I might be ignorant, but I can not figure any IIR or FIR (electronic) method to eq late reflections indifferent from original impulse. Decay response is a character of the room, not the signal. Loudspeaker's radiation pattern makes a difference here and it should match room and room placement of speakers and listening spot/area.
The right way to deal with time domain irregularities is speaker selection, positioning and "room treatment" based on deep understanding of room acoustics.
As said previously, signal eq is first-aid and it must be used very carefully. It helps a little but it might lead to strange colorations of sound. High Q eqs are dangerous!
RoomEQWizard is based on FFT and gives many ways to look at time domain. The user can set analysis parameters and it takes some time to gain understanding to interprete the measured data. There are other freeware analyzers, but REW is favourite of many people.
During my AINOgradient project I have learned a lot of measurements and I have set the performance of the speaker so that it fits my room - radiation pattern, on-axis/off-axis and time domain spectrum all contribute to harmonic and balanced sound and good stereo imaging. I use room eq only to match left and right speaker balace at some parts of frequency band, but actually roomeq is bypassed most ot the time.
The right way to deal with time domain irregularities is speaker selection, positioning and "room treatment" based on deep understanding of room acoustics.
As said previously, signal eq is first-aid and it must be used very carefully. It helps a little but it might lead to strange colorations of sound. High Q eqs are dangerous!
RoomEQWizard is based on FFT and gives many ways to look at time domain. The user can set analysis parameters and it takes some time to gain understanding to interprete the measured data. There are other freeware analyzers, but REW is favourite of many people.
During my AINOgradient project I have learned a lot of measurements and I have set the performance of the speaker so that it fits my room - radiation pattern, on-axis/off-axis and time domain spectrum all contribute to harmonic and balanced sound and good stereo imaging. I use room eq only to match left and right speaker balace at some parts of frequency band, but actually roomeq is bypassed most ot the time.
Human hearing mechanism doesn't matter. Only physics of sound propagation. Sound is continuous variation of air pressure. All that matters is pressure variation at point of measurement. This may be microphone, or opening of ear canal. For frequencies <1kHz, the ear may be considered point receiver.
The degree to which a peak/dip in response may be modeled by PEQ type filter is limit to which a PEQ filter may be used in creating a flat response. This may described as center frequency, magnitude and Q.
Convolution of two PEQ filters of matching frequency and Q having opposite magnitude return a Dirac pulse at same peak location in time domain of original waveform.
Example, a modal peak of 6dBat 80Hz with a Q of 7. To correct it a filter with 6dB dip at 80Hz and Q of 7 is used.
How long does the correction filter need to be? Filter is IIR, but in practice may readily be truncated. In a world of 24bit sound systems, truncation to point in time from start of filter peak where level has decayed into noise floor of dithered 24bit system is good start. Filter may be shortened further with marginal loss of performance, for this example a 32bit filter is generated and converted to 24bit with dither to get approximate length for application.
Waveform of PEQ filters start with peak and have ringing tail corresponding to magnitude and Q of filter:

Above are waveforms of filters and corresponding spectra. Filters start at 1 second. Sample rate is 48kHz.
Lower track is correction filter. It is selected from 1 second start point out 10904 samples, about 0.23sec. This is convolved with entirety of top track with following result:

Result is Dirac pulse at 1sec. Noise level is seen to increase in resulting tail.
Resultant spectrum is flat to <1/1000th dB as seen here in zoomed view:

The degree to which a peak/dip in response may be modeled by PEQ type filter is limit to which a PEQ filter may be used in creating a flat response. This may described as center frequency, magnitude and Q.
Convolution of two PEQ filters of matching frequency and Q having opposite magnitude return a Dirac pulse at same peak location in time domain of original waveform.
Example, a modal peak of 6dBat 80Hz with a Q of 7. To correct it a filter with 6dB dip at 80Hz and Q of 7 is used.
How long does the correction filter need to be? Filter is IIR, but in practice may readily be truncated. In a world of 24bit sound systems, truncation to point in time from start of filter peak where level has decayed into noise floor of dithered 24bit system is good start. Filter may be shortened further with marginal loss of performance, for this example a 32bit filter is generated and converted to 24bit with dither to get approximate length for application.
Waveform of PEQ filters start with peak and have ringing tail corresponding to magnitude and Q of filter:
Above are waveforms of filters and corresponding spectra. Filters start at 1 second. Sample rate is 48kHz.
Lower track is correction filter. It is selected from 1 second start point out 10904 samples, about 0.23sec. This is convolved with entirety of top track with following result:
Result is Dirac pulse at 1sec. Noise level is seen to increase in resulting tail.
Resultant spectrum is flat to <1/1000th dB as seen here in zoomed view:
Yes, most definitely. I've had a DEQ2496 on my systems for nearly 10 years doing a combination of speaker and room correction. The key is how to measure and deciding what to correct and what not to "correct".With the availability of cheap and good quality parametric EQs I was wondering if they can be used for room/speaker correction.
Here are my thoughts:I'd like to hear everybody's thoughts on the topic. How can PEQs improve reproduction? Can we improve only a single point or even multiple points? What measurements need to be taken? How do we correlate them to what we hear? How to apply PEQs to mixed-phase responses? Etc. pp.
1) Steady state measurements are only perceptually valid at and below the Schroeder frequency (I draw the line somewhere around 200-250Hz) and "room correction" in general is also only valid at these low frequencies. (see small exception further down)
Measuring the full-range, steady state response at the listening position (typically pink noise, and typically containing very dense interference patterns in the frequency domain due to room reflections) and adjusting the EQ until this measures flat (or follows some "house curve") simply doesn't work. Unfortunately that's what most Auto-EQ systems (including the one in the DEQ2496) try to do.

Every different speaker directivity pattern and room combination will require a different "house curve" to sound right, showing that we're not measuring the right thing. I know speaker dave has talked at length in other threads over a number of years about this and the fact that at high frequencies its the frequency response of the first arrival that matters (eg direct field) not the omni-directional summed response that a steady state measurement is measuring. (Even if it was the summed steady state response we perceived our ears aren't omni-directional like the microphone so wouldn't sum to the same response!)
At higher frequencies (about 500Hz-1Khz and upwards) not only can you not do narrow band "room correction" with EQ, its also not actually desirable as its not perceptually valid. What you can do though, is correction of the speakers direct field response if there are errors or significant resonances in the speakers response.
On my systems I've used PEQ's (and a shelf) on the DEQ2496 to make three distinct but simultaneous corrections:
1) PEQ's to deal with room modes below 200Hz - basically notching the worst peaks to flatten out the bass response as best I can near the listening position. Unlike a graphic equaliser the PEQ gives fine control of the centre frequency and width of the notch which makes the correction MUCH more accurate that simply bumping the nearest EQ band up or down.
For these corrections I take a steady state measurement at and around the listening position.
2) Correction of significant speaker resonances and response aberrations at frequencies at and above about 1Khz. Ideally this should be done in the crossover but unless you've got ideal drivers and/or a complex crossover there will probably be uncorrected audible resonances that can be significantly improved with accurate PEQ's.
If a speaker has high frequency high Q resonances I don't find typical 1/3rd octave EQ to be of much use - the overall tonal balance might be improved somewhat but the harshness caused by the resonances remains. However if you identify the main resonances and precisely and individually correct them with a PEQ each, getting the centre frequency and Q exactly right (looking at the result with a CSD helps) they can be practically eliminated resulting in a major improvement in sound quality.
If the resonances are relatively far from the crossover frequencies and within the passband (not stopband) of the offending driver the minimum phase correction can be completely effective (just as good as if the correction was within that specific crossover section) but even if the resonance occurs near the crossover frequency (causing the phase not to be completely corrected) then I've found there is still quite a worthwhile improvement. (Not as much as correcting the resonance in the individual crossover section though, which can fix the phase response as well as improve driver integration)
For example on my system I had a crossover frequency of 4Khz, and had a peaking filter at 1Khz (correcting a surround dip resonance) notches at 2Khz and 4Khz (correcting a whizzer cone and main cone resonance respectively) and another small notch at 8Khz correcting a small relatively innocuous tweeter resonance. All PEQ's had their centre frequencies, Q's and amplitudes carefully optimised, and were optimised independently for left and right speakers as the resonances weren't exactly the same for both.
Sounds like a lot of effort but it really did make a huge difference to the sound quality IMO, and although not practical for mass production, for DIY with cheap easily adjustable digital EQ and good measuring systems like ARTA available, very doable.
For all of these high frequency corrections I measured the speakers not in their normal locations, but using a windowed reflection free measurement with the speaker up on a pedestal in the middle of the room - exactly as you would do when measuring the drivers and optimising the crossover. The key point being this is a direct field measurement NOT a "room" or steady state measurement, and you want the longest reflection free window you can get for best accuracy. I also found it important to optimise for the CSD not just the amplitude response as they don't always agree in a non minimum phase situation like a crossover.
3) Additional baffle step adjustment - knowing exactly how much baffle step to apply to a speaker is challenging because there is no right answer that's correct for every room - not just because different rooms will enhance the bass by different amounts but also because you're transitioning from perceiving the steady state response at low frequencies to the direct field response at high frequencies - so technically there is no "right" amount of baffle step for every room within a reflective environment since our perception mechanism is changing through the transition region...
So I use a PEQ in "shelf" mode to increase or decrease the speakers existing baffle step offset as needed - I typically only find it needs tweaking +/- 1dB or so depending on positioning in the room, but that tweaking of the offset between bass and high frequencies can make a lot of difference to imaging and presentation...
I haven't found any way to measure the required shelf precisely - probably because of the above mentioned problem of comparing steady state bass to direct field midrange...its a perceptual modelling problem, not a measurement problem per-se.
So I adjust this shelf purely subjectively once everything else is adjusted and the speakers are in their final locations. I also find that if I cut back the peaks in the bass region by correcting room modes that I have to increase the baffle step correction slightly to avoid the bass sounding too lean. The shelf gives an easy way to do this, and tweaking the roll-over frequency of the shelf a bit can help too.
The only exception to "don't EQ the room at high frequencies" I've ever used is applying a very gradual shelf reduction of say 1/2dB starting at 3Khz with a gradual slope to 10Khz or so - that can help in a room that's too "bright" sounding due to lack of room treatment, but its a band aid at best.
Even then the amount of shelf EQ required at the top end for a bright or dead room is typically only 1/2dB or at most 1dB - so not a huge amount.
Again I don't measure this, I adjust it purely subjectively if the room sounds a bit bright - on a reasonably treated room I've never found it necessary, only on one with all bare walls and sparse furniture - usually such a room has severe slap echo too so isn't a good listening environment anyway. The slight shelf just makes it a bit more listenable until the room can be improved.
Last edited:
There's more I don't know than what I do know.
That's the advantage man has over all things known of the universe; the search for discovery.
Unfortunately you couldn't be more wrong on this point - the human hearing mechanism matters a great deal in correlating measurements with perception.Human hearing mechanism doesn't matter. Only physics of sound propagation. Sound is continuous variation of air pressure. All that matters is pressure variation at point of measurement. This may be microphone, or opening of ear canal.
We don't perceive the steady state omni-directionally summed response at high frequencies, therefore such a measurement taken by a microphone and adjusted to be "flat" with EQ does not sound correct. Depending on speaker directivity and room characteristics it can be ridiculously, laughably wrong. (yes I've tried such EQ before many times)
There are many reasons for this, one is the HRTF of our ears/head at high frequencies means that not all reflections from all directions are summed equally like they are with a microphone.
Each reflection from each different direction has its frequency response modified by the HRTF before being summed making the final result that goes down the ear canal impossible to predict or correlate from an omni-directional microphone measurement. (The microphone is throwing away all directional information which alters the summed response)
But much more importantly it has been shown by research that we don't perceive the steady state frequency response at high frequencies - at high frequencies we perceive almost exclusively the frequency response of the direct (first arrival) signal, not the sum of the direct response and all the later reflections. The contribution to frequency response of the delayed reflections almost doesn't matter, perceptually.
Therefore attempting to apply "room EQ" at high frequencies based on a steady state omni-directional summed response is fundamentally utterly wrong.
There isn't a hard cut off between perceiving the direct field at high frequencies and the steady state response at bass frequencies - there is a transition/blending region.
Speaker dave has posted a number of references before on the subject (unfortunately I can't remember the names of the authors) where they propose that our perception of tonal balance is best modelled by a sliding window with a short window at high frequencies and a long window at low frequencies.
At low frequencies the window is very long and all reflections are included, ("steady state response") the higher you go the more reflections are excluded until above approx 2Khz (depending on delay to first reflection) all reflections are excluded from the perceptual window. ("direct field" only)
For frequencies <1kHz, the ear may be considered point receiver.
The degree to which a peak/dip in response may be modeled by PEQ type filter is limit to which a PEQ filter may be used in creating a flat response. This may described as center frequency, magnitude and Q.
Convolution of two PEQ filters of matching frequency and Q having opposite magnitude return a Dirac pulse at same peak location in time domain of original waveform.
Example, a modal peak of 6dBat 80Hz with a Q of 7. To correct it a filter with 6dB dip at 80Hz and Q of 7 is used.
How long does the correction filter need to be? Filter is IIR, but in practice may readily be truncated. In a world of 24bit sound systems, truncation to point in time from start of filter peak where level has decayed into noise floor of dithered 24bit system is good start. Filter may be shortened further with marginal loss of performance, for this example a 32bit filter is generated and converted to 24bit with dither to get approximate length for application.
Waveform of PEQ filters start with peak and have ringing tail corresponding to magnitude and Q of filter:
View attachment 395436
Above are waveforms of filters and corresponding spectra. Filters start at 1 second. Sample rate is 48kHz.
Lower track is correction filter. It is selected from 1 second start point out 10904 samples, about 0.23sec. This is convolved with entirety of top track with following result:
View attachment 395437
Result is Dirac pulse at 1sec. Noise level is seen to increase in resulting tail.
Resultant spectrum is flat to <1/1000th dB as seen here in zoomed view:
View attachment 395438
All very good but if you're measuring the wrong thing all the fancy correction in the world won't give you the right result.
You may correct the steady state response but what happens to the direct field with this correction applied ? If the speakers themselves are quite flat to begin with it will almost always be made worse, not better.
You're making the measurement that doesn't matter better at the expense of making the measurement that does matter worse!
I've been using PEQ to correct my speakers for quite a few years. I learned fairly early on that trying fix the mids and treble isn't worth it.
Fortunately, the auto-EQ in my pre-pro (Anthem ARC) can be set to only operate below 200Hz. And I can do it manually as well via my amp (Crown XTi) or crossover (MiniDSP).
I've heard all the arguments for and against, but in my experience judicious EQ of bass peaks both measures and sounds better. That's enough to convince me.
I am, however, selfish and EQ for one main position. Others who listen to my system don't care.
Fortunately, the auto-EQ in my pre-pro (Anthem ARC) can be set to only operate below 200Hz. And I can do it manually as well via my amp (Crown XTi) or crossover (MiniDSP).
I've heard all the arguments for and against, but in my experience judicious EQ of bass peaks both measures and sounds better. That's enough to convince me.
I am, however, selfish and EQ for one main position. Others who listen to my system don't care.
Where's Markus?
_____________
* Personally I use and let Audyssey MultEQ XT32 do its strut, automatically, up to a certain extent.
I perform manual microphone positioning (eight of them), I readjust manually my channel levels (for better sound wrapping bubble).
I manipulate my channel distances, in synchronicity with levels and listener moving position (main moving target seat).
And I also manually reset my Integra pre/pro's crossovers (all of them).
The only thing that I don't have full control over are the Finite Impulse Response filters (Time & Frequency Response domain).
But I use my manual set of ears to calibrate that; meaning that I'll repeat the microphone re-positioning (with variables), till I'm satisfy in my auditory dimensional world.
It doesn't have to be perfect for you, only perfect for me. ...That's my own room and my own surround sound hound experience.
And it's better with Audyssey MultEQ XT32 than without. ...For me it is; exponentially better overall atmospheric integrity. ...Sound that is.
Measurements (data)? I don't have. ...Sorry. ...Perhaps another day.
_____________
* Personally I use and let Audyssey MultEQ XT32 do its strut, automatically, up to a certain extent.
I perform manual microphone positioning (eight of them), I readjust manually my channel levels (for better sound wrapping bubble).
I manipulate my channel distances, in synchronicity with levels and listener moving position (main moving target seat).
And I also manually reset my Integra pre/pro's crossovers (all of them).
The only thing that I don't have full control over are the Finite Impulse Response filters (Time & Frequency Response domain).
But I use my manual set of ears to calibrate that; meaning that I'll repeat the microphone re-positioning (with variables), till I'm satisfy in my auditory dimensional world.
It doesn't have to be perfect for you, only perfect for me. ...That's my own room and my own surround sound hound experience.
And it's better with Audyssey MultEQ XT32 than without. ...For me it is; exponentially better overall atmospheric integrity. ...Sound that is.
Measurements (data)? I don't have. ...Sorry. ...Perhaps another day.
Last edited:
The bottom line appears to be,
Use parametric EQ below 300HZ, and use broad Baxandall tone controls for everything above that.
Since mic techniques are never quite the same as how the ear-brain mechanism hears, such measurements should be taken with a big grain of salt, especially at the higher frequencies where HRTF comes into play. And since EQ of the frequencies below 300HZ are usually only right for a given location in a typical room, other methods of flattening bass should be looked at, such as multiple woofer towers that can illuminate the room on all 3 axis, perhaps using dipole woofers for minimal room excitement, or at least alternate woofer locations relative to room boundaries. Did I get that right?
Use parametric EQ below 300HZ, and use broad Baxandall tone controls for everything above that.
Since mic techniques are never quite the same as how the ear-brain mechanism hears, such measurements should be taken with a big grain of salt, especially at the higher frequencies where HRTF comes into play. And since EQ of the frequencies below 300HZ are usually only right for a given location in a typical room, other methods of flattening bass should be looked at, such as multiple woofer towers that can illuminate the room on all 3 axis, perhaps using dipole woofers for minimal room excitement, or at least alternate woofer locations relative to room boundaries. Did I get that right?
The bottom line appears to be,
Use parametric EQ below 300HZ, and use broad Baxandall tone controls for everything above that.
Since mic techniques are never quite the same as how the ear-brain mechanism hears, such measurements should be taken with a big grain of salt, especially at the higher frequencies where HRTF comes into play. And since EQ of the frequencies below 300HZ are usually only right for a given location in a typical room, other methods of flattening bass should be looked at, such as multiple woofer towers that can illuminate the room on all 3 axis, perhaps using dipole woofers for minimal room excitement, or at least alternate woofer locations relative to room boundaries. Did I get that right?
Frequencies of the full audio spectrum, from 20Hz to 20kHz are only best at only one specific room's spot. ...Overall average.
At another spot in the room you'll have better at a certain audio frequency but also worst at another audio frequency.
The aim is the overall average; there is only that much we can do.
Audyssey MultEQ XT32 by the way; it concentrates in the lower frequencies of the human range, from 10Hz to 300Hz (or so I believe), where of course it makes the biggest sound improvement. ...Markus would know for certain; next time he'll come back from his trip.
Get the low frequencies right, and you're half way, if not more, to get the high frequencies right as well.
...And no matter how good you can EQ the high frequencies; with each sound recording it is still a moving target.
...The year the recording was made, the medium, the engineer, the studio (or other recording venue), the microphone(s) used, their position, the instruments played (their distinctive tonality from their make), the strings used (all string instruments), the reeds (wind instruments), the singer vocals (internal chords and throat), the studio's own acoustics, the mixing console and its degree of sliders' controls, the recording machine, the amount of various type of EQs applied (reverb, flange, sustain, dynamic compression, dbx, distortion, digital delay, etc.), and the overall levels (of the two channels, or the 7.1 channels, or any other number of channel levels).
...The year the recording was made, the medium, the engineer, the studio (or other recording venue), the microphone(s) used, their position, the instruments played (their distinctive tonality from their make), the strings used (all string instruments), the reeds (wind instruments), the singer vocals (internal chords and throat), the studio's own acoustics, the mixing console and its degree of sliders' controls, the recording machine, the amount of various type of EQs applied (reverb, flange, sustain, dynamic compression, dbx, distortion, digital delay, etc.), and the overall levels (of the two channels, or the 7.1 channels, or any other number of channel levels).
...And even the cables and interconnects used in that recording venue.
...And the monitors used because that's what the mixing/recording engineer heard from.
...After it was recorded from the live event (concert hall, studio, auditorium, cabaret, arena, club, and even from various recording spaces in one recording).
...Mixes and dubs.
...And the monitors used because that's what the mixing/recording engineer heard from.
...After it was recorded from the live event (concert hall, studio, auditorium, cabaret, arena, club, and even from various recording spaces in one recording).
...Mixes and dubs.
Last edited:
I would encourage folks to look at JJ's papers on psychoacoustics for room correction that I linked to earlier.
There are also links on the REW forum that go into this as well:
Psychoacoustically-Correct room correction - Home Theater Forum and Systems - HomeTheaterShack.com
Nudges for future versions - Home Theater Forum and Systems - HomeTheaterShack.com
Wrt, Acourate calculates a psychoacoustic frequency response. It fills the holes in the frequency response and then uses the new response for filter calculation. Therefore it avoids overboosts.
Typically a FFT shows a steady state behavior. But music is not steady state, it also has transients. A FFT is not good for showing transients, indeed it looses the frequency-time relationship.
I will be the first to admit, I am not an expert in this field, but I have done a lot of research over several years and have used just about every type of eq and room correction product on the market.
As mentioned there are very few software products that can measure, analyze and generate filters that are psychoacoustically correct. Frequency dependent windowing (FDW) is absolutely key if anyone takes the time to read JJ's papers or look at those REW links.
In the end, the ears are the final judge, and to my ears having tried almost every room correction product on the market, the ones that do it right can be counted on one hand. Acourate, Audiolense, Denis' DRC and Dirac Live are the only products I know of that employ FDW and generate psychoacoustically correct room corrections.
Give it a trial and judge for yourself. Best of luck, Mitch
There are also links on the REW forum that go into this as well:
Psychoacoustically-Correct room correction - Home Theater Forum and Systems - HomeTheaterShack.com
Nudges for future versions - Home Theater Forum and Systems - HomeTheaterShack.com
Wrt, Acourate calculates a psychoacoustic frequency response. It fills the holes in the frequency response and then uses the new response for filter calculation. Therefore it avoids overboosts.
Typically a FFT shows a steady state behavior. But music is not steady state, it also has transients. A FFT is not good for showing transients, indeed it looses the frequency-time relationship.
I will be the first to admit, I am not an expert in this field, but I have done a lot of research over several years and have used just about every type of eq and room correction product on the market.
As mentioned there are very few software products that can measure, analyze and generate filters that are psychoacoustically correct. Frequency dependent windowing (FDW) is absolutely key if anyone takes the time to read JJ's papers or look at those REW links.
In the end, the ears are the final judge, and to my ears having tried almost every room correction product on the market, the ones that do it right can be counted on one hand. Acourate, Audiolense, Denis' DRC and Dirac Live are the only products I know of that employ FDW and generate psychoacoustically correct room corrections.
Give it a trial and judge for yourself. Best of luck, Mitch
Wrt, Acourate calculates a psychoacoustic frequency response. It fills the holes in the frequency response and then uses the new response for filter calculation. Therefore it avoids overboosts.
Thanks Northstar. I usually don't quote myself, but when I do
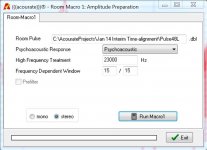
Attached is the dialog box that is applying the variable frequency domain windowing to calculate the psychoacoustic frequency response. Another dialog box also uses FDW to correct phase response, but that is another topic for another time.
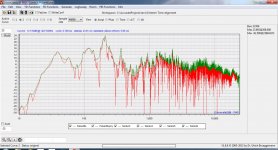
The result of which can be seen in the chart. The red trace is the non-smoothed or raw frequency response. The green trace is the psychoacoustic frequency response. Note the difference in both the low frequencies AND the high frequencies.
It is the green (psychoacoustic) response that is used to calculate the FIR filter. Note how this is different than virtually any other room measurement/correction software, except the ones using FDW. The end result also sounds very different. And to my ears, superior to anything else I have heard by a large margin.
Attachments
Markus is the graph 'decipherist' expert. I'm just an observer, an occasional commentator.
I simply don't know how to correlate graphic pictures with audio pleasantness. ...Or very basically.
But I can easily see the much smoother green response line; and preferable base for calculating the FIR filter taps.
Mitch, Dirac Live you can get a program from your PC or Mac. ...Any other one which also uses FDW, and available from online and downloadable?
I simply don't know how to correlate graphic pictures with audio pleasantness. ...Or very basically.
But I can easily see the much smoother green response line; and preferable base for calculating the FIR filter taps.
Mitch, Dirac Live you can get a program from your PC or Mac. ...Any other one which also uses FDW, and available from online and downloadable?
Unfortunately you couldn't be more wrong on this point - the human hearing mechanism matters a great deal in correlating measurements with perception.
We don't perceive the steady state omni-directionally summed response at high frequencies, therefore such a measurement taken by a microphone and adjusted to be "flat" with EQ does not sound correct. Depending on speaker directivity and room characteristics it can be ridiculously, laughably wrong. (yes I've tried such EQ before many times)
There are many reasons for this, one is the HRTF of our ears/head at high frequencies means that not all reflections from all directions are summed equally like they are with a microphone.
Each reflection from each different direction has its frequency response modified by the HRTF before being summed making the final result that goes down the ear canal impossible to predict or correlate from an omni-directional microphone measurement. (The microphone is throwing away all directional information which alters the summed response)
But much more importantly it has been shown by research that we don't perceive the steady state frequency response at high frequencies - at high frequencies we perceive almost exclusively the frequency response of the direct (first arrival) signal, not the sum of the direct response and all the later reflections. The contribution to frequency response of the delayed reflections almost doesn't matter, perceptually.
Therefore attempting to apply "room EQ" at high frequencies based on a steady state omni-directional summed response is fundamentally utterly wrong.
There isn't a hard cut off between perceiving the direct field at high frequencies and the steady state response at bass frequencies - there is a transition/blending region.
Speaker dave has posted a number of references before on the subject (unfortunately I can't remember the names of the authors) where they propose that our perception of tonal balance is best modelled by a sliding window with a short window at high frequencies and a long window at low frequencies.
At low frequencies the window is very long and all reflections are included, ("steady state response") the higher you go the more reflections are excluded until above approx 2Khz (depending on delay to first reflection) all reflections are excluded from the perceptual window. ("direct field" only)
All very good but if you're measuring the wrong thing all the fancy correction in the world won't give you the right result.
You may correct the steady state response but what happens to the direct field with this correction applied ? If the speakers themselves are quite flat to begin with it will almost always be made worse, not better.
You're making the measurement that doesn't matter better at the expense of making the measurement that does matter worse!
Audio recording and playback is information storage and retrieval system. It has nothing to do with human hearing as the end user.
Speaker transducers have natural responses far from flat. They are readily corrected across their intended operating bandwidth.
This is raw response of woofer and tweeter of small 2-way system:
An externally hosted image should be here but it was not working when we last tested it.
Measurements are on listening axis from about 9". No smoothing, no gating.
After correction with crossover filters applied:
An externally hosted image should be here but it was not working when we last tested it.
Summed response with both drivers operating:
An externally hosted image should be here but it was not working when we last tested it.
With tweeter polarity reversed the null at crossover point is deep and symmetrical:
An externally hosted image should be here but it was not working when we last tested it.
From the listening position with 3ms windowing to exclude room reflections demonstrates direct sound received by listener:
An externally hosted image should be here but it was not working when we last tested it.
The above measurement with 170ms window brings in effects of room:
An externally hosted image should be here but it was not working when we last tested it.
The peaks and dips are very narrow. They are totally natural occurrence, and correspond to how sound would be heard in room if speaker were replaced by live instrument. Peak and dip locations are completely dependent on speaker/listener location. Correction would require very high Q filters, and would only be applicable to single speaker/listener orientation. From psychoacoustic perspective they are invisible in terms of perceived frequency response, but provide cues to listener of distance and space.
Same technique used with subwoofer:
An externally hosted image should be here but it was not working when we last tested it.
This is measurement at listening position with 1365ms window with no smoothing. Low frequency room modes are well controlled.
You have tried some sort of EQ many times?
Did your measurement results look like these?
The sound is super. Here is waveform of a single drum strike, top track is source from CD and lower track response recording. The first shot is about 100ms and the second shot is about 10ms:
An externally hosted image should be here but it was not working when we last tested it.
And:
An externally hosted image should be here but it was not working when we last tested it.
If I'm not hearing what was in the recording, then what?
But, if you start making EQ corrections based on in room measurements, particularly made at the normal listening position you MUST take into account how the human hearing system works. That was my point.Audio recording and playback is information storage and retrieval system. It has nothing to do with human hearing as the end user.
You can't just plonk down a microphone at the listeners normal head location, speakers located at their normal locations, make a full spectrum "steady state" measurement and apply EQ from 20Hz to 20Khz until this steady state response looks flat.
This does not work. Do you disagree with this ? If you agree with this, I don't see what we're arguing about.
Absolutely, I agree completely - and I explained at length earlier how I approach that. Most of the response errors are dealt with in the crossover, however for any remaining aberrations that the speakers themselves have from about 1Khz upwards, I measure with the speakers up on a stand in the middle of the room with a reflection free windowed measurement taken at about 1 - 1.5 metres, the same as you would when doing crossover design.Speaker transducers have natural responses far from flat. They are readily corrected across their intended operating bandwidth.
In other words I'm trying to get a measurement of the speakers high frequency response with NO room contribution. I then adjust those PEQ's that are allocated to high frequency correction under these measuring conditions and save them in the PEQ's memory.
What I do NOT do is try to measure and correct the high frequency response of the speakers with them at their normal location in the room (insufficient reflection free window for an accurate measurement) nor with the microphone at the listening position. (Even less reflection free window)
Even with a frequency based sliding window approach there isn't enough margin in the window size to get a truly accurate measurement of the speakers high frequency response such that you could correct individual resonances at high frequencies.
Actually such high Q correction of the steady state response at high frequencies would not be applicable at ANY single speaker/listener orientation, because we are not perceiving the steady state response that you are measuring.The peaks and dips are very narrow. They are totally natural occurrence, and correspond to how sound would be heard in room if speaker were replaced by live instrument. Peak and dip locations are completely dependent on speaker/listener location. Correction would require very high Q filters, and would only be applicable to single speaker/listener orientation.
We "hear through" the steady state response to hear the direct signal and its frequency response (which is smooth, not spiky like the summed response) so any such high Q correction sounds bad because the direct response now has lots of narrowband up and down swings in the response.
They're invisible in terms of perceived frequency response not so much because the peaks and dips are narrow (critical band smoothing) but because we're tuning in to the first arrival - the later reflections contribute to ambience and space, but not to perceived tonal balance nor sound quality, unless the reflections are really strong to the point that they're overpowering.From psychoacoustic perspective they are invisible in terms of perceived frequency response, but provide cues to listener of distance and space.
I'm not sure what you're trying to prove with your measurements, because my whole argument was that you can't measure steady state response at the listener position and EQ based on that.You have tried some sort of EQ many times?
Did your measurement results look like these?
All the high frequency EQ in your examples is based on measurements made close up which are largely reflection free measurements of the speakers with little room contribution - so I don't disagree with this.
Last edited:
@barleywater
Now try to measure at different locations, even small ones. Consider that you have EQ'ed out reflections, which you have measured with the microphone, but which come from e.g. the side wall, which means that your ear will perceive a completely different signal (thikn about HRTF), or the signal will never reach the ear (reflections from the left, right ear is shadowed).
Doing such a brute force method does not take these thing into account. The result will be, in my experience, better than without EQ, but it is not optimal.
Now try to measure at different locations, even small ones. Consider that you have EQ'ed out reflections, which you have measured with the microphone, but which come from e.g. the side wall, which means that your ear will perceive a completely different signal (thikn about HRTF), or the signal will never reach the ear (reflections from the left, right ear is shadowed).
Doing such a brute force method does not take these thing into account. The result will be, in my experience, better than without EQ, but it is not optimal.
- Status
- This old topic is closed. If you want to reopen this topic, contact a moderator using the "Report Post" button.
- Home
- General Interest
- Room Acoustics & Mods
- Room Correction with PEQ