fredex said:
<snip>
Yes it does work the other way.....er.... but only if the test conditions are different from the normal. I am more interested in the hearing ability of just one individual and I see no reason why the test can't be carried out in that person's livingroom with their speakers and as much time as they need. Surely a couple of books to hide any visual clues would not degrade their hearing ability.
Also when they are listening normally for audible differences under non DBTing conditions, aren't they likewise under some sort of self imposed stress which could affect their hearing ability.
Sure, during the operationalisation step the experimentator should think about all internal and external confounders. Some of these things will shorten the time needed for training, some will lead to extended training time.
But finally the experimentator has to use positive and negative controls to ensure that things are _real_ and not only assumed to be _real_ .
But, maybe one has to conduct a few blind tests first by himself to realize where the problems are. 🙂
P.S. Test conditions are always different from the normal situation
Jakob2 said:........But, maybe one has to conduct a few blind tests first by himself to realize where the problems are. 🙂..............
To get scientifically valid results is obviously quite complex and I am no expert in these matters, but your quoted above is a very good idea. I have done some BTs at home and my experience echoed all of the reported tests (scientifically correct or not) that I read about.
Simply put my hearing wasn't as good as I imagined. But until some one has found out this for themselves it is extremely difficult or impossible to convince them.
But surely there must be at least one test out there that can't be dismissed?
There's NEVER a test that someone can't dismiss. The world is full of people who deny that the Earth is round, that the Holocaust happened, the atomic theory of matter, evolution by natural selection, relativity... At a certain point, one has to just smile and back out of the room slowly.
SY said:There's NEVER a test that someone can't dismiss. The world is full of people who deny that the Earth is round, that the Holocaust happened, the atomic theory of matter, evolution by natural selection, relativity... At a certain point, one has to just smile and back out of the room slowly.
/OT on
I have often found it quite ironic that evolution has produced humans with the capacity to deny their own evolution....😉
/OT off
Jan Didden
LOLAt a certain point, one has to just smile and back out of the room slowly.
fredex said:
To get scientifically valid results is obviously quite complex and I am no expert in these matters, but your quoted above is a very good idea. I have done some BTs at home and my experience echoed all of the reported tests (scientifically correct or not) that I read about.
Simply put my hearing wasn't as good as I imagined. But until some one has found out this for themselves it is extremely difficult or impossible to convince them.
But surely there must be at least one test out there that can't be dismissed?
To start with the last; actually a lot of tests in the audio field i´m aware of (and of course that means which are published and documented in detail, so that careful analysis is possible) are at least in some parts questionable.
Especially that controls are so often omitted is out of all reason.
Just for an example, take the linked before master thesis study done in Detmold with help from the Emil Berliner Studios in Berlin. Interest of study was the comparision of DSD vs. PCM (both high resolution versions) with 145 participants by using an ABX-Box.
20 trials and the outcome was that 4 participants were able to pass the ABX (means were able to detect a difference between the DSD- and the PCM presentation), so the nil hypothesis could be rejected.
Unfortunately no controls were incorporated and the time frame didn´t allow for further tests with these participants.
Now compare that result with the Meyer/Moran-tests; documentation wasn´t exactly on par with detmold, number of participants was high, no controls were incorporated, no measurements as well (afair); the outcome was that the nil hypothesis could not be rejected.
So, what to do with these diverging test results?
Would controls have been incorporated, we would at least have an impression what these results could mean.
In the end there exists the same problem with your own tests; which way do you decide whether a difference is really detectable or just not detectable by yourself due to different test conditions?
I know that a lot of people are willing to question their hearing ability after failing in blind tests, but i know from first hand experience over the years, that it is quite often just a matter of training. That means some people fail in blind test at first, but after doing some training under these conditions were able to pass the tests repeatable.
As SY pointed out, something can always be questioned, and there is nothing wrong with questioning as it is part of scientific progress.
janneman said:I have often found it quite ironic that evolution has produced humans with the capacity to deny their own evolution....😉
Otherwise expressed as the rationality to deny reason when it contradicts belief. Since I appear to have the most concern regarding these test protocols, does anyone have a reasoned objection to those raised or will it left at 'some people'?
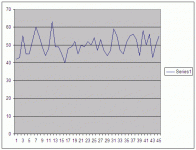
Take a look again at milosz's '53%' result. Assume no difference was audible in principle as claimed and the results were due to pure chance. random.org was used to create a table populated with random zeroes and ones, 4500 cells arranged 100 columns by 45 rows representing 45 trials of 100 A/B choices. Let 1 represent a correct choice, 0 incorrect.
Take a look at the graph below of each row's total. The outlying values of correct answers for '45 subjects making 100 forced choices' are 63 and 40. 24 'subjects', more than half, exceed the max 3 deviation milosz found none exceeded. How many trials are required of each of the 45 subjects before milosz's results can reasonable be ascribed to pure chance? Are you still comfortable with those results? Would you accept them from a dowser?
It's possible the random number generator I used wasn't truly random, or my analysis flawed, something trivial to correct for those with the statistical chops I lack.
Attachments
rdf said:It's possible the random number generator I used wasn't truly random, or my analysis flawed, something trivial to correct for those with the statistical chops I lack.
May I refresh your probability math knowledge. Recall the Law of Large Numbers (LLN); this famous theorem comes in two forms, the weak form and the strong form.
The weak form states that the sample average converges in probability, that is, given a certain error E, there is always a finite N1 number of coin flips required to get the sample average error under E.
The strong form states that the sample average almost surely converges to the theoretical average, that is, given a certain error E, there is always a finite N2 number of coin flips so that the probability to have the sample average right on spot is 1-E.
Now, given a single small number E, which one is larger, N1 or N2? It can be shown that, with high probability, N1 is always larger. This means that you need much more flip coins to actually get the sample average at 53% (that is, E=3%) than you need to assume the sample average is true with a 97% probability (that is, 100%-3%).
So I think your randomizing experiment is not comparing apples and apples. You would need a much larger N1 number than the N2 required in the M&M test.
This is not to mean that M&M test was statistically flawless. I think they know it, so that's why they did not claim there was no audible difference, but only claimed that if there was a difference it was to small to detect. Statistically speaking, this is still a strong result which raises legitimate questions regarding the significance of this difference. As long as there are other variables which have a much stronger impact (like the quality of the original recording) do we really need to be concerned about CD/SACD differences? As SY mentioned, everything can be debated, and it always makes sense, unless a) comes against the fundamental laws (pepetuum mobile, wire directionality, etc...) b) the cause/effect relationship is weaker than we should care about (we don't consider the impact of the Heisenberg uncertainty principle in our audio amps, or should we? 😀).
syn08 said:
<snip>
Statistically speaking, this is still a strong result which raises legitimate questions regarding the significance of this difference.
rdf was not referring to the M/M but to the ´miliosz test´(brought up by janneman) and in detail to the fact that out of 45 participants no one got more than 53% correct answers by _pure_ _chance_ .
Given the usual quite small number of trials that is a bit surprising indeed. Of course we really don´t know about the details in his test...
What do we know about a difference that would have been detected in the M/M test?
I don´t see which way the result could qualify as a `strong result` as we don´t know about how small a difference must be to remain undetected in this test.
Jakob2 said:Given the usual quite small number of trials that is a bit surprising indeed. Of course we really don´t know about the details in his test...
Perhaps, though it's still fair to hypothesize. My kludge graph suggests 100 trials per test subject as inadequate to confidently reach a 3% error level in this kind of test. I'll trust syn08's superior knowledge of stats to correct. Take the min number of individual tests per subject necessary and further multiply it by the minimum listening time spent comparing A&B per selection considered 'responsible'. To pull numbers from the air, say each subject is required to complete 200 trials for E=3% and an average of 30 seconds comparing the two sources before making a choice. The total is 75 hours for 45 subjects - an hour-forty per - in concentrated, uninterrupted listening tests alone. To my eye this goes against the description provided, further raising suspicion something in the protocol was broken.
rdf said:
Perhaps, though it's still fair to hypothesize. My kludge graph suggests 100 trials per test subject as inadequate to confidently reach a 3% error level in this kind of test. I'll trust syn08's superior knowledge of stats to correct. Take the min number of individual tests per subject necessary and further multiply it by the minimum listening time spent comparing A&B per selection considered 'responsible'. To pull numbers from the air, say each subject is required to complete 200 trials for E=3% and an average of 30 seconds comparing the two sources before making a choice. The total is 75 hours for 45 subjects - an hour-forty per - in concentrated, uninterrupted listening tests alone. To my eye this goes against the description provided, further raising suspicion something in the protocol was broken.
kinda points out what i've been trying to get across.
The tests are simply not adequate to claim
no one can xxx here's proof
a perfectly good idea...
to put things into someone else's words:
myhrrhleine:
These are pretty profound, albeit , simple words that are the crux of the total ABX testing that goes on.
The AES would be well served (and all of us audio-geeks too) to sponsor a grad study on the reliability of ABX testing and physiological responses to the change of equipment, everything else being equal. This could occur as a questionaire, or even a simple ECG or EEG per person, but done en masse (perhaps 50 subjects at a time?). The collection of data could occur over a period of several trade shows (CES, CEDIA, etc), where the public and professionals could listen. No discussions per say, but questionnaires and data matched to participant identity numbers (but no other identifiers used). Questions could be limited to casual listener, hobbyist, professional, musician, age, gender , race, occupation (obviously industrial workers may have significantly reduced hearing), typical listening habits, etc.
Once a complete data set with corresponding notes and cross references were tabulated and entered into a data base, then all sorts of analysis could occur. Easily over a 5 day period, I could imagine 1000 plus subjects being "tested".
I think that in that situation, a reasonable picture of that test population could be put together. It could be that a disproportionate number of white guys in a particular age bracket could be the dominating group in said study, but at least there would be a way to actually make note of that (not to say that female, non-Caucasians are not important, but if in North America, in the audio hobby, I believe Caucasian men make up a majority of those interested in audio). Just an idea.
Perhaps I have an over simplified view, but if I believe I can hear a difference (personally), who cares?
stew
to put things into someone else's words:
myhrrhleine:
It's not that the test is wrong. It's just the wrong kind of test for this situation.
These are pretty profound, albeit , simple words that are the crux of the total ABX testing that goes on.
The AES would be well served (and all of us audio-geeks too) to sponsor a grad study on the reliability of ABX testing and physiological responses to the change of equipment, everything else being equal. This could occur as a questionaire, or even a simple ECG or EEG per person, but done en masse (perhaps 50 subjects at a time?). The collection of data could occur over a period of several trade shows (CES, CEDIA, etc), where the public and professionals could listen. No discussions per say, but questionnaires and data matched to participant identity numbers (but no other identifiers used). Questions could be limited to casual listener, hobbyist, professional, musician, age, gender , race, occupation (obviously industrial workers may have significantly reduced hearing), typical listening habits, etc.
Once a complete data set with corresponding notes and cross references were tabulated and entered into a data base, then all sorts of analysis could occur. Easily over a 5 day period, I could imagine 1000 plus subjects being "tested".
I think that in that situation, a reasonable picture of that test population could be put together. It could be that a disproportionate number of white guys in a particular age bracket could be the dominating group in said study, but at least there would be a way to actually make note of that (not to say that female, non-Caucasians are not important, but if in North America, in the audio hobby, I believe Caucasian men make up a majority of those interested in audio). Just an idea.
Perhaps I have an over simplified view, but if I believe I can hear a difference (personally), who cares?
stew
Jakob2 said:That means some people fail in blind test at first, but after doing some training under these conditions were able to pass the tests repeatable.
I saw this all the time in the printing biz. A layman would see no difference at all - until it was pointed out. Then they would start to find all sorts of differences.
But they would forget their "training" given a day or two.
Those who do it for a living do not lose the ability so quickly.
Ears and noses can also be trained.
Re: a perfectly good idea...
There one example of a study which tries to get more objective data by using EEG and PET :
http://jn.physiology.org/cgi/reprint/83/6/3548.pdf
But it was not related to ABX testing but to the impact of high frequency content (means content above 20kHz) on listeners. (and was unfortunately partly questionable due to possible side effects, but an interesting reading anyway)
The both official recommend test procedures ITU BS.1116 and ITU, BS. 1534-1 (MUSHRA) do not use the ABX protocol but choose a ABC/HR scheme with some sort of (crude) controls. ´crude`in this case means that they use a negative control, but the positive control(s) present quite big differences.
Nanook said:<snip>
The AES would be well served (and all of us audio-geeks too) to sponsor a grad study on the reliability of ABX testing and physiological responses to the change of equipment, everything else being equal. This could occur as a questionaire, or even a simple ECG or EEG per person, but done en masse (perhaps 50 subjects at a time?). The collection of data could occur over a period of several trade shows (CES, CEDIA, etc), where the public and professionals could listen. No discussions per say, but questionnaires and data matched to participant identity numbers (but no other identifiers used). Questions could be limited to casual listener, hobbyist, professional, musician, age, gender , race, occupation (obviously industrial workers may have significantly reduced hearing), typical listening habits, etc.
Once a complete data set with corresponding notes and cross references were tabulated and entered into a data base, then all sorts of analysis could occur. Easily over a 5 day period, I could imagine 1000 plus subjects being "tested".
I think that in that situation, a reasonable picture of that test population could be put together. It could be that a disproportionate number of white guys in a particular age bracket could be the dominating group in said study, but at least there would be a way to actually make note of that (not to say that female, non-Caucasians are not important, but if in North America, in the audio hobby, I believe Caucasian men make up a majority of those interested in audio). Just an idea.
Perhaps I have an over simplified view, but if I believe I can hear a difference (personally), who cares?
stew [/B]
There one example of a study which tries to get more objective data by using EEG and PET :
http://jn.physiology.org/cgi/reprint/83/6/3548.pdf
But it was not related to ABX testing but to the impact of high frequency content (means content above 20kHz) on listeners. (and was unfortunately partly questionable due to possible side effects, but an interesting reading anyway)
The both official recommend test procedures ITU BS.1116 and ITU, BS. 1534-1 (MUSHRA) do not use the ABX protocol but choose a ABC/HR scheme with some sort of (crude) controls. ´crude`in this case means that they use a negative control, but the positive control(s) present quite big differences.
rdf said:
Perhaps, though it's still fair to hypothesize. My kludge graph suggests 100 trials per test subject as inadequate to confidently reach a 3% error level in this kind of test. I'll trust syn08's superior knowledge of stats to correct. Take the min number of individual tests per subject necessary and further multiply it by the minimum listening time spent comparing A&B per selection considered 'responsible'. To pull numbers from the air, say each subject is required to complete 200 trials for E=3% and an average of 30 seconds comparing the two sources before making a choice. The total is 75 hours for 45 subjects - an hour-forty per - in concentrated, uninterrupted listening tests alone. To my eye this goes against the description provided, further raising suspicion something in the protocol was broken.
But the assumption is a bit misleading; reported is only that no participant got more than 53% correct answers.
So if we think that the participants don´t hear any difference and no other factors did allow to reliable detect a difference, then we have to assume that they are just guessing.
So, we would ask for the probability that the correct answers from 45 participants could fall into the intervall from 0%-53%, when the listeners are just guessing.
Normal rounding would require at least 30 trials to get to the 53% mark.
Jakob2 said:Normal rounding would require at least 30 trials to get to the 53% mark.
That still doesn't sound correct Jackob2. That essentially says that in 30 coin flips heads will come up between 14 and 16 times to a high degree of confidence through 45 trials. Seems statistically extremely unlikely. That's not a bell curve, it's a spike!
rdf said:
That still doesn't sound correct Jackob2. That essentially says that in 30 coin flips heads will come up between 14 and 16 times to a high degree of confidence through 45 trials. Seems statistically extremely unlikely. That's not a bell curve, it's a spike!
Sorry for the hazzle; what i meant was, that it takes at least 30 trials with 16 correct answer, to say (after rounding off) it was 53% correct. Due to the digital nature of these experiments the steps are quite high, but he reported in percentage.
So for the 30 trial example, his report would mean that all of the participants had correct answers falling in the interval from 0 - 16 .
Given that the binominal distribution is a symmetrical distribution that would be indeed a surprising result. 🙂
But as pointed out before, we don´t know exactly about the details. Maybe the memory got a bit weak in these details due to the quite long time frame.
rdf said:
That still doesn't sound correct Jackob2. That essentially says that in 30 coin flips heads will come up between 14 and 16 times to a high degree of confidence through 45 trials. Seems statistically extremely unlikely. That's not a bell curve, it's a spike!
Honestly guys I don't really follow what you are debating here, but here's some insights on this 30-45 times coin flip.
Instead of flipping the coin thirty times, you can actualy do a gedankenexperiment and flip thirty coins at a time, 45 times.
Now, in a 30 coin flip, how many possibilities to get 14, 15 or 16 heads do we have? That easy: 30!/[14!*(30-14]! + 30!/[15!*(30-15]! + 30!/[16!*(30-16]! = 145,422,675 + 155,117,520 + 145,422,675 = 445,962,870
And in how many way can we throw 30 coins? Obviously 2^30, that is 1,073,741,824 So what is the probability to get in a 30 coins throw 14, 15 or 16 heads? P = 445,962,870/1,073,741,824 = 0.415 Side note: the distribution of heads in a thirty coin flip is indeed a gaussian curve which approximates what is called "the probability density")
Now, assume the whole 30 coin flip as a independent experiment, call it "successfull" if you got 14, 15 or 16 times head (and the success has a probability of 0.415) and "failure" otherwise (and the failure has a probability of 1 - 0.415 = 0.585). What you are now doing is effectively throwing an "unfair coin", 45 times. Now, what are you looking for in this new experiment?
If instead of 45 throws you would use a very large number, then you could confirm the probability of success ( =0.415 ) or failure ( =0.585 ) in the 30 coin flip. But this will not tell you more about what is the average flip coin probability!
A single flip renders either a "success" or a "failure". You can now calculate yourself, using the above, what is the probability that after 45 throws to get about 19 "successes" ( 45*0.415 ).
Hint: you have to ponder the number of possible cases with the event probability.
syn08 said:A single flip renders either a "success" or a "failure". You can now calculate yourself, using the above, what is the probability that after 45 throws to get about 19 "successes" ( 45*0.415 ).
Milosz got 45/45 successes. The odds of that?
- Status
- Not open for further replies.
- Home
- General Interest
- Everything Else
- AES Objective-Subjective Forum