt to quantify what is the "number one goal in sound reproduction", I am stumped. But I do know the answer is not simple.
Happy to disagree with you, I stand by the logic, the references and the conclusions of my statement. You have stated your opinion...
PS At no point do I mention or refer to Qts, the audibility or not of different Qts or such tiny / irrelevant details... My focus is on the vital importance of the time domain accuracy in: (1) Loudspeaker transducers (2) Complete loudspeaker designs.
IMO, as all cone/dome drivers are electro/mechanical devices with a time domain performance an order of magnitude (or several orders of magnitude!) below the standard required for accurate time domain sound reproduction, are by definition "not fit for purpose".
I suggest that until AI and molecular level 3D printers combine with next gen materials and ********************** (might have an idea!) the best we can do with current drivers is to minimise cone travel/maximise sensitivity whilst deploying the most time domain accurate driver loading techniques.
IMO, as all cone/dome drivers are electro/mechanical devices with a time domain performance an order of magnitude (or several orders of magnitude!) below the standard required for accurate time domain sound reproduction, are by definition "not fit for purpose".
I suggest that until AI and molecular level 3D printers combine with next gen materials and ********************** (might have an idea!) the best we can do with current drivers is to minimise cone travel/maximise sensitivity whilst deploying the most time domain accurate driver loading techniques.
Although time domain accuracy is certainly a worthy goal in loudspeaker design, the argument that errors in the time domain are the "number one" reason one could tell the difference between a large instrument replaced by a loudspeaker does not follow.Take any room with good, bad or average acoustic properties, place a piano or cello or any bass (actually any instrument at all) instrument in it.
Have the instrument played at different locations in the room whilst you remain seated in the "listening position" ... The sound will change in tonality as room gain (wall/corner/floor/ceiling) and reflections vary. Similar (but not identical) changes will occur as you move the listening position and or instrument location.
So, in a real room with a real instrument if blind folded, the vast majority of healthy humans could easily detect that the instrument is being moved as tonality/reverb would vary with location. Tiny changes in position hard to detect, large changes easy to detect, so far so good.
Important, these changes are subtle... Now compare that with replacing the piano with a loudspeaker, ANY loudspeaker would be easily delectable by the vast majority of listeners... Not a subtle tonal change but a fundamental gross error in the time domain source reproduction ie heavy cones bouncing on rubber suspensions with settling times (as revealed by CSD and time domain plots) in the hundreds of millisecond (typical subwoofer at 100 dB / SPL) Vs the microsecond decay times of the thousands of compression / rarefactions which make up each INDIVIDUAL note.
Now IF TBTL (and also the majority of DIY speaker guys!) are correct it would make no difference at all if the real musical instrument is replaced by a loudspeaker REGARDLESS of its TIME DOMAIN accuracy due to the room acoustics/reverb time being "more important".... Clearly this is wrong.
CRUCIALLY this relates to the loudspeaker transducers (drivers) as well as the cabinet loading.
So the assumption that the quality/accuracy of the loudspeaker is not important due to room acoustics/reverb time being "more important" is wrong.
If one accepts (and some still dont!) that the the human ear brain / hearing mechanism is designed to detect and decode ALL sounds using the time domain then one MUST accept that number one goal in sound reproduction is to perfect the time domain performance of the source ie the loudspeaker transducer and the cabinet / loading of the finished design.
A loudspeaker with perfect frequency and time domain reproduction could not reproduce the radiation characteristics of an acoustic instrument, so still could easily be detected by the vast majority of listeners in a small room as "different".
No, you have given us your intuition, and that falls short of logic. Your references refer only to thresholds obtained by averaging all manner of subjects. And whilst my response supplies some opinion, it represents an up-to-date assessment of current thinking, for which references can be found if you care to study the subject in depth.I stand by the logic, the references and the conclusions of my statement. You have stated your opinion...
And yet here is your opinion! And opinion that is just hyperbole and no particular use to anyone. Engineering is about compromise, and its central tenets do not change regardless of how technology advances.IMO, as all cone/dome drivers are electro/mechanical devices with a time domain performance an order of magnitude (or several orders of magnitude!) below the standard required for accurate time domain sound reproduction, are by definition "not fit for purpose".
That it might be, but your explanation is fundamentally flawed by your presentation of basic time-frequency analysis, even before we extend that to non-linear concerns. Thus your contribution was misleading at best.My focus is on the vital importance of the time domain accuracy in: (1) Loudspeaker transducers (2) Complete loudspeaker designs.
Last edited:
Further to my last comments, and on admittedly only brief reading, your references appear to concern inter-aural time differences, not the time domain behaviour of a loudspeaker, or, more simply, a filter - the latter being relevant to this thread.
I'm not entirely sure how commonly that belief is held. 😕 For example, designers of loudspeakers for near-field monitoring know that it reduces the effect of the room, so a good frequency response is important to an accurate listening experience, and that requires time domain performance that is also good (the two are linked). The on-axis response frequency response of candidate loudspeakers in domestic listening rooms is a strong performance indicator, even before we go beyond that simple metric.This is a commonly held belief [that the time domain performance of the loudspeaker being irrelevant once you put it in a room]... It is wrong...
Firstly, it is somewhat apparent that a loudspeaker is NOT a piano. Hence, it can be expected that the loudspeaker will interact with a room quite differently from a piano. The recording engineer's art comes into play in trying to get some semblance of the original sound of the piano captured on the recording, so that when it is replayed over a hi-fi loudspeaker system the reproduction sounds like the piano that was recorded (ideally). Of course, some recordings will be better than others, and they will also be influenced by the room acoustics of the listening room, as well as the frequency response/time domain performance of the loudspeaker, and the location of the listener, to name a few effects on the overall listening experience.Important, these changes are subtle... Now compare that with replacing the piano with a loudspeaker, ANY loudspeaker would be easily detectable by the vast majority of listeners...
It also needs to be kept in mind that, although some cones are indeed quite heavy, they are usually supported by powerful magnetic motor systems. These are capable of controlling the displacement relatively well. The performance of loudspeakers and amplifiers is analogous if they have similar frequency response curves, as their dynamic behavior can be modelled using similar equations. Of course, loudspeakers have much greater nonlinearities that will influence their performance.Not a subtle tonal change but a fundamental gross error in the time domain source reproduction ie heavy cones bouncing on rubber suspensions with settling times (as revealed by CSD and time domain plots) in the hundreds of millisecond (typical subwoofer at 100 dB / SPL) Vs the microsecond decay times of the thousands of compression / rarefactions which make up each INDIVIDUAL note.
From what I have gleaned, the hearing mechanism relies on sensors/transducers that have varying mass and stiffness properties, not to mention fluid coupling, which will all of course introduce vibroacoustic system dynamics into the hearing equation.If one accepts (and some still dont!) that the the human ear brain / hearing mechanism is designed to detect and decode ALL sounds using the time domain then one MUST accept that number one goal in sound reproduction is to perfect the time domain performance of the source ie the loudspeaker transducer and the cabinet / loading of the finished design.
Last edited:
I suppose that Thiele, Small, Keele, Newman, Bowers, and Cooke, amongst many others, would not consider the values of Qts to be "tiny/irrelevant details" when trying to understand and design high-performance loudspeaker systems made up of woofers, midranges and tweeters. A working knowledge of Qts is helpful, even vital, for achieving good time-domain accuracy in loudspeaker system designs.At no point do I mention or refer to Qts, the audibility or not of different Qts or such tiny / irrelevant details...My focus is on the vital importance of the time domain accuracy in: (1) Loudspeaker transducers (2) Complete loudspeaker designs.
To the above replies, you clearly are in the camp of "some still dont", so I am happy to disagree with you and enjoy your DIY journey following your own ideas.
"If one accepts (and some still dont!) that the the human ear brain / hearing mechanism is designed to detect and decode ALL sounds using the time domain then one MUST accept that number one goal in sound reproduction is to perfect the time domain performance of the source ie the loudspeaker transducer and the cabinet / loading of the finished design.
"If one accepts (and some still dont!) that the the human ear brain / hearing mechanism is designed to detect and decode ALL sounds using the time domain then one MUST accept that number one goal in sound reproduction is to perfect the time domain performance of the source ie the loudspeaker transducer and the cabinet / loading of the finished design.
Correct, as I previously stated, "the audibility or not of different Qts or such tiny / irrelevant details..." are indeed irrelevant details compared to the number one issue ie accurate time domain performance.
I have attached a more detailed explanation written by Johm Watkinson. I doubt you will enjoy or agree with it as "its hard to fill a glass that is already full".
Also it challenges all your heroes (Thiele, Small, Keele, Newman, Bowers, and Cookeas) assumptions and beliefs ... But for all open minded DIY readers its a fascinating read.
I have attached a more detailed explanation written by Johm Watkinson. I doubt you will enjoy or agree with it as "its hard to fill a glass that is already full".
Also it challenges all your heroes (Thiele, Small, Keele, Newman, Bowers, and Cookeas) assumptions and beliefs ... But for all open minded DIY readers its a fascinating read.
Attachments
Really? I'm not convinced, especially after reading the Watkinson publication, and feel we have many loudspeaker design ideas in common.To the above replies, you clearly are in the camp of "some still don't", ...
Well, I expect that when the frequency response function of the loudspeaker, by which I mean the magnitude and the phase response, is well controlled to achieve accurate sound reproduction, then the time domain performance will also be excellent. This is entirely within the grasp of active loudspeaker systems that make use of the power of modern DSP capabilities."If one accepts ... that the the human ear brain/hearing mechanism is designed to detect and decode ALL sounds using the time domain then one MUST accept that number one goal in sound reproduction is to perfect the time domain performance of the source, i.e., the loudspeaker transducer and the cabinet/loading of the finished design.
Consider the B&W DM6, which was a sealed three-way passive loudspeaker system produced in the 1970s. It had an excellent frequency response as well as time domain response. Those involved with the creation of this particular loudspeaker clearly had a few specific design features in mind, well prior to the discussions in the current thread. In the past, time-aligned loudspeakers were the subject of discussion in many magazine and journal articles.
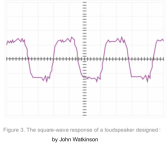
When it comes to square waves, and frequency response, what the DM6 could produce is shown below.
In comparison, a more modern design such as the Duntech Crown Prince loudspeaker could achieve excellent square wave reproduction, such as shown below. It also had a quite flat frequency response, unsurprisingly, which is a very important consideration when trying to attain high sound quality and good time-domain performance.
Then there is the Dunlavy SC-I monitor. Its square wave response and frequency response are shown below.
The "detailed explanation" of John Watkinson's 22 pages could be condensed to his statements:Also it challenges all your heroes (Thiele, Small, Keele, Newman, Bowers, and Cooke) assumptions and beliefs ... But for all open minded DIY readers its a fascinating read.
"The human ear is imperfect and if the imperfections in the speaker are less than the imperfections in the ear, then they will be indetectible..the three key domains in which a loudspeaker must meet performance criteria.. are time, space and frequency. The time domain sets criteria for linear distortion, the space domain sets criteria for directivity and the frequency domain needs no comment."
Those statements do not challenge any of the assumptions and beliefs of Thiele, Small, Keele, Newman, Bowers, or Cooke that I am aware of.
Now that relatively inexpensive computer processing power has reached the point where finite impulse response (FIR) filters can assist in reducing loudspeaker time domain issues, more incremental progress continues being made in that area, as shown in this 2018 article:
https://audioxpress.com/article/a-loudspeaker-that-can-play-square-waves
Clearly, much progress has been achieved in the time domain since John Watkinson designed this speaker:[
ATTACH type="full"]1271881[/ATTACH]
Attachments
Last edited by a moderator:
Well supposedly the compliance drops, although the amounts typically seen get swamped by the box compliance and you end up with small changes in response if any. In electrical filter theory you can find some impulse or step response differences from Q of 0.5 to 0.577 to 0.7. How audible that is, lord only knows, and surely it also depends on the resonance frequency just to make things more complex. Someone around here had a spreadsheet that could convert that to a more visual tone burst thing which would help...they made an interesting point that lower Qs actually overdamped the rise of the tone burst and somewhat higher Qs were better. Perhaps best is a somewhat higher Q so long as the resonance frequency is kept low.I am not sure what you mean by this. Wavecor specifically says their measurements are before break in. Why they would do this is beyond me, but it is a safe assumption Q will drop, along with Fs and VAS will go up.
Very short ones!Could you please expand upon which particular acoustic phenomena have decay times measured in microseconds.
Emboldening the text does not make the statement correct. My previous post highlighted that for linear analysis, the time domain and frequency domain are entirely equivalent, and where non-linear analysis is employed, matters are more complicated than can be expressed by such a singular, regimented view. For a much more enlightened view of the actual thread subject, I whole-heartedly recommend reading Michael Gerzon's "Why do equalisers sound different?" that was originally published in Studio Sound.Hydrogen Alex said:
If one accepts (and some still dont!) that the the human ear brain / hearing mechanism is designed to detect and decode ALL sounds using the time domain then one MUST accept that number one goal in sound reproduction is to perfect the time domain performance of the source ie the loudspeaker transducer and the cabinet / loading of the finished design.
Moreover, the John Watkinson paper you cite also refers specifically to transient sounds and to concern only inter-aural time differences too. The paper further highlights the basilar membrane as emulating a bank of band-pass filters - that is acting as a frequency analyser! His above-quoted statement "if the imperfections in the speaker are less than the imperfections in the ear, then they will be indetectible" is also not true, and highlights his lack of consideration of the non-linear processing we readily exploit.
I find it hard to believe this paper was refereed, and find it much more likely it was "sales material" used to support Watkinson and Salter's venture into loudspeaker manufacturing with Celtic Audio - a venture that did not last long. That was a pity IMO because it exploited current drive (I believe) and a user-controlled LF roll-off. But I am old enough to remember Watkinson's AES presentation too, where the "acoustically small" loudspeaker's basic displacement limits were ruthlessly exposed; Watkinson eschewed such obvious problems. History showed well how right was his conjecture...
There are many more aspects of the paper that are confused too. For example, Watkinson writes "the dramatic increase in realism that is obvious to any unbiased listener when the original sound waveform accurately traverses the entire reproduction chain confirms that it is practically important." This is shown above a photograph of two (presumably) stereo loudspeakers that will guarantee the "original sound waveform" is not conserved! Words such as "dramatic" do not help, and such effect was certainly not apparent in practice.
I could go on, but I won't. It remains that your overly emphatic conjecture is confused and not based on sound principles or reasoning.
- Home
- Loudspeakers
- Subwoofers
- Bessel vs Critically Damped Enclosure