Hi Telstar,
Beyma 150 is an interesting beast! here's a plot of dipole 140-15D without acoustic lens. this will make a better comparison to the Beyma tpl150, as they're about the same vertical size. If you're not crossing low, and maybe you don't as you use 4-way, I don't think you'll loose much of the efficiency, if you don't mind the same beaming.
Nice plot, it is efficient, it suffers only in the 5k-9k range respect to the Beyma.
Do you have an inpulse response maybe?
Aaaah, MAD planar. Designed by my first mentor, Dragoslav Colich for HPV. What a jewel that is! It plays so effortlessly relaxed, smooth and soft but with a slam and kick I've never heard out of a planar!
Had a pair for a couple of months and living with those was sweet. Are they available now? They used to be $1k a pop...
Unfortunately nothing changed. and the single driver isnt that much more efficient than for instance the neo10 or neo8s.
I've been told great things about BG neo10. I think I'll get a pair.
You've got to try them. Then you wont like them like me
")
Speaking of Colich, the VMPS neo are a little more available and should still be better quality than the BG.
Yup, multiplying them little critters will be the center of the new OB speaker I'll do, following that narrow midrange - wide flush HF approach
I'm very curious to listen to them when they'll be ready (which is likely before mines): am i invited?
Have you ever looked at the Rubanoid?
It's veery similar...
??? the Rubanoid used a large bending wave transducer. What Aleksander showed above looks to be a ribbon with waveguide ( of sorts).
??? the Rubanoid used a large bending wave transducer. What Aleksander showed above looks to be a ribbon with waveguide ( of sorts).
Yes, that's true but the shape of the waveguide reminded me of the rubanoid.
That is not correct. To restate things a little differently, at low frequency where the response rolls off a 6dB/octave, that roll off is basically the same as a 1st order high pass filter with pole at the (theoretical) dipole peak. If the peak moved lower in frequency, the response off axis would be at a higher level that the on axis. It should be obvious that the effective separation between the front and rear sources must decrease because, obviously at 90 degrees the separation goes to zero or you would not have a 90 degree null. When we have a driver on a baffle the separation doesn't exactly follow the cos(theoretical) relationship, but the separation is a maximum on axis and becomes smaller as we move off axis.
Here you still view a driver like two separated point-sources. In my view the fundamental difference between a suspended driver and a point-source dipole is that with the point-source dipole the sound moves in a straight path in any direction. With a driver the sound will have to move around the surface of the driver and baffle. If the sound moves to the closer end (having to travel a shorter distance), the dipole distance will appear to be smaller and thus the dipole peak will shift up. Yet the sound travels to any direction around the baffle and is generated from any point on the membrane. The average distance traveled is in fact greater when you look off-axis than when you look on-axis. This should cause the dipole peak to move to a lower frequency.
What I see when measuring a driver, is that the dipole peak shifts to a lower frequency when you go off-axis, but also that the peak becomes wider and flatter. This is also what you would expect based on the theory I tried to describe above: some points on the driver membrane see a smaller dipole distance when you move off-axis, but most see a larger distance when you move off-axis and thus the average dipole distance is larger when you move off-axis.
You may or may not observe the movement of the peak higher in measurements because of other factors such as baffle size/shape, driver directionality, asymmetry between front and rear response, and the fact that the rear radiation that sums to the front acts as a distributed source around the baffle edge, but it is not uncommon to measure this effect.
Maybe you are right and the effect I measure can be attributed to other factors and I have indeed measured that some properties (some resonances) seem to move up in frequency when you move off-axis. However, in general I see that when you look on a more global scale, the dipole peak shifts to a lower frequency.
Here is a simulation of a 20 cm driver centered on a 40 cm square baffle for the on axis and 60 degree off axis response. Yes, it is only a simulation but it is reasonable representative of measured data.
The result of the simulation of course depends on the parameters you are working with. Could you post a measurement plot in which the effect becomes clear?
Below you see the 0 to 90 degrees measurements of a Visaton AL170 with as little baffle as possible.
An externally hosted image should be here but it was not working when we last tested it.
... To minimise the cross talk artefacts of stereo one needs to spatially homogenise the pinna cues and that is most easiest done by providing very wide dispersion at treble, almost omnidirectional above 3kHz.
Also in the midrange below 1kHz one needs to minimise room reflections to be able to provide stereo ITD cues and that is best done with very narrow dispersion.
Clearly it turns out the ideal loudspeaker directivity is not constant, not narrowing but widening!
Elias,
Doesn't widening dispersion with frequency mean rising power response at linear on-axis response or falling on-axis response at linear power response? What would be your strategy in this case?
Rudolf
That is not correct. ...A lot of the theory on your website is based on the premise that the dipole peak shifts to a higher frequency when you go off-axis, but I don't think this is correct.

Below you see the 0 to 90 degrees measurements of a Visaton AL170 with as little baffle as possible.
An externally hosted image should be here but it was not working when we last tested it.
For what it is worth
- 0-60deg in 10deg steps:
Neo3 in 38x38cm / 15" baffle:

Neo3 nude:

sadly did not capture polars with Neo3 in circular OB
Michael
Last edited:
First null higher
The first null is indeed moving higher as predicted off axis until the front/ rear balance falls apart near 90*.
Maybe you are right and the effect I measure can be attributed to other factors and I have indeed measured that some properties (some resonances) seem to move up in frequency when you move off-axis. However, in general I see that when you look on a more global scale, the dipole peak shifts to a lower frequency.
Below you see the 0 to 90 degrees measurements of a Visaton AL170 with as little baffle as possible.
An externally hosted image should be here but it was not working when we last tested it.
The first null is indeed moving higher as predicted off axis until the front/ rear balance falls apart near 90*.
The first null is indeed moving higher as predicted off axis until the front/ rear balance falls apart near 90*.
In my experience the dipole null is never very pronounced. This happens because the driver is getting large in comparison to the wavelength and because most drivers have already lost front-back symmetry long before that. Here the theoretical null coincides more or less with a dip in the drivers' own response, which makes it yet more questionable. By the way, the dips are only consistently moving up in frequency up to 45 degrees, not 75.
An externally hosted image should be here but it was not working when we last tested it.
However, you may have a point. I've looked at some more data. Sometimes there does seem to be a minor dip and in some cases it does seem to move up in frequency, but I can't tell for sure. The peaks in general do move down though.
I second that about Rudolf's work! The same goes to twest820!
I could, but you should know that a good cone driver does things better up to 1k5-2k than a ribbon ever could dream of. That is why electrostats and big planars sound wimpy with drums, percussion and piano.
In midrange, parachute effect, or large air loading, needs to be controlled with greater force per surface area than any ribbon, stat or planar can give.
Trust me, you're much better off with cones in midrange.
If you want to get truly remarkable results in midrange, use 3" FR driver in clusters of 2x4, 3x3 or 6 pieces in hexa and one in the middle for total of 7. Do not use line sources, they don't add together well, as top driver doesn't know what bottom driver does and vice versa, meaning that they don't share the load and sound equally wimpy just like one feeble 3" driver, only you can cross it a bit lower. Sharing the air loading is the key, a such 3" FR drivers clusters are the way to go. They get so much authority and slam that it;s not even funny. The main advantage to a comparable surface area of just one cone driver, is that 3" FR will have first cone breakup problems even as high as 11k, so you'll end up having a piston of a large area all the way up.
Choose only ones without Farraday rings and such tricks. Look for saturated pole plate and central pole piece. BTW, very few good driver use a Farraday ring as it wastes the signal current on showing you a nice impedance and they need 150 Watts to get dynamics and start sounding lively. Only a few bright examples exist, made by people that understand the drawback of it.
Hi Raal,
Thanks for contributing! Regarding suitable 3" FR drivers: Do you think a 3 x 3 or a 4 x 4 block of either the new TB W3-1878 (see attachment) or maybe the much cheaper Fountek FR88-EX would be a good choice for super mids?
Thanks!
Best regards
Peter
Attachments
With regard to Elias' and Raal's statements I must ask, does any instrument produces overtones in a manner not at all connected to its fundamental tone and would omnidirectional distribution of those overtones contribute to our stereo sensation ? It seems that this claim might originate from this page: Understanding Ambiophonics . Why stop at 1 kHz, fundamentals extend much higher.
/Erling
/Erling
Thanks for the compliment, and you should know that I respect RAAL products. But they just aren't my cup of tea. I'm not particularly interested in high aspect ratio radiators, be they tweeters or otherwise. I'm actually toying with the idea of placing a circular wave guide on the Neo3 for the next generation Note. We'll see. I'm not ducking your questions but I really don't know what optimum configuration would be. I know what I would like for the response. I guess if I were to try to design a true dipole tweeter is would be very similar to what Rudolf was proposing many posts ago, back to back domes which radiated as a true dipole but for which directionality took over before the on axis nulls appeared.
I also can not tell you how I would design a higher efficiency speaker. It is not something I would comment on off the cuff. But I can tell you I would not be using any type of gradient woofer system. If I wanted high efficiency across the spectrum I think I would pretty choose to suffer loss of accuracy the much go with a ported woofer. After that I just don't know.
Hi John,
Ahhh, the aspect ratio is killing me for years!!! I know exactly what you mean. Currently, I can't knock it down lower than 3.5 times. That's why I made it rising towards highs and then lensed the thing.
Anyways, along the course of playing with ribbons, I realized that this wide horizontal dispersion is an invaluable asset (to my taste in audio presentation), but I also understand why some don't consider it an asset. In any case, I think that such quality of converting the current to air movement, in HF, could not be achieved with technologies that allow lower aspect ratios. I also realized during playing with speakers that the "sound" of the drivers we use to build speakers is the most important thing and directivity is very secondary matter, and coincidentally, I prefer the presentation with wide flush HF.
That's why, when I get my hands on a good sounding midrange driver, I hold on to it and design around it, following my style in design choices. I actualy think, that for the same reason, you hold on dearly to the very best driver that 57 bucks can buy, because if the task is to present the people the solution that squeezes out the absolute maximum from a low budget, there is no way that it can be done any other way than the way you did it. If I'm right, kudos to you, my friend.
I very much like your answer to my question (thank you!) and I understand what you're saying, which reminds me...at a certain point, once you explored every path in a given field, a playful and relaxed state of mind takes over, that George Carrette, a software engineer, probably explained the best:
“First learn computer science and all the theory. Next develop a programming style. Then forget all that and just hack.”
Hilarious!!!
Let's keep on hacking the thing!
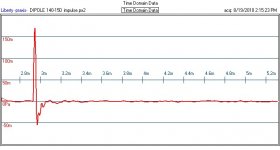
Hi, Telstar, sure you're invited! Impulse response attached.
Hi, Rudolf, I'm not Elias, but I wan't to give my 2 cents on this. Of course, we can't mess with a proper tone balance of direct sound (on axis), so my choice is rising power response at linear on-axis response (more precisely, wide flush tweeter like ribbon, should be attenuated a bit in the whole band, which for a few reasons, feels like linear and this is not just related to increased power response, but also microdynamics, etc.), but the main thing that I observed is that with increasing power response above 3k, is positive to the perception of presented music.
Most rooms, even the emptiest ones, have decreased RT60 times above 3-4k, so increasing energy off-axis up there, does not give disbalanced diffuse sound field in the room. Just the opposite, it equalizes it, which in turn, adds a constant RT60 time of the listening room to any recording we play. Now, that is nice! The highs get more sustain, you hear more of the natural concert hall decay and all of a sudden, everything clicks into place.
I strongly maintain that listening room must NOT mimic a concert hall acoustics with it's faster HF decay, but have linear RT60 up to min. 16k, and if it doesn't, then wide flush HF comes to the rescue. Even if the wide flush HF is used in linear RT60 rooms, no biggie, JUST sit closer and/or increase lateral reflections arrival time, and things are again much better than with equal or monotonically decreased directivity.
It all comes down to this:
We listen and judge by direct sound. All that happens off-axis is solvable, augmented, ruined, whatever, in short: processed and bounced back by room acoustics. Solve the acoustically small room for a given speaker and you've solved the sound. Solve the accoustically large room by a standard, and you've solved the sound for all speakers. Well, just one exception to this rule, you can't help front firing horns with anything. that solution belongs to the past and it is a compromise used to get efficiency. I hope we'll get over it, some time in 21st century.
Hi, pk, I'd go for Fountek. I haven't listened to it, just held it in my hand and examined it the best I could and it give me confidence. In any case, TB does not have saturated pole plate and you don't want unsaturated Iron in the vicinity of the voice coil.
Hi, keyser, I think your measurement shows (assuming that you measured in far-field keeping the mike at constant distance to the center of the cone) that, actually, nothing much happens with shifting. There's just some cancellation at 1k6 that makes it look like going down, but it's not. The first null is shifting upwards, but not nearly as much as two point model predicts, so if we take the first null as being closely tied at equal "distance" to the peak, the peak then must be going up, but really slowly. So, as in good old quantum physics saying, you showed that "a good practice, always ruins nice theories"! Theory in this case not being the accuracy of two-point-at-a-distance model, but it's applicability to single vibrating plane reality.
Don't know much 'bout 'custics, but it seems that, at least in case a vibrating plane is within the order of a magnitude of wavelenghts in air it has to wiggle, it becomes a spread parameter model that can't accurately be simplified with two dots and for that, congratulations! Good practice is what we need.
That reminds me, a new era is coming!
Many of you probably know this, but nowadays, there are simulation programs that can accurately predict this type of things, called "multi-physics" modeling software, like COMSOL, for example. The stuff works by setting the environment fluid (usually air or water) physical constants data, as well as to all parts of the model being examined. It can virtually run a jet engine or a speaker, because it works with basic material electrical, magnetic, chemical, thermodynamic, elastic, plastic, all kinds of known properties of any material used, and NOT with mathematical assumptions of how a certain behavior can be modeled. The difference being that you just have to make a 3D drawing of what you want, assign the materials and apply the excitation you want and the thing will "model" itself by interacting the fundamental material properties, just like the real thing does. It'll show you the fluid dynamics, vibration, heating, sound interference field, all that sh..! As much as we are certain of some physical property, taht much the workings of the contraption we drew, will be accurate. Pretty amazing! Too bad it's too darn expensive!

{kind=link}
{kind=link}
Hello,
Thx for the link Skorpion, but I have to emit a warning here, if not so any discussion with these data in mind will be useless (immediately you can try it on the (big) post just before, it gives an other lightning).
There is a typo mistake :
ILD cues work well only for signals with energy between 90 Hz and 1,000 Hz.
and :
Like ILD cues, ITD cues work really well only for signals with energy between 90 Hz 1,000 Hz .

For the established physiology, Raleigh has shown a long time ago that roughly ILD starts slowly above 500 Hz, and works well after 3000 Hz. ITD works for 90 to 1500 Hz. It's easy to understand why, and you know, evolution doesn't like redundancy...
Of course, it's much more complex. What can be demonstrated with stable tunes is not anymore a robust rule when we hear fast evolving signals (e.g. music...). There is a lock notion that also interfers with precedence.
We have also some confusion areas related to the size of the head where nothing works really ( around 2000 Hz, if then you think of the BBC dip or other Linkwitz works, maybe it's not a coïncidence).
Again, for the famous pinna clues , pure physiology considers that their main duty is detecting a sound source that is not in the sagittal plane (then coming from above, below, behind ?), or for detecting a moving source. It's only different transfert functions weighted between 2000 and 10000 Hz. To give useful data they need to be compared with the sagittal information, hence a bank of patterns. That's why instinctively we move our head. This has little to do with static music listening.
Example: When lying down, your favorite perfectly balanced sound will be perceived as dull. Something wrong with the tweeters?!!!
Nope, just raise up the head and it's normal again. The brain just tried to tell you "sound under your feet", but you have to check by different orientation of the sensors.
Pinna clues are part of the HRTF, but HRTF is much more, dont make the confusion.
All that I say here has to be considered after understanding that audio people use the discoveries of physio, but physio is not aimed to sound reproduction, and now audio people do their own research. That's why we can see here or here some apparent contradictions on a subject that is not well known yet.
So, no worries, work in progress
An useful link, easy to read, well done and in English.
To go deeper in the neural structure, this, but only for french readers that can surf from this point.
sorry, was a little bit OT, this thread is fantastic...
Thx for the link Skorpion, but I have to emit a warning here, if not so any discussion with these data in mind will be useless (immediately you can try it on the (big) post just before, it gives an other lightning).
There is a typo mistake :
ILD cues work well only for signals with energy between 90 Hz and 1,000 Hz.
and :
Like ILD cues, ITD cues work really well only for signals with energy between 90 Hz 1,000 Hz .
For the established physiology, Raleigh has shown a long time ago that roughly ILD starts slowly above 500 Hz, and works well after 3000 Hz. ITD works for 90 to 1500 Hz. It's easy to understand why, and you know, evolution doesn't like redundancy...
Of course, it's much more complex. What can be demonstrated with stable tunes is not anymore a robust rule when we hear fast evolving signals (e.g. music...). There is a lock notion that also interfers with precedence.
We have also some confusion areas related to the size of the head where nothing works really ( around 2000 Hz, if then you think of the BBC dip or other Linkwitz works, maybe it's not a coïncidence).
Again, for the famous pinna clues , pure physiology considers that their main duty is detecting a sound source that is not in the sagittal plane (then coming from above, below, behind ?), or for detecting a moving source. It's only different transfert functions weighted between 2000 and 10000 Hz. To give useful data they need to be compared with the sagittal information, hence a bank of patterns. That's why instinctively we move our head. This has little to do with static music listening.
Example: When lying down, your favorite perfectly balanced sound will be perceived as dull. Something wrong with the tweeters?
!!! Nope, just raise up the head and it's normal again. The brain just tried to tell you "sound under your feet", but you have to check by different orientation of the sensors.
Pinna clues are part of the HRTF, but HRTF is much more, dont make the confusion.
All that I say here has to be considered after understanding that audio people use the discoveries of physio, but physio is not aimed to sound reproduction, and now audio people do their own research. That's why we can see here or here some apparent contradictions on a subject that is not well known yet.
So, no worries, work in progress
An useful link, easy to read, well done and in English.
To go deeper in the neural structure, this, but only for french readers that can surf from this point.
sorry, was a little bit OT, this thread is fantastic...
Hi John,
Ahhh, the aspect ratio is killing me for years!!! I know exactly what you mean. Currently, I can't knock it down lower than 3.5 times. That's why I made it rising towards highs and then lensed the thing.
Anyways, along the course of playing with ribbons, I realized that this wide horizontal dispersion is an invaluable asset (to my taste in audio presentation), but I also understand why some don't consider it an asset. In any case, I think that such quality of converting the current to air movement, in HF, could not be achieved with technologies that allow lower aspect ratios. I also realized during playing with speakers that the "sound" of the drivers we use to build speakers is the most important thing and directivity is very secondary matter, and coincidentally, I prefer the presentation with wide flush HF.
That's why, when I get my hands on a good sounding midrange driver, I hold on to it and design around it, following my style in design choices. I actualy think, that for the same reason, you hold on dearly to the very best driver that 57 bucks can buy, because if the task is to present the people the solution that squeezes out the absolute maximum from a low budget, there is no way that it can be done any other way than the way you did it. If I'm right, kudos to you, my friend.
I very much like your answer to my question (thank you!) and I understand what you're saying, which reminds me...at a certain point, once you explored every path in a given field, a playful and relaxed state of mind takes over, that George Carrette, a software engineer, probably explained the best:
“First learn computer science and all the theory. Next develop a programming style. Then forget all that and just hack.”
Hilarious!!!
Let's keep on hacking the thing!
Hi, Telstar, sure you're invited! Impulse response attached.
Hi, Rudolf, I'm not Elias, but I wan't to give my 2 cents on this. Of course, we can't mess with a proper tone balance of direct sound (on axis), so my choice is rising power response at linear on-axis response (more precisely, wide flush tweeter like ribbon, should be attenuated a bit in the whole band, which for a few reasons, feels like linear and this is not just related to increased power response, but also microdynamics, etc.), but the main thing that I observed is that with increasing power response above 3k, is positive to the perception of presented music.
Most rooms, even the emptiest ones, have decreased RT60 times above 3-4k, so increasing energy off-axis up there, does not give disbalanced diffuse sound field in the room. Just the opposite, it equalizes it, which in turn, adds a constant RT60 time of the listening room to any recording we play. Now, that is nice! The highs get more sustain, you hear more of the natural concert hall decay and all of a sudden, everything clicks into place.
I strongly maintain that listening room must NOT mimic a concert hall acoustics with it's faster HF decay, but have linear RT60 up to min. 16k, and if it doesn't, then wide flush HF comes to the rescue. Even if the wide flush HF is used in linear RT60 rooms, no biggie, JUST sit closer and/or increase lateral reflections arrival time, and things are again much better than with equal or monotonically decreased directivity.
It all comes down to this:
We listen and judge by direct sound. All that happens off-axis is solvable, augmented, ruined, whatever, in short: processed and bounced back by room acoustics. Solve the acoustically small room for a given speaker and you've solved the sound. Solve the accoustically large room by a standard, and you've solved the sound for all speakers. Well, just one exception to this rule, you can't help front firing horns with anything. that solution belongs to the past and it is a compromise used to get efficiency. I hope we'll get over it, some time in 21st century.
Hi, pk, I'd go for Fountek. I haven't listened to it, just held it in my hand and examined it the best I could and it give me confidence. In any case, TB does not have saturated pole plate and you don't want unsaturated Iron in the vicinity of the voice coil.
Hi, keyser, I think your measurement shows (assuming that you measured in far-field keeping the mike at constant distance to the center of the cone) that, actually, nothing much happens with shifting. There's just some cancellation at 1k6 that makes it look like going down, but it's not. The first null is shifting upwards, but not nearly as much as two point model predicts, so if we take the first null as being closely tied at equal "distance" to the peak, the peak then must be going up, but really slowly. So, as in good old quantum physics saying, you showed that "a good practice, always ruins nice theories"! Theory in this case not being the accuracy of two-point-at-a-distance model, but it's applicability to single vibrating plane reality.
Don't know much 'bout 'custics, but it seems that, at least in case a vibrating plane is within the order of a magnitude of wavelenghts in air it has to wiggle, it becomes a spread parameter model that can't accurately be simplified with two dots and for that, congratulations! Good practice is what we need.
That reminds me, a new era is coming!
Many of you probably know this, but nowadays, there are simulation programs that can accurately predict this type of things, called "multi-physics" modeling software, like COMSOL, for example. The stuff works by setting the environment fluid (usually air or water) physical constants data, as well as to all parts of the model being examined. It can virtually run a jet engine or a speaker, because it works with basic material electrical, magnetic, chemical, thermodynamic, elastic, plastic, all kinds of known properties of any material used, and NOT with mathematical assumptions of how a certain behavior can be modeled. The difference being that you just have to make a 3D drawing of what you want, assign the materials and apply the excitation you want and the thing will "model" itself by interacting the fundamental material properties, just like the real thing does. It'll show you the fluid dynamics, vibration, heating, sound interference field, all that sh..! As much as we are certain of some physical property, taht much the workings of the contraption we drew, will be accurate. Pretty amazing! Too bad it's too darn expensive!
Hi Raal,
Thanks a lot for your reply!
Best regards
Peter
Fountek FR88-EX would be a good choice for super mids?
Brr... metal cone.
would thisbe an alternative (still in cheap mood to try it out):
Overview of C3N-III Drivers_HiVi,Inc
?
Brr... metal cone.
would thisbe an alternative (still in cheap mood to try it out):
Overview of C3N-III Drivers_HiVi,Inc
?
Hi Telstar,
well, this one it the best one yet out of the 3 models proposed, but not because its paper cone...
Here is the explanation of my general criteria for midrange drivers and comments on why:
1) Mechanical Q, as high as possible. My 3"ers have Qms= 9.8
If aluminum voice coil former is used, it's because it will act as eddy current brake and it will help low end control, which was the designer's intention. It works as a compressor, as the faster the jolt is, the better it brakes. If there's anything in this world that I don't want my mid to have, than this is it. I don't want my impulses being braked!
Some aluminum voice coil formers brake more, some less, but kapton doesn't brake at all.
2) Saturated front pole plate and eve more important, central pole piece.
In the first question, whether it was beter to use TB xxx or Fountek xxx, it seemed that Fountek had a better chance in having the saturated pole plate and central pole piece, as it's pole plate is thinner than fountek's. I was confident that it should be able to do it with this 50 mm Neo ring, as i know how I could utilize the ring of that size at 10mm pole plete, but I must apologize now, as I just read it's datasheet and it doesn't even come close to saturation. Both of them don't so I wouldn't use any. That's a pity, wasting so much Neo...
The problem there is when you need to run a very large batch of speakers, very quickly, to get the price down and make your buyers happy, you can't fiddle too much with tight voice coil gaps, especially if they're deep and have such a small diameter. Then you loosen up the tolerances, naturally. Slightly oval voice coils, then quick magnet assembly that doesn't allow you to position the plates too accurately, then fast machining that increases +/- dimensional errors, then very unhappy workforce that doesn't really care much about strict centering of the voice coil, as long as it's not rubbing, and instead of paying them more, you let it go as it's easier for them that way. and so on and so forth. Running a speaker factory is a multidisciplinary art of making people that you work with-happy, then you can make demands...
If I could sublime it: cheap speakers are not cheap because they utilize materials better, but because they don't! Contradiction? Think about it.
But, your proposal is very good as Hi-Vi has a large ferrite that should be able to saturate 20mm pole piece with just 3mm pole plate. Judging from BL, I guess it does, as I don't thing you can get more from small 20mm coil (short wire) in such a shallow gap (3mm). Of course, on can never be sure.
Related to the 2) above:
3) no Faraday ring(s)
Let impedance rise. Its her job when there's a coil of wire over the iron core. Don't force it out of it's job, as you'll just create waste. You'll waste signal energy into inducing current, thus heat, into the shorting ring.
One thing is for sure, that heat will not be transferred into force pushing the cone.
What I'll say now, may induce a debate, but I don't care, since speakers with Faraday rings sound boring anyway.
Yes, they reduce distortion. Why? Because they oppose modulating the magnet material by the voice coil signal current by running current induced in opposite direction and this will keep the net modulation low.
Hmmm, okay, but how the magnet material gets modulated in the first place? Well, because the central pole piece and voice coil around it look like an electro-magnet, lately addressed to as "field-coil" and the signal current tries to induce magnetic field that will eventually close it's path, passing through the magnet circuit, modulating the magnet. This creates 2nd harmonic generation and Alnico magnet types are the easiest to modulate (which is why some like them better), then ferrites, then NdFeB , which are the hardest to provoke(which is why some people that appreciate Alnico "character" don't think much of Neo novelties, as the have no "soul" to them, as I'm told).
Anyhoo, when you start passing magnetic field through the iron, it accepts it well, which is called permeability. At the beginning, all those little crystalline magnetic domains are starting to align themselves, waking up, and soon after, the permeability is at it highest as all the domains are awake and doing their aligning thing by command. If you continue increasing the field, domains will start falling into complete alignment with it and at a certain point, all these little compasses will be pointed north. That is the point of saturation! There is no more room to improve the direction of domains, and you can add field as much as you like, but nothing else will happen. They are at a standstill.
What is the first thing our voice coil current will do in it? It will induce the magnetic field in it and this field will either attract or oppose the static field of the magnet, and this will create force that wiggles this coil back and forth. Now, IF all the domains in the central pole piece are aligned completely by the overwhelming static field, they will all look at the same direction, completely ignoring the voice coil field. Since they aren't able to respond any more, they will effectively protect the magnet from being modulated by the signal current, thus being completely ignorant of what goes on in the coil, or better said, our music.
So, with properly designed magnetic circuit, our voice coil will be just like hanging in the air. it will not see the iron, as iron isn't responding to excitation, as far as magnetic field is concerned, when something isn't responding to it, it must be non-magnetic, thus not responsive to modulation. Also, with properly designed magnetic circuit, all magnets will "sound" the same, and in a good way, as modulating distortion will be gone.
Usually, people that have electromagnets in their speakers, report very obvious gains in sound quality, in detail and microdynamics. That's because when they increase the current feeding the electromagnet, they eventaully get to the point of saturation of all iron parts, so the voice coil doesn't have to waste energy in modulating it.
With the right choice of material, you can have that saturation as low as 0.8 Tesla, and save on magnet size, keep the T-S parameters in the right ballpark even for an 86dB/w speaker, but it'll sound like the best of the best compression drivers or Japanese FR's in microdynamics and detail department. I mention those two groups as they are the most common place to find that approach. The technique was a well kept secret in the industry and a few understood it, as most use Faraday rings as much as they can, and bragged about it. Latest (but not so new, it's been a while) and best solution comes from Billy Woodman of ATC fame. It's easy to do it with overhung voice coils and thin plates, but underhung voice coils with saturated and regulated gap come ONLY from him in his Super Linear (SL) series. And it doesn't use the ring but brought down the distortion by 15dB.
4) Suspension and spider.
You will notice with many speakers, inculding the small 3" FR's, that many will show little impedance peaks between 500 and 3000 Hz. Those are cone resonant modes and/or suspension resonance. The less the better. With good suspension material like Supronyl, made very thin and with a small roll, they will dissapear, or move above the intended bandwidth, if the cone stiffness allows for it.
Very soft spiders. I have Fs down to 67 Hz on 3" I use.
My general choice in speakers is towards very soft. I'll control the cone movement with other means, thank you very much, I don't need the coil pushing one way, the stiff suspension pulling the other way, effectively pinching the cone between opposing forces and making it endure unnecessary stress, reducing lifetime and provoke resonances.
5) Diaphragm material.
specifically in case of 3" Fr drivers, I prefer Aluminum cones with hard TiO2 or some other stiff coating, like Al2O3 (thick anodization).
The choice with larger driver is exclusively paper, or properly resined carbon fibre.
With small 3" cones, there is little much to resonate. Voice coil is 1" and that leaves only 3/4"" of the cone that's been edge-damped with surround. Breakup of a small stiff Al cone is very high, like 11k in case of 3"ers that I use. Paper is just fine, too. However, it doesn't allow me to approach the "piston movement" ideal in the whole passband, as it may start to break sooner. Since I can't trust it with humidity and temperature, i avoud it when i can, and so far, I managed to do it only in 3" FR case. Everything else, still seems to be better in paper.
So, I don't know are there any great 3" drivers out there to buy. I ordered mine to be made the way I like them and I wouldn't be able to give advice on every example, but I hope that with this explanations, anyone would know what I'd say about a specific driver.
Great summary indeed - but let me be a little be picky with the Qms (and possibly some other details later):
The "brake" introduced by eddy currents in the conducting voice coil formers certainly brings Qms down.
But actually there is not *that* much ill effect IMO out of this as its - more or less - only reducing efficiency slightly.
First order effects would not change output signal shape IMO, hence not that bad - if looking closer, the interaction between brake force and signal / excursion may not be exactly linear, causing some distortion though...
More ill effects burried in the Qms spec IMO are brake effects that are "non velocity dependent" (friction in surround and spider )
Michael
The "brake" introduced by eddy currents in the conducting voice coil formers certainly brings Qms down.
But actually there is not *that* much ill effect IMO out of this as its - more or less - only reducing efficiency slightly.
First order effects would not change output signal shape IMO, hence not that bad - if looking closer, the interaction between brake force and signal / excursion may not be exactly linear, causing some distortion though...
More ill effects burried in the Qms spec IMO are brake effects that are "non velocity dependent" (friction in surround and spider )
Michael
Hi Michael, thanks.
This braking is nonlinear because the the voice coil former ends just below the winding, but extends to the cone above, working in assymetrical stray flux that it picks up, but that's not what I want to talk about.
The main thing is that it depends on the velocity. Highest speaker velocity is at resonant frequency and it's absolute value at a given voltage depends on Qts.
So, it is working better as it approaches resonance.
On 3k, where the cone velocity is very low, it will not do much.
If we look at the single tone at 3k, nothing really happens to it and it's fine.
But let's take a 300 Hz as carrier and 3k riding on top of it.
In highest velocity part of the 300Hz carrier, passing zero, and for example traveling to positive direction, braking will be very good and when 3k sine is superimposed on this, it also will be under braking, but more in the positive direction. When the sine wave approaches peak, the 300Hz velocity will drop to 0, no braking there, and 3k will be freed of influence. When 300Hz strats going back to negative direction, things repeat.
It actually will change the shape and generate, IMD and harmonics of 3k, mixing them with IMD side products, creating more IMD...
Making a good speaker is all about multitone measurement methods.
BTW, speaking of velocity and direction, Doppler distortion is a bogus story altogether and it doesn't exist in speakers in any, even remotely significant way.
I deliberately didn't mention friction, as this thread is already hijacked enough and I didn't want to expand the story too much.
You are right, it is very dangerous. However, it is amplitude dependent in a complex way.
1) Once the cone gets going, it expands the spider and surround, and textile and lossy rubber have increased friction with higher tension.
2) Friction needs a minimum amount of force, or signal power, to overcome it and start the movement of the cone after wasting the signal power on creating heat. It actually eats up small signal, loosing detail and natural sustain.
This is why many speakers can't give much detail when listening softly. You gotta crank it up to get it out, and not just because of friction, but also because of too big Faraday ring, long story again...
Also, for a given listening sound pressure level, with larger midrange speakers, aside from having lower THD and motor nonliearity related IMD, larger speakers will move slower, having less problems with velocity and tension related distortion. That's why the bigger (or more) is better, provided that Qms per used speaker is high.
If we multiply the speakers, we decrease velocity and we don't want to fall into too low velocities where friction takes over.
Luckily, Qms is a very good showcase of frictional components and the higher it is, the better. Speaker should be mostly controlled wit amplifier, not conductive voice coil formers and manufacturers should stop this practice.
They mostly use it for better cooling of the voice coil wire, braking is just an added "bonus". Per Skaaning can give you Qms of almost 20 on an 8" speaker
This braking is nonlinear because the the voice coil former ends just below the winding, but extends to the cone above, working in assymetrical stray flux that it picks up, but that's not what I want to talk about.
The main thing is that it depends on the velocity. Highest speaker velocity is at resonant frequency and it's absolute value at a given voltage depends on Qts.
So, it is working better as it approaches resonance.
On 3k, where the cone velocity is very low, it will not do much.
If we look at the single tone at 3k, nothing really happens to it and it's fine.
But let's take a 300 Hz as carrier and 3k riding on top of it.
In highest velocity part of the 300Hz carrier, passing zero, and for example traveling to positive direction, braking will be very good and when 3k sine is superimposed on this, it also will be under braking, but more in the positive direction. When the sine wave approaches peak, the 300Hz velocity will drop to 0, no braking there, and 3k will be freed of influence. When 300Hz strats going back to negative direction, things repeat.
It actually will change the shape and generate, IMD and harmonics of 3k, mixing them with IMD side products, creating more IMD...
Making a good speaker is all about multitone measurement methods.
BTW, speaking of velocity and direction, Doppler distortion is a bogus story altogether and it doesn't exist in speakers in any, even remotely significant way.
I deliberately didn't mention friction, as this thread is already hijacked enough and I didn't want to expand the story too much.
You are right, it is very dangerous. However, it is amplitude dependent in a complex way.
1) Once the cone gets going, it expands the spider and surround, and textile and lossy rubber have increased friction with higher tension.
2) Friction needs a minimum amount of force, or signal power, to overcome it and start the movement of the cone after wasting the signal power on creating heat. It actually eats up small signal, loosing detail and natural sustain.
This is why many speakers can't give much detail when listening softly. You gotta crank it up to get it out, and not just because of friction, but also because of too big Faraday ring, long story again...
Also, for a given listening sound pressure level, with larger midrange speakers, aside from having lower THD and motor nonliearity related IMD, larger speakers will move slower, having less problems with velocity and tension related distortion. That's why the bigger (or more) is better, provided that Qms per used speaker is high.
If we multiply the speakers, we decrease velocity and we don't want to fall into too low velocities where friction takes over.
Luckily, Qms is a very good showcase of frictional components and the higher it is, the better. Speaker should be mostly controlled wit amplifier, not conductive voice coil formers and manufacturers should stop this practice.
They mostly use it for better cooling of the voice coil wire, braking is just an added "bonus". Per Skaaning can give you Qms of almost 20 on an 8" speaker
Last edited:
With regard to Elias' and Raal's statements I must ask, does any instrument produces overtones in a manner not at all connected to its fundamental tone and would omnidirectional distribution of those overtones contribute to our stereo sensation ? It seems that this claim might originate from this page: Understanding Ambiophonics . Why stop at 1 kHz, fundamentals extend much higher.
/Erling
Hi Skorpion, Radugazon!
Radugazon, thank you for this brief explanation ILD, ITD and PC.
Skorpion,
I like to approach simply to any problem. One thing is a constant, our hearing mechanism and what habits it picked up while we were growing up.
So, it is what it is and i can't change it.
The other thing is the speaker. I can change that, as obviously, my hearing mechanism isn't satisfied with it.
In short, omnidirectivity will improve the reality of your stereo image, but IMO, not because it will relate in some new way to ILD, ITD and PC, as all the same rules of stereo setup apply, but because of different and more natural relation to your room acoustics, which in turn, will help the processing algorithms of your brain, not directly with sensory gear firmware.
I think that there must be a sensory gear firmware first, and then the processing algorithms after. The algorithms gets learned as we grow up and we usually grow up in rooms.
To be more clear, the necessity for omnidirectivity lies in with how we process the relations of the source (speaker) and the environment.
This is the excerpt on my paper on our omni speakers, that will reflect my opinion on the subject:
>>>>>>>>>>>>>>>
The requirements:
In order to convey the lifelike presentation of an acoustical event, we need to have the following, properly presented to the listener:
• Depiction of the true scale of an instrument or orchestra and the space it occupies.
• “The angle of view” to a large orchestral body that we can encounter in a live event, keeping the right instrument sizes, but at a smaller “angle of view” because of distance to the orchestral body.
• Pitch-related and distance-related “proportions” of the tonal timbre.
• A multitude of tones, transients and sounds of similar nature must not interfere with each other.
• Directly presented low level detail that requires no “unveiling” concentration whatsoever on the listener's behalf, but with preserved dynamics - no compression of downward dynamics.
• Unlimited large signal dynamics...
Omnidirectivity:
Before we continue, a few words on omnidirectivity as a tool of presentation of the recorded audio events.
The first three of the above requirements rely heavily on speaker-room interaction. In our hearing mechanism, processing the reflections of the direct sound brings very important information to us, like a predator inside or outside the cave and how far, above or on the side to the entrance and so on. Now, in order for a reflection to be recognized as something that relates to the direct sound, and thus, giving us aforementioned info, it must have exactly the same “fingerprint” as a direct sound, or it will be mistaken for something that doesn't relate to the direct sound and it will be disregarded as an unimportant noise that carries no valid and conclusive information. The same “fingerprint”- meaning that the reflection's impulse and frequency response must be the same as in the direct sound, and altered only by the properties of the material of which it bounces off, only assigning it different timbre which depends on the reflective material absorption. The only thing that can be altered to a degree is the spectrum content but without introduced group delay for different frequencies. It is a similar thing with vision. We can recognize people by posture and walk, even seeing their shadows on the wall, but if the shadows are too stretched or skewed, it makes no useful information.
It all may seem too complicated to translate into engineering tasks, but the answer is pretty simple when you think of it. We need omnidirectivity. We need to send out the same information in all directions around the sound source and let our brain take in the info that will bounce off from the walls. Now, there are many seasoned loudspeaker engineers as well as audiophiles which claim that, at the best of their knowledge, introducing excessive number of reflections is derogative. And they are correct in their own right. That definitely applies as true for normal, directive speakers, where the sound emitted in all directions bares little resemblance to the on-axis forward sound, and right there lays the answer to why they are right, but only under that given circumstance of using a directive speaker. Usually, directive speakers require skillful room treatment to balance room acoustics. Paradoxically, omnidirectional speakers are much less fussy. That may sound like nonsense, but it isn't. What matters for an omnidirectional speaker is the symmetry of placement inside the room, with reduced attention to room acoustics and we will have the sharp focus of instrument placement inside the stereo picture and properly set “the angle of view”. The only difference in the pinpoint imaging of an omnidirectional speaker, as opposed to the directive one, is that it sets the true scale of the instruments and events, if those are recorded decently. Sharp but big, to put it simply. With a proper piano recording for example, you can “see” the keyboard stretching with every key sharply in it's place with a naturally large piano body occupying it's natural space. Drum-set is a drum-set and the skin is not the size of a peanut. The “hit” is the size of a peanut, but the presentation is the size of the drum...
What is interesting, as opposed to directive speakers, is that the room acoustic response can vary in much larger scale than it would be normally acceptable. That is because omnidirectivity will equally engage the room reverberation, which will, regardless of the placement of the absorptive and reflective surfaces relative to the speakers, give back the reverberative “output” which is broadly averaged. The directive speakers, and the more directive-the worse, will send out different frequencies in different directions and the room will be selectively engaged, reflecting back a different thing with every different speaker, depending on it's placement and aiming.
So, because we live, walk and talk in rooms our whole lives, our brains can easily relate to their acoustical fingerprint, especially to the ones where we lived for a while, and the difference between us talking and directive speakers playing is that our talk and noises that we make, engage the rooms almost equally in all directions. This is processed in our brain along with the reflections of our rooms added, every time the same way. It tells us that we are not artificial sound sources, the same way that, in the case of directive speaker playing, which don't engage the room equally, it tells us that the fingerprint of the reflection is not the same as the direct sound, rendering the conclusion that the sound source is of artificial nature, since it's fingerprint doesn't belong to our room, bringing down our music enjoyment and emotional engagement as we are subconsciously aware that something is skewed. We call all this “acoustics distortion”. It is not acceptable in the same way other various forms of distortion aren't.
Opponents say that “yeah, but I want to hear the acoustics of the recording room, not add my room to it”. We say, so use headphones then... Unfortunately, that doesn't work because of the way our brains are hard-wired. We must allow the room we are in to bounce back the time-coherent reflections. The only way is sending out to the room the same signal in all directions, i.e. omnidirectivity, or the room will bounce back the skewed shadow of a direct sound that will not just make our brain disregard the event as real, but also, struggle to disregard the reflections, as they will be considered to be background noise that carries no related info in order to enhance intelligibility of the event, leading to fatigue and finally, to loss of enjoyment of paying attention to that artificial event in the first place. The big old truth lies in the standards for the performance halls, which by default, have much longer reverberation time than any of our rooms and there will be no harm whatsoever in adding our decay time to the hall time, but only provided that we engage our rooms in the same way the orchestra engages the hall, hence, in all directions. If that sort of natural fingerprint of our familiar room is recognized, along with proper time and frequency fingerprint of incoming reflections, we'll have no trouble at all to relax and listen to any kind of recorded room acoustics (or none at all) and music, letting our brain be convinced that there may be a real event happening in there. Since that really isn't there, after all, we will know it, but the convincing presentation will be far more enjoyable, as we will definitely feel how excited our sub-consciousness is becoming by listening to it and having no objections to the matter at hand.
Our experiences with Eternity and other omnidirective speakers, one of them being a true masterpiece of electroacoustics as a science and art, we can say that omnidirectivity opponents may have listened to omni speakers but not the right ones and we can definitely state that omnidirectivity, as a principle, is superior and that only the specific executions may be deeply flawed. In short, omni-opponents have listened to the wrong speakers in the wrong set-up and judged accordingly. Omnidirectivity as a principle of presenting the recorded music is far superior to anything else, if executed with properly designed set of loudspeakers in accordance to the specifics of the principle.
>>>>>>>>>>>>>>>
- Home
- Loudspeakers
- Multi-Way
- On the directivity of dipole tweeters