If the original signal is impulse separated by enough time so that the reflections do not get mixed with the subsequent impulses, then it's fine. But if the original source is MLS type sequence, editing out the tail means also editing out the low frequency decay characteristics.john k... said:
That would be fine, but I don't see where this has to do with cepstral editing. If I could generate an impulse sequence that represents the room then it could be subtracted form the basic impulse response.
Knowing the concept, the math wizards can figure it out. Hope we get better tools.DDF said:
I haven't been too forthcoming regarding the exact technique, but that's consciously. Fundamentally there is enough info known in perhaps 2 to 3 measures to be able to solve this.
The optimization would occur in the quefrency domain as it better suits the optimization method.
I appreciate we can’t achieve closure on this discussion when the algorithm details aren't revealed, nor the background techniques. However, I’m surprised that it can be so readily dismissed and critiqued, without this information.
")
DDF said:
I appreciate we can’t achieve closure on this discussion when the algorithm details aren't revealed, nor the background techniques. However, I’m surprised that it can be so readily dismissed and critiqued, without this information.
I am surprised that you want us to take this discussion seriously when you won't tell us what you plan to do.
No disrespect intended, but signal processing is what I do too and what you are claiming just doesn't fit with the math capabilities of Spectral Estimation (the name of what you are talking about). Spectral Estimation is a highly evolved field due to its fundamental usage in sonar.
My paper was in the JAES about 15 years ago.
The bottom line here is that we can reconstruct missing (edited) data almost perfectly IF we know some parameters of the underlying system. But if it is that system is precisely what we are testing then our "estimate" can be no better than our "guess" as to what the undeying system parameters are.
If we know for example that the underlying system is a close box with a given Q and resonant frequency, then I can exactly reconstruct the impulse response, Ceptrum, whatever (linearity assumed of course) well into edited areas with a very high precision (that decreases with number of estimated points). This is done in Praxis and his implimentation is the best that I have seen.
But the point is that we have to make assumptions about the DUT. The better the assumptions the better the test. But how do we know how good our assumptions are? We don't. Hence we don't know how good the estimates (linear prediction whatever you want to call it) is. The techniques will always yield a result and virtually always that result will be better than had we done nothing, but we can never really know how accurate our predicted results actually are.
Of course we could make a prediction and then test that prediction - kind of an iterative adaptive approach, and Eric Benjamin of Dolby Labs has done some work in this area. Very interesting - holds promise -(an AES preprint from 2005, I believe).
But trust me, there is not likely to be something useful that has not been tried yet.
soongsc said:
But if the original source is MLS type sequence, editing out the tail means also editing out the low frequency decay characteristics.
It would be the same with cepstral editing. And remember that the reflections are basically an impulse chain that applies to all frequencies and all time greater than the delay from source to reflection point.
Look at this image.

This is the real cepstrum of a driver measured in a room with the time to the first room reflection just over 2 msec. So after 2 msec please identify what is room reflection and what is direct radiation. It doesn't matter how far out in time the plot is extended. The low frequency information is always contaminated by reflected sound. If the first reflection happens later, say at 6 msec, then the cepstrum and the original impulse would still be contaminated past 6 msec.
The only way to get the room reflections out of either is if you can define the impulse chain of the room. This would need to include all the time delays for 1st, 2nd,...,nth order reflections as well as the characteristic of each reflection (that is the frequency dependent attenuation). For example, a perfectly reflective surface would have a perfect, but delayed impulse. A carpeted floor would have the impulse of maybe a delayed low pass filter. Now assuming that the correct impulse chain can be identified then it could be removed from either the original impulse, or by computing the transfer function of the room in the frequency domain, and then the cepstrum of that, from the cepstrum of the original system. Of course, this will also be dependent on the room, the position of the source in the room and the position of the microphone, the off axis response of the driver.....
All I can say is don't tell me about it, show me! As they say, talk is cheap. I don't mean to sound arrogant or even nasty here, but this isn't a new subject. People have looked at it over the years and without much to show for it. I think there is plenty of incentive too. After all what is the other choice? A $250,000 (or more) anechoic room? Speculate all you like but if you want to convince me show me results.
john k... said:
People have looked at it over the years and without much to show for it.
John - this is quite true, but I do think that some of the implimentations work quite well. Praxis, as I stated, does a very good job.
The one who shows it in a product will be leading the technology.john k... said:
It would be the same with cepstral editing. And remember that the reflections are basically an impulse chain that applies to all frequencies and all time greater than the delay from source to reflection point.
Look at this image.
An externally hosted image should be here but it was not working when we last tested it.
This is the real cepstrum of a driver measured in a room with the time to the first room reflection just over 2 msec. So after 2 msec please identify what is room reflection and what is direct radiation. It doesn't matter how far out in time the plot is extended. The low frequency information is always contaminated by reflected sound. If the first reflection happens later, say at 6 msec, then the cepstrum and the original impulse would still be contaminated past 6 msec.
The only way to get the room reflections out of either is if you can define the impulse chain of the room. This would need to include all the time delays for 1st, 2nd,...,nth order reflections as well as the characteristic of each reflection (that is the frequency dependent attenuation). For example, a perfectly reflective surface would have a perfect, but delayed impulse. A carpeted floor would have the impulse of maybe a delayed low pass filter. Now assuming that the correct impulse chain can be identified then it could be removed from either the original impulse, or by computing the transfer function of the room in the frequency domain, and then the cepstrum of that, from the cepstrum of the original system. Of course, this will also be dependent on the room, the position of the source in the room and the position of the microphone, the off axis response of the driver.....
All I can say is don't tell me about it, show me! As they say, talk is cheap. I don't mean to sound arrogant or even nasty here, but this isn't a new subject. People have looked at it over the years and without much to show for it. I think there is plenty of incentive too. After all what is the other choice? A $250,000 (or more) anechoic room? Speculate all you like but if you want to convince me show me results.
As described somewhere in the SE manual, the Cepstral functionality is a work in progress.I think you have already addressed the key issues. Each time one changes measurement envoronment, it's best to redo a room signature capture. Once the method of room signature capture is derived, the other parts are pretty common to most software out there. The question really would be what signal is best to extract room signature?
Hi
Wouldn't a simple firecracker (or a pinned balloon ) at the position of the speaker do it for a good room capturing ?
Same can be done for RT60 measurement BTW.
How precise could such a speaker measurement become when done in domestic rooms ?
How many octaves down the usual 200-300 Hz ?
Greetings
Michael
Wouldn't a simple firecracker (or a pinned balloon ) at the position of the speaker do it for a good room capturing ?
Same can be done for RT60 measurement BTW.
How precise could such a speaker measurement become when done in domestic rooms ?
How many octaves down the usual 200-300 Hz ?
Greetings
Michael
DDF said:
Hi Michael: last wizzer I measured was 25 years ago, with swept sine, so, sorry, don't know. I strongly suspect it would be min phase as I don't see any physical mechanism in a wizzer which would add non-min phase delay.
Cheers,
Dave
Hi Dave,
The mechanism postulated is that a whizzer cone effectively acts as two different drivers. While each may be min phase, the system might be slightly nonmin phase.
I suppose it's a reasonalbe hypothesis. I've never tested any whizzer cones (not really high on my list) so I don't have any experimental data one way or the other.
Re: Re: Raven
I've sent an e-mail to Mr. Previ, we've made contact, and I'm awaiting a reply. He's probably talking to the technical staff as we speak. Additional contacts within 18Sound are welcome, though, and feel free to point them to the most recent posts on this thread.
The 8-inch spot looks good for the 8NMB420 - an additional 3 dB of efficiency would be welcome, along with retaining the neodymium magnet structure. Any data on impulse, CSD, and swept distortion would be most welcome.
The 12-inch spot looks good for the 12NDA520, with the 12ND710 as a second choice. The efficiency is good as it is, and like the 8NMB420, any data on impulse, CSD, and swept distortion is welcome.
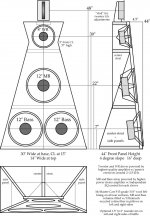
The 18-inch spot looks problematic for 18Sound drivers, due to the very large 1.5 kHz peaks. I know these are intended for professional subwoofer use, and pros use 24 dB/octave LR active crossovers and EQ. I won't be using such steep crossover, and want something more like the conventional woofer response of the RCF L18S800 or L18P300, or better yet, the response of the 18Sound 15NMB420. The rough response of 18-inch drivers is what makes me think of using a pair of 12-inch drivers side-by-side instead of single 18-inch driver.
The system will NOT be using 24 dB/octave LR crossovers, so smooth out-of-band performance is a requirement, along with low distortion in the desired frequency range, which is 60 Hz ~ 2 kHz for the 8-inch, 60 Hz ~ 300 Hz for the 12-inch, and 60 Hz ~ 150 Hz for the 15 or 18-inch.
The problem with the ICTA is the large inter-driver phase angle, as indirectly indicated by the magnitude graph - if my eyes don't deceive me, I'm guessing an inter-driver angle of about 120~135 degrees, right? As an old-time quadraphonics guy, phase angles this large are directly audible in their own right as a "phasey" sensation. although not everyone is sensitive to this. Inter-driver phase angles of 90 degrees or less seem more acceptable, but this depends on auditioner thresholds.
This is not the same as midrange lobing, which sounds quite different. I'm talking about a lack-of-cohesion sensation that is audible at any distance, and in fact gets worse as you approach the loudspeaker. To really create a sensation of a single driver, I've found I have to get the phase angles (between drivers) to 30~40 degrees or less. All subjective here, but that's how I hear things. I am probably more sensitive than most since I worked for many years on SQ and QS matrix decoders that intentionally created a 90-degree phase difference between front and rear speakers.
Now this phase-sensitivity between drivers mostly applies for equal magnitudes - reduce the magnitude of one driver by 3 dB or more, the sensitivity drops off pretty fast, and at 10 dB difference, the "acceptable" phase angles open up to 120~140 degrees. I've played with this a fair amount, listening to pink-noise and music at different distances, and have come up with a rough sort of "acceptable" phase angles between drivers.
Oddly enough, the MTM mounting scheme isn't necessarily an improvement - the "incoherent" sensation becomes less acceptable over a large area and with more drivers. That's what I especially dislike about large vertical WMTMW or line arrays - a strong sense of incoherence, of things not working together, and not like real musical instruments at all.
I agree completely about the need for precision in the mid/HF region. Absolutely. That's why the tweeter needs to be user-adjustable for listening height and distance. Even small adjustments produce large subjective changes in image focus, shape of soundstage, and realism in vocal quality. This requires a combination of acoustic measurement and subjective "trimming-in" - probably in the mm range for the final subjective adjustments.
I also agree about the concerns of the LF region - if these were conventional crossovers, switching from one driver to the next, stepping down from 8 to 12 to 18, then both the overall phase response and inter-driver phase angles become a major concern. If phase distortion is audible anywhere, it's audible in the 100 Hz to 1 kHz region.
But in my experience - which all I'm qualified to talk about - INTER-driver phase is much more audible than anything else, and it's not an artifact of polar patterns, but directly audible as "lack of coherence" and an artificial-sounding disjointed "multidriver system" sound. The opposite of a single-driver system sense of wholeness and coherence, in other words.
You walk towards the speaker system, and everything falls apart sonically - the illusion of a single source is destroyed. Nearly all physically large, complex, multiway high-end systems sound like this - the sound is incoherent and artificial, even if they "measure well" and fit the modern Toole criteria for "good sound". The reason for the incoherence comes down to large inter-driver phase angles, driver separation, and narrowband phase shifts close to the crossover region. None of this shows up in conventional FR measurements, impulse response, or the CSD.
That's a subtle reason I'm keeping the bass drivers all working together in the bass region, with only half-crossovers. I want to keep the inter-driver phase angles low and controlled - thus the choice of 1st-order or low-Q Bessel lowpass filtering for the lowpass functions for the 12 and 18-inch drivers. I don't want the angles to exceed 60 degrees, and preferably a lot less, so there's going to be some careful trimming of crossover behaviour in this region.
It's also why I don't want narrowband response deviations in the mutual-response region, since these cause sharp phase deviations as well, and will destroy the sense of coherence. This is part of the reason for my concern about the 18-inch driver - because of inter-driver phase concerns, a conventional sharp crossover is not an option. At higher frequencies, all of the drivers will collectively share an additional sharper lowpass filter at the tweeter crossover, to get rid of them once and for all above 2 kHz. But all of the drivers have to be reasonably well-behaved below that - which just may be asking too much of an 18-incher, but not a 15-incher.
The subjective goal is to have all three cone drivers sound like one driver, at any listening distance, including no more than few inches away from the front panel. My speakers have always done this, and the new system must do this as well. Nearly every other subjective goal is secondary.
Now will it succeed or not - well, I don't know yet. It is the direction I'm aiming for.
Jaco Pastorius said:
Hi Lynn I’m from Italy.
A friend of mine (another fanatic like diyAudio title says
He obviously has contacts with the company.
If you need information we will be proud to help you.
I’m a fanatic too, no business interest in my proposal!
Ciao
I've sent an e-mail to Mr. Previ, we've made contact, and I'm awaiting a reply. He's probably talking to the technical staff as we speak. Additional contacts within 18Sound are welcome, though, and feel free to point them to the most recent posts on this thread.
The 8-inch spot looks good for the 8NMB420 - an additional 3 dB of efficiency would be welcome, along with retaining the neodymium magnet structure. Any data on impulse, CSD, and swept distortion would be most welcome.
The 12-inch spot looks good for the 12NDA520, with the 12ND710 as a second choice. The efficiency is good as it is, and like the 8NMB420, any data on impulse, CSD, and swept distortion is welcome.
The 18-inch spot looks problematic for 18Sound drivers, due to the very large 1.5 kHz peaks. I know these are intended for professional subwoofer use, and pros use 24 dB/octave LR active crossovers and EQ. I won't be using such steep crossover, and want something more like the conventional woofer response of the RCF L18S800 or L18P300, or better yet, the response of the 18Sound 15NMB420. The rough response of 18-inch drivers is what makes me think of using a pair of 12-inch drivers side-by-side instead of single 18-inch driver.
The system will NOT be using 24 dB/octave LR crossovers, so smooth out-of-band performance is a requirement, along with low distortion in the desired frequency range, which is 60 Hz ~ 2 kHz for the 8-inch, 60 Hz ~ 300 Hz for the 12-inch, and 60 Hz ~ 150 Hz for the 15 or 18-inch.
john k... said:
Correct me if I misread this and your earlier post on aligning the drivers for first arrival but that sounds like what Spica did back in the late 70's. There are a couple of caveats here though. Considering the 2.5k crossover, the group delay of the 2nd order Bessel would be about 0.1 msec so the tweeter would have to be offset about 1.35" behind the acoustic center of the 8". No big deal. Then the 250 Hz crossover would have a GD of 1.0 msec and the 8"/tweeter combo would have to be offset 13.5" behind the 12" AC. Now there's a bit of a problem, no? Lastly, for the 100 Hz x-o the GD is 2.2 msec requiring an offset of almost 33" relative to the 12"/8"/tweeter combination. These offsets are in addition to the offsets of the driver ACs.
The Spica approach was fine for a small 2-way box speaker with crossover in the 2 to 3 k range, but using physical offset to time align 3 or 4 way systems isn't the way to go, IMO. Additionally, with a dipole system if you physically offset the drivers to align the 1st arrivals from the front you make a mess out of the rear response.
My feelinng is if you want time coherence in a dipole the driver AC's must be aligned and then time coherent crossover must be used as I am doing in my ICTA design development.
http://www.musicanddesign.com/icta_cross.html
The problem with the ICTA is the large inter-driver phase angle, as indirectly indicated by the magnitude graph - if my eyes don't deceive me, I'm guessing an inter-driver angle of about 120~135 degrees, right? As an old-time quadraphonics guy, phase angles this large are directly audible in their own right as a "phasey" sensation. although not everyone is sensitive to this. Inter-driver phase angles of 90 degrees or less seem more acceptable, but this depends on auditioner thresholds.
This is not the same as midrange lobing, which sounds quite different. I'm talking about a lack-of-cohesion sensation that is audible at any distance, and in fact gets worse as you approach the loudspeaker. To really create a sensation of a single driver, I've found I have to get the phase angles (between drivers) to 30~40 degrees or less. All subjective here, but that's how I hear things. I am probably more sensitive than most since I worked for many years on SQ and QS matrix decoders that intentionally created a 90-degree phase difference between front and rear speakers.
Now this phase-sensitivity between drivers mostly applies for equal magnitudes - reduce the magnitude of one driver by 3 dB or more, the sensitivity drops off pretty fast, and at 10 dB difference, the "acceptable" phase angles open up to 120~140 degrees. I've played with this a fair amount, listening to pink-noise and music at different distances, and have come up with a rough sort of "acceptable" phase angles between drivers.
Oddly enough, the MTM mounting scheme isn't necessarily an improvement - the "incoherent" sensation becomes less acceptable over a large area and with more drivers. That's what I especially dislike about large vertical WMTMW or line arrays - a strong sense of incoherence, of things not working together, and not like real musical instruments at all.
I agree completely about the need for precision in the mid/HF region. Absolutely. That's why the tweeter needs to be user-adjustable for listening height and distance. Even small adjustments produce large subjective changes in image focus, shape of soundstage, and realism in vocal quality. This requires a combination of acoustic measurement and subjective "trimming-in" - probably in the mm range for the final subjective adjustments.
I also agree about the concerns of the LF region - if these were conventional crossovers, switching from one driver to the next, stepping down from 8 to 12 to 18, then both the overall phase response and inter-driver phase angles become a major concern. If phase distortion is audible anywhere, it's audible in the 100 Hz to 1 kHz region.
But in my experience - which all I'm qualified to talk about - INTER-driver phase is much more audible than anything else, and it's not an artifact of polar patterns, but directly audible as "lack of coherence" and an artificial-sounding disjointed "multidriver system" sound. The opposite of a single-driver system sense of wholeness and coherence, in other words.
You walk towards the speaker system, and everything falls apart sonically - the illusion of a single source is destroyed. Nearly all physically large, complex, multiway high-end systems sound like this - the sound is incoherent and artificial, even if they "measure well" and fit the modern Toole criteria for "good sound". The reason for the incoherence comes down to large inter-driver phase angles, driver separation, and narrowband phase shifts close to the crossover region. None of this shows up in conventional FR measurements, impulse response, or the CSD.
That's a subtle reason I'm keeping the bass drivers all working together in the bass region, with only half-crossovers. I want to keep the inter-driver phase angles low and controlled - thus the choice of 1st-order or low-Q Bessel lowpass filtering for the lowpass functions for the 12 and 18-inch drivers. I don't want the angles to exceed 60 degrees, and preferably a lot less, so there's going to be some careful trimming of crossover behaviour in this region.
It's also why I don't want narrowband response deviations in the mutual-response region, since these cause sharp phase deviations as well, and will destroy the sense of coherence. This is part of the reason for my concern about the 18-inch driver - because of inter-driver phase concerns, a conventional sharp crossover is not an option. At higher frequencies, all of the drivers will collectively share an additional sharper lowpass filter at the tweeter crossover, to get rid of them once and for all above 2 kHz. But all of the drivers have to be reasonably well-behaved below that - which just may be asking too much of an 18-incher, but not a 15-incher.
The subjective goal is to have all three cone drivers sound like one driver, at any listening distance, including no more than few inches away from the front panel. My speakers have always done this, and the new system must do this as well. Nearly every other subjective goal is secondary.
Now will it succeed or not - well, I don't know yet. It is the direction I'm aiming for.
gedlee said:
I am surprised that you want us to take this discussion seriously when you won't tell us what you plan to do…..
I don’t want to give away the idea.
There’s also a thread in these boards, where an author is taking the same somewhat secretive approach with his HOM based loudspeaker system. So why be surprised when I feel less than inclined to give away all the cookies myself, without full discosure?
My concept is different than Benjamin’s work, if you’re meaning his technique of using low frequency pre-emphasis and de-emphasis pre and post FFT. Good idea, and it can be applied independently and in concert with what I’m investigating.
In any estimation technique, a reference is required. A suitable reference can be formed here with a couple additional measurements, some basic assumptions about the acoustical properties of the room, and by intelligently bounding the convergence algorithm, in parameters adapted, and boundaries for them, along with degrees of freedom alowed for adjustment.
I’ll also say it one more time, I heard the same nay-saying when developing an ecan verification methodology. It was successful enough that a group audio terminal company we were in talks with to partner, threatened to sue us as they believed we cracked their f/w code. All from measurements people said couldn’t be done.
I may have some spare time coming up to investigate this further (I’m not retired, I don’t work in audio any longer and I have 3 young children), but this is my last post describing details of the technique.
I’m hoping we can progress this to a more respectful tone. Skepticism is warranted, outright closed minded dismissal isn’t.
Without my oferring more detail, maybe there's not much else to discuss on this topic.
ucla88 said:
Hi Dave,
The mechanism postulated is that a whizzer cone effectively acts as two different drivers. While each may be min phase, the system might be slightly nonmin phase.
I suppose it's a reasonalbe hypothesis. I've never tested any whizzer cones (not really high on my list) so I don't have any experimental data one way or the other.
Hi Mark,
I was thinking along these lines: "is it possible that lower delay somewhere in the system could still result in the same frequency response, for a driver using a whizzer"? This after all defines min phase, in practical terms.
I can't see any physical way of achieving the same response with lower delay, but I guess just because I can't envision one, doesn't mean that one may not exist.
DDF said:
There’s also a thread in these boards, where an author is taking the same somewhat secretive approach with his HOM based loudspeaker system. So why be surprised when I feel less than inclined to give away all the cookies myself, without full discosure?
Without my oferring more detail, maybe there's not much else to discuss on this topic.
Your first point is incorrect in that there is nothing that I have not or will not discuss in regard to my work.
Your second point is quite correct.
gedlee said:
Your first point is incorrect in that there is nothing that I have not or will not discuss in regard to my work.
Your second point is quite correct.
Untrue in that you are rightly protecting your commercial rights and income in that thread, with-holding info.
I won't continue to tolerate this level of disrespect, so I'm out.
I also appologize to Lynn that I was part of his thread turning in a less than constructive direction.
soongsc said:
The one who shows it in a product will be leading the technology.
I think you have already addressed the key issues. Each time one changes measurement envoronment, it's best to redo a room signature capture. Once the method of room signature capture is derived, the other parts are pretty common to most software out there. The question really would be what signal is best to extract room signature?
This is what I was saying before. Tell me how you would "derive" the room signature, not how easy this would be once it has be derived.
I started on a paper about inmpulse editing when Bohdan and I were working on the cepstral editing back in May. If I have time I'll post the analysis of what I did on my web site. Part of the "work in progress" referred to in the SE manual.
Lynn,
Just make sure you send the woofers for EnABL also. Your concerns will be minimized and likely completely eliminated and the "merge" distance will be within 2 inches of the baffle plate and will not alter as you move about.
Bud
The subjective goal is to have all three cone drivers sound like one driver, at any listening distance, including no more than few inches away from the front panel. My speakers have always done this, and the new system must do this as well. Nearly every other subjective goal is secondary.
Just make sure you send the woofers for EnABL also. Your concerns will be minimized and likely completely eliminated and the "merge" distance will be within 2 inches of the baffle plate and will not alter as you move about.
Bud
Re: Re: Re: Raven
I understand you concern, but the ICTA is a little difference. Criticism of the ICTA approach not with standing let me return to the original question about offsets required for alignment of first arrival which you did not address. If you are only going to align the wide range and tweeter that is fine.
Now with the ICTA, as I said, things are a little different. Aside from the fact that you don't like the WMTMW format and the large inter-driver phase difference, let me say a few things about coherence. First, we discussed the MTM part and the difference between a dipole MTM and a conventional MTM system previously with regard to the ballooning of the (power) response around the dipole peak and the M-M cancellation as compensation. Second, in the ICTA we are talking about a 150 Hz crossover so the drivers are all acting like omnidirectional sources at that point. (I don’t intend on using this type of crossover for the MTM section.) Third, at 150 Hz the driver separation is such that the pair of mids and pair of woofers basically act as a single source centered on the baffle. What this means is that the amplitude and phase response of each pair is basically independent of position for fairly wide of axis angles, both vertically and horizontally. Sure if you get excessively close to the speaker this will not hold. It won't hold for any speaker. But at 1 M and beyond the proposed ICTA layout acts like two coincident point sources at the crossover frequency and the inter-driver phase difference, while exceeding 90 degrees, remains nearly constant over very wide vertical and horizontal angles. While I accept your comments on inter-driver phase differences, I believe that the issue is not so much about how big they are, but how they vary with position. The variation of the inter-driver phase difference will be a function only of driver separation and the position of the observation point (be it distance or vertical/horizontal displacement). That is, it's geometric and the same for all crossovers. The caveat is that some types of crossovers are more sensitive to variations in inter-driver phase variations. The LR type are the least as the response can never exceed 1.0, Butterworths are more sensitive and the response and reach +3dB when the inter-driver phase goes from 90 degrees to zero. With an inter driver phase difference of 120 there is a possibility of a +6db peak as the inter-drive phase goes to 0. And remember, were talking about dipoles here. So, in effect, between the front and rear sources we already have an “inter-driver phase difference” that varies for 0 to 180 degrees with frequency on axis.
In other words, (in my experience) inter-driver phase difference isn't the issue. Variation of inter-driver phase difference with position is.
We are obviously of different schools here, but like you I believe that the final judgement is in the listening. I suspect that both your system and mine will be speakers to reckon with. Of course, I don't antisapate driving mine with a SET amp. Tubes are fine, but I want to see a minimum of 100 watts. Like Patrick Henry said, "Give me muscle or give me deaf!"
Lynn Olson said:
The problem with the ICTA is [snip] .....
I understand you concern, but the ICTA is a little difference. Criticism of the ICTA approach not with standing let me return to the original question about offsets required for alignment of first arrival which you did not address. If you are only going to align the wide range and tweeter that is fine.
Now with the ICTA, as I said, things are a little different. Aside from the fact that you don't like the WMTMW format and the large inter-driver phase difference, let me say a few things about coherence. First, we discussed the MTM part and the difference between a dipole MTM and a conventional MTM system previously with regard to the ballooning of the (power) response around the dipole peak and the M-M cancellation as compensation. Second, in the ICTA we are talking about a 150 Hz crossover so the drivers are all acting like omnidirectional sources at that point. (I don’t intend on using this type of crossover for the MTM section.) Third, at 150 Hz the driver separation is such that the pair of mids and pair of woofers basically act as a single source centered on the baffle. What this means is that the amplitude and phase response of each pair is basically independent of position for fairly wide of axis angles, both vertically and horizontally. Sure if you get excessively close to the speaker this will not hold. It won't hold for any speaker. But at 1 M and beyond the proposed ICTA layout acts like two coincident point sources at the crossover frequency and the inter-driver phase difference, while exceeding 90 degrees, remains nearly constant over very wide vertical and horizontal angles. While I accept your comments on inter-driver phase differences, I believe that the issue is not so much about how big they are, but how they vary with position. The variation of the inter-driver phase difference will be a function only of driver separation and the position of the observation point (be it distance or vertical/horizontal displacement). That is, it's geometric and the same for all crossovers. The caveat is that some types of crossovers are more sensitive to variations in inter-driver phase variations. The LR type are the least as the response can never exceed 1.0, Butterworths are more sensitive and the response and reach +3dB when the inter-driver phase goes from 90 degrees to zero. With an inter driver phase difference of 120 there is a possibility of a +6db peak as the inter-drive phase goes to 0. And remember, were talking about dipoles here. So, in effect, between the front and rear sources we already have an “inter-driver phase difference” that varies for 0 to 180 degrees with frequency on axis.
In other words, (in my experience) inter-driver phase difference isn't the issue. Variation of inter-driver phase difference with position is.
We are obviously of different schools here, but like you I believe that the final judgement is in the listening. I suspect that both your system and mine will be speakers to reckon with. Of course, I don't antisapate driving mine with a SET amp. Tubes are fine, but I want to see a minimum of 100 watts. Like Patrick Henry said, "Give me muscle or give me deaf!"
Well, if I had the math skills, I could probably derive it. But I could explain the physical aspects and ideas step by step if someone is willing to see if it's mathematically possible.john k... said:
This is what I was saying before. Tell me how you would "derive" the room signature, not how easy this would be once it has be derived.
I started on a paper about inmpulse editing when Bohdan and I were working on the cepstral editing back in May. If I have time I'll post the analysis of what I did on my web site. Part of the "work in progress" referred to in the SE manual.
Sorry for a couple stupid questions from and amateur, but, Lynn could you clarify a couple things for me?
1) Precisely which did you find objectionable, phase difference between drivers, or phase *angle* difference between drivers?
2) Do you find this more objectionable than combing between large, widely spaced drivers with low XO slopes?
Thanks.
1) Precisely which did you find objectionable, phase difference between drivers, or phase *angle* difference between drivers?
2) Do you find this more objectionable than combing between large, widely spaced drivers with low XO slopes?
Thanks.
The Low
Lynn ... How low do you anticipate your system will go, and what would be realistic goals? Somewhere a loss of good hi fi quality must occur. I realize there are a lot of variables. I have a buddy trying to get into the 20's and still maintain hi fi. I barely get that low with my LLT (shelved, 300 L 18" monster) and it certainly is not stereo quality, only HT good. He claims that if you build to 20hz it will cover the whole bass spectrum well. I need a better/more realistic plan to present to him.
Recordings, either wax or those little 5" plastic things must run out of quality around a -3dB of 40hz if I guess right, excluding the newer rock which is not music, IMO. Most recording guys that I have talked to have said that, also.
Zene
Lynn ... How low do you anticipate your system will go, and what would be realistic goals? Somewhere a loss of good hi fi quality must occur. I realize there are a lot of variables. I have a buddy trying to get into the 20's and still maintain hi fi. I barely get that low with my LLT (shelved, 300 L 18" monster) and it certainly is not stereo quality, only HT good. He claims that if you build to 20hz it will cover the whole bass spectrum well. I need a better/more realistic plan to present to him.
Recordings, either wax or those little 5" plastic things must run out of quality around a -3dB of 40hz if I guess right, excluding the newer rock which is not music, IMO. Most recording guys that I have talked to have said that, also.
Zene
JohnK, thanks for your patience with the occasional cranky tone of my postings - mood swings as I chase out the last of health hassles, I guess.
For augerpro: there's no good standard terminology, partly because it's awkward to measure, too. The fullest description is inter-driver phase angle.
I find this meaningful because phase only exists in relation to other things - in usual audio terms, it is referred to the original electrical signal, and thus becomes the relation between the electrical and acoustical output. This isn't the only way phase can be used, though: it can describe the relationship between a pair of drivers, instead of between an electrical signal (the input) and the acoustical result sensed at the listening position (the output, with compensation made for transit time).
The standard polar diagrams depict the interference pattern between idealized single-point drivers at a single frequency. This can be steered by the phase angle between the two idealized sources - with the worst case, 180 degrees of phase rotation (not the same as reverse polarity) - resulting in a null aimed directly at the listener. This is obviously undesirable. It also has the practical result that nulls close to the listening position make the speaker very difficult to measure, with small changes in microphone position resulting in large changes in frequency response - leading to questions of which one is real. The answer is - none of them, and all of them. If a speaker has multiple personalities in a space only a few degrees apart, it has serious design problems.
This describes what goes on when drivers are fairly widely spaced acoustically - one or more wavelengths apart. Sound travels at 344 meters/sec, or looked at differently, 13,760 inches/sec. You can work out for yourself (in wavelengths) how far apart drivers are at the crossover frequency (as measured from the centerlines of the drivers).
JonhK and I are describing something rather different - what happens when drivers are quite close together acoustically (a fraction of a wavelength). I am asserting, based not on academic studies but personal experience, that even though large inter-driver phase angles do not appear on polar diagrams (due to proximity of drivers to each other), that it is audible nonetheless. However, all I am describing is my own subjective experiences, not what anyone else is hearing. I would guess audibility - or rather, tolerance - of inter-driver phase (with drivers that are acoustically close) may depend on the auditioner.
My experience with this is a legacy of working on the Shadow Vector SQ quadraphonic decoder - a system based on phase-shifting all-pass networks - and information gleaned from personally meeting Laurie Fincham (KEF) and the staff of the BBC Research Labs in the mid-Seventies. As a result, I've been careful to design loudspeakers that have relatively small and well-controlled inter-driver phase relationships.
My own personal criteria for a successful crossover is to turn the speaker on its side (on a sawhorse), drive it with pink-noise, and audition the drivers as I walk towards it, ending with my face a few inches away from the front baffle. If the crossover is successful, it always sounds like one phantom driver located between the two (or more) physical drivers, at any listening distance. If a crossover is only partly successful, it breaks apart into two (or more) sources at some critical distance (typically a metre or so). If it is a failure, the illusion of a single driver never happens at any distance, including listening distance.
What Laurie Fincham taught me was that the small deviations in frequency response near the crossover frequency also cause significant deviations in inter-driver phase, thus steering the polar pattern up and down at mid/high frequencies, and causing disagreeable "phasiness" at lower frequencies. Since drivers are mostly minimum-phase, correcting the frequency deviations near the crossover also conveniently corrects the inter-driver phase deviations as well. The result is an acoustical crossover that actually follows textbook behaviour, which is why KEF named it "Target Filter Function" design.
If this fine-grained compensation is not done, the chances of an acoustical crossover following textbook behaviour is close to zero - about as likely as standing under the window of a bank and hoping money will fall out. You can wait a long time before that happens.
This is NOT, repeat not, the same as "linear-phase" response. That is completely different, and refers to the relationship between the electrical input signal and time-compensated phase at the listening position. The awkward thing about "linear-phase" is the electrical signal is inaudible - that's why we have a loudspeaker in the first place! The question for linear-phase systems - assuming that is a valid goal - is sensitivity of the ear to phase distortion. The audio-engineering community is not in agreement on this one, although linear-phase proponents have claimed otherwise.
For Zene Gillette: It's an open question how effective the Gary Pimm filling technique will be - I think of it as being somewhere between a really short transmission line and a loudspeaker version of a cardioid microphone. It does go lower than a pure dipole, but the impossibility of assuring exactly 6 dB of rear-wave attenuation tells us it is really a quasi-cardioid, with a small rear (inverted-polarity) lobe at some frequencies, and a small (noninverted-polarity) lobe at others.
At a really wild guess, Pimm's method delivers somewhere between an octave and a half-octave more bass than a standard free-air dipole, with a somewhat different (less exuberant) spatial presentation. My WAG is somewhere between 50~80 Hz.
For augerpro: there's no good standard terminology, partly because it's awkward to measure, too. The fullest description is inter-driver phase angle.
I find this meaningful because phase only exists in relation to other things - in usual audio terms, it is referred to the original electrical signal, and thus becomes the relation between the electrical and acoustical output. This isn't the only way phase can be used, though: it can describe the relationship between a pair of drivers, instead of between an electrical signal (the input) and the acoustical result sensed at the listening position (the output, with compensation made for transit time).
The standard polar diagrams depict the interference pattern between idealized single-point drivers at a single frequency. This can be steered by the phase angle between the two idealized sources - with the worst case, 180 degrees of phase rotation (not the same as reverse polarity) - resulting in a null aimed directly at the listener. This is obviously undesirable. It also has the practical result that nulls close to the listening position make the speaker very difficult to measure, with small changes in microphone position resulting in large changes in frequency response - leading to questions of which one is real. The answer is - none of them, and all of them. If a speaker has multiple personalities in a space only a few degrees apart, it has serious design problems.
This describes what goes on when drivers are fairly widely spaced acoustically - one or more wavelengths apart. Sound travels at 344 meters/sec, or looked at differently, 13,760 inches/sec. You can work out for yourself (in wavelengths) how far apart drivers are at the crossover frequency (as measured from the centerlines of the drivers).
JonhK and I are describing something rather different - what happens when drivers are quite close together acoustically (a fraction of a wavelength). I am asserting, based not on academic studies but personal experience, that even though large inter-driver phase angles do not appear on polar diagrams (due to proximity of drivers to each other), that it is audible nonetheless. However, all I am describing is my own subjective experiences, not what anyone else is hearing. I would guess audibility - or rather, tolerance - of inter-driver phase (with drivers that are acoustically close) may depend on the auditioner.
My experience with this is a legacy of working on the Shadow Vector SQ quadraphonic decoder - a system based on phase-shifting all-pass networks - and information gleaned from personally meeting Laurie Fincham (KEF) and the staff of the BBC Research Labs in the mid-Seventies. As a result, I've been careful to design loudspeakers that have relatively small and well-controlled inter-driver phase relationships.
My own personal criteria for a successful crossover is to turn the speaker on its side (on a sawhorse), drive it with pink-noise, and audition the drivers as I walk towards it, ending with my face a few inches away from the front baffle. If the crossover is successful, it always sounds like one phantom driver located between the two (or more) physical drivers, at any listening distance. If a crossover is only partly successful, it breaks apart into two (or more) sources at some critical distance (typically a metre or so). If it is a failure, the illusion of a single driver never happens at any distance, including listening distance.
What Laurie Fincham taught me was that the small deviations in frequency response near the crossover frequency also cause significant deviations in inter-driver phase, thus steering the polar pattern up and down at mid/high frequencies, and causing disagreeable "phasiness" at lower frequencies. Since drivers are mostly minimum-phase, correcting the frequency deviations near the crossover also conveniently corrects the inter-driver phase deviations as well. The result is an acoustical crossover that actually follows textbook behaviour, which is why KEF named it "Target Filter Function" design.
If this fine-grained compensation is not done, the chances of an acoustical crossover following textbook behaviour is close to zero - about as likely as standing under the window of a bank and hoping money will fall out. You can wait a long time before that happens.
This is NOT, repeat not, the same as "linear-phase" response. That is completely different, and refers to the relationship between the electrical input signal and time-compensated phase at the listening position. The awkward thing about "linear-phase" is the electrical signal is inaudible - that's why we have a loudspeaker in the first place! The question for linear-phase systems - assuming that is a valid goal - is sensitivity of the ear to phase distortion. The audio-engineering community is not in agreement on this one, although linear-phase proponents have claimed otherwise.
For Zene Gillette: It's an open question how effective the Gary Pimm filling technique will be - I think of it as being somewhere between a really short transmission line and a loudspeaker version of a cardioid microphone. It does go lower than a pure dipole, but the impossibility of assuring exactly 6 dB of rear-wave attenuation tells us it is really a quasi-cardioid, with a small rear (inverted-polarity) lobe at some frequencies, and a small (noninverted-polarity) lobe at others.
At a really wild guess, Pimm's method delivers somewhere between an octave and a half-octave more bass than a standard free-air dipole, with a somewhat different (less exuberant) spatial presentation. My WAG is somewhere between 50~80 Hz.
Attachments
- Home
- Loudspeakers
- Multi-Way
- Beyond the Ariel