@Greg Erskine
I set one up for a friend about six years ago and it still is humming along.
FreeNAS uses ZFS RAID and does software RAID, therefore does not need a controller.I have also had a RAID disk controller failure taking out both disks.
I set one up for a friend about six years ago and it still is humming along.
thank you! I wasn't aware of this silent data corruption issue. Seems to be I need to rethink my simple backup strategies.The bottom line is that file corruption on disk can occur. When it does, there's nothing to tell you that it's happened. And it can't be avoided. [Happily, it's not too common.] If you can't find a way to verify that your master files are OK, you will over-write your good copies with corrupted ones, as I did.
Backup isn't enough. Only verify-followed-by-backup will keep your files as safe as they can be.
My experience was similar. There were no signs of any problems - I had not attempted to play the corrupted files. What first tipped me off was running audio analysis of many 100s of files.*. Some would hang up and either take a very long time to analyze or never finish. Attempting to play those files would result in glitches and artifacts. That's when I noticed the drive could be slow to mount, and so I ran Seagate tools on it. The tools returned errors.
*JRiver Media Center will scan files to calculate average volume and BPM allowing volume leveling. Since there is now a new standard for this, I decided to re-analyze the entire library.
*JRiver Media Center will scan files to calculate average volume and BPM allowing volume leveling. Since there is now a new standard for this, I decided to re-analyze the entire library.
Although Hard Disk backup is important, it has it's issues (as anyone reading this thread is aware). One solution is to backup to non-magnetic media. This is a tried-and-true method that goes back to the earliest days of computing. The media and methods have changed, but the basic principles remain.
Today, you can use Blu-Ray discs which can store 25, 50, 100 and 128 GB per disk, depending on the writer and the media you choose. They are reasonably reliable storage media. Although there is a re-writable Blu-Ray format, for secure backup you probably want write-once media.
With regard to Hard Drive reliability, a longstanding maxim among IT pros is "it's not a matter of *if* a Hard Drive will fail, it's a matter of *when* a Hard Drive will fail."
If you look at the data collected by large users of storage, which is often published and is freely available (Google pioneered the use of consumer-grade Hard Drives over Enterprise grade, which are built to a higher standard but cost many times more $$ per GB) you see that infant failure is an issue (just like with semiconductors) and a small but significant number fail within 6 months. The failure rate then drops, before it increases significantly at about 4 years and continues to accelerate after that.
With modern computing platforms being so capable versus most users' needs, people are keeping their hardware longer and longer every year. 20 years ago the replacement practices of users was every 3.5 years for WindowsOS machines. Today we see people keeping Windows desktops for 6, 7 and more years. Hard Drive failure rates haven't changed, however. What has changed is people are using the systems past the point where failure rates for the OEM-installed drives increase significantly.
I mark my HDDs with a Sharpie indicating the date of installation, and replace them at 4 years, even if they appear to be working fine. Those replaced drives also serve as a form of backup should they be required (it's usually not worth selling them, as the capacity will be un-competively small by the time four years rolls around, so for the $40 or so you can get for them, they offer more value to you as a backup repository).
They may not be reliable if and when you need them, but they may be just fine at the same time. If you lose data, you are thrilled to find a working backup, regardless of the source.
Today, you can use Blu-Ray discs which can store 25, 50, 100 and 128 GB per disk, depending on the writer and the media you choose. They are reasonably reliable storage media. Although there is a re-writable Blu-Ray format, for secure backup you probably want write-once media.
With regard to Hard Drive reliability, a longstanding maxim among IT pros is "it's not a matter of *if* a Hard Drive will fail, it's a matter of *when* a Hard Drive will fail."
If you look at the data collected by large users of storage, which is often published and is freely available (Google pioneered the use of consumer-grade Hard Drives over Enterprise grade, which are built to a higher standard but cost many times more $$ per GB) you see that infant failure is an issue (just like with semiconductors) and a small but significant number fail within 6 months. The failure rate then drops, before it increases significantly at about 4 years and continues to accelerate after that.
With modern computing platforms being so capable versus most users' needs, people are keeping their hardware longer and longer every year. 20 years ago the replacement practices of users was every 3.5 years for WindowsOS machines. Today we see people keeping Windows desktops for 6, 7 and more years. Hard Drive failure rates haven't changed, however. What has changed is people are using the systems past the point where failure rates for the OEM-installed drives increase significantly.
I mark my HDDs with a Sharpie indicating the date of installation, and replace them at 4 years, even if they appear to be working fine. Those replaced drives also serve as a form of backup should they be required (it's usually not worth selling them, as the capacity will be un-competively small by the time four years rolls around, so for the $40 or so you can get for them, they offer more value to you as a backup repository).
They may not be reliable if and when you need them, but they may be just fine at the same time. If you lose data, you are thrilled to find a working backup, regardless of the source.
Last edited:
We get around hard disk reliability problems by keeping multiple copies on multiple drives. All three copies of my music collection (one master and two backups) could become corrupt - or just plain be lost if the disk dies - but it's pretty unlikely. I lost one drive a while ago, but was able to replace it and restore the data from my other drives. So that bit worked, at least. 😉
Bit rot can occur on any disk, that is, the magnetic bit can change. ZFS deals with this by regular scrubs to correct any, if ECC RAM is used. It will also alert the user if any corruption is detected.
Several years ago, the "store" drive on my Solaris mail server died. My automatic backup hadn't actually run for months. I was able to pay to have the data recovered to a new drive, cost me $1200. I now run ZFS mirrors on everything.......
I generally run two separate backups - one short cycle, one longer cycle. For example a daily backup then a weekly or fortnightly. That way I have a period between backups to identify any issues and can revert to the long term backup if necessary and only lose a small percentage.
I avoid long term backups on USB sticks as flash memory does degrade with time and I have had multiple sticks fail without warning.
The other strategy I use for music / video is one-way backup. That is, I only send new files and don't overwrite. Music and video files rarely change so no point writing the files over and over again when a simple presence check will do.
I avoid long term backups on USB sticks as flash memory does degrade with time and I have had multiple sticks fail without warning.
The other strategy I use for music / video is one-way backup. That is, I only send new files and don't overwrite. Music and video files rarely change so no point writing the files over and over again when a simple presence check will do.
Music files mostly are read-only ,but adding a read-only flag in file properties box is not enough, for less corruption chance its good idea to make file system read-only , i mean a music library partition on hdd .In linux thats should be easy thing , and if you want make any changes ,or add new files , you need to make it read write temporary ( remount --rw option). I've had file corruption issues earlier , and there are few dependencies ,which i have noticed .
First is computer overclocking and software bugs/crashes ,which cause random data overwriting and corruption ,at file and filesystem level. Also bad RAM memory cause this ,which can't work totally error free ,but system works fine ,you may even not notice about corruption.
Second - Sata cables can have bad contact ,had some experience with that type of error ,but they are recorded in hdd's internal SMART log.
Third - bad sectors , mostly for external usb drives ,but thats is mechanical defect 100% ,so if drive will be inside DESKTOP pc ,i think less chance to introduce bad sectors .
Fourth - media chosen for backup ,reliability and data retention. CD and dvd's are not reliable , i had earlier made some backups on these ,and what do you think - after few years a recording layer gets unreadable ,discs were stored in their orginal boxes .So optical media with its advertised long time data retention is not true sadly .
Flash drives would offer good speed and possibly data retention ,but if controller stops working ,they will be useless ,and cosmic price for bigger sizes ,suitable for backup.
So only read-only media ,like protected from writing hdd , i see as solution. Raid can't help if one of disks array gets damaged somehow.
About filesystems and checksums - i have a new idea . Lets say ,you install filesystem encryption ,which automatically decodes files on the fly ,when you read them ,and of course ,checks for proper CRC ,otherwise file will not be decoded and filesystem reports read error ,so you will know something happened with that file .
First is computer overclocking and software bugs/crashes ,which cause random data overwriting and corruption ,at file and filesystem level. Also bad RAM memory cause this ,which can't work totally error free ,but system works fine ,you may even not notice about corruption.
Second - Sata cables can have bad contact ,had some experience with that type of error ,but they are recorded in hdd's internal SMART log.
Third - bad sectors , mostly for external usb drives ,but thats is mechanical defect 100% ,so if drive will be inside DESKTOP pc ,i think less chance to introduce bad sectors .
Fourth - media chosen for backup ,reliability and data retention. CD and dvd's are not reliable , i had earlier made some backups on these ,and what do you think - after few years a recording layer gets unreadable ,discs were stored in their orginal boxes .So optical media with its advertised long time data retention is not true sadly .
Flash drives would offer good speed and possibly data retention ,but if controller stops working ,they will be useless ,and cosmic price for bigger sizes ,suitable for backup.
So only read-only media ,like protected from writing hdd , i see as solution. Raid can't help if one of disks array gets damaged somehow.
About filesystems and checksums - i have a new idea . Lets say ,you install filesystem encryption ,which automatically decodes files on the fly ,when you read them ,and of course ,checks for proper CRC ,otherwise file will not be decoded and filesystem reports read error ,so you will know something happened with that file .
"The authors of a 2010 study that examined the ability of file systems to detect and prevent data corruption, with particular focus on ZFS, observed that ZFS itself is effective in detecting and correcting data errors on storage devices, but that it assumes data in RAM is "safe", and not prone to error. The study comments that "a single bit flip in memory causes a small but non-negligible percentage of runs to experience a failure", with the probability of committing bad data to disk varying from 0% to 3.6% (according to the workload)," and that when ZFS caches pages or stores copies of metadata in RAM, or holds data in its "dirty" cache for writing to disk, no test is made whether the checksums still match the data at the point of use." - Wikipedia, of ZFS.
I don't think there's a perfect system out there, but it does seem that, with care and a little bit of effort, we can be as sure as we can be....
I don't think there's a perfect system out there, but it does seem that, with care and a little bit of effort, we can be as sure as we can be....
Verify-before-backup! 🙂
How do you keep your music files safe?
You guys are forgetting a valuable backup strategy. I share all my music with my friends (by giving them external hard drives). They do the same and it's free off-site backups. 😀
Then we have additional risk of corruption component - other users of the same content 😀 They can in example forget click "Safely remove hardware " icon before disconnecting your external drive and that can corrupt filesystem ,even no changes to disk were made ,simple because most os'es records file access dates ,but this can be disabled off course by experienced users.
Modern viruses / Ramsonware are becoming intelligent and look for network shares and corrupts them silently first before locking Your main computer.
Best strategy would be to scan all the files bit by bit with a CRC check utility and then compare afterwards every couple of days in sub-sequent scans. Of course this takes a lot of time...
Best strategy would be to scan all the files bit by bit with a CRC check utility and then compare afterwards every couple of days in sub-sequent scans. Of course this takes a lot of time...
Really? I hadn't heard that. 🙁Modern viruses / Ramsonware are becoming intelligent and look for network shares and corrupts them silently first before locking your main computer.
That's what I do ... but not as often as every couple of days. 😉 I use Microsoft's FCIV.exe utility (free download). It still takes a while to check 1.2 TBytes though! But at least now I will find out if my master files are corrupt, before I over-write my backup copies with them!Best strategy would be to scan all the files bit by bit with a CRC check utility and then compare afterwards every couple of days in sub-sequent scans. Of course this takes a lot of time...
I run backups like most here. I keep the last 3 full monthly backups
(large & slow), and the last 30 days of weekly/daily differential backups (small & fast). I have a set of drives on the PC as my dedicated backup store and I have a separate removable backup drive that gets updated every 2-3 months and sits in a bank safety deposit box. Local backups and rolling retention run automatically on a schedule so I don't have to remember to do it.
I have had bit rot and its only caught during access or backups as a file read error and its status is reported. Stuff like bit rot, operator error (accidental deletions/overwrites), sudden HD power on fail are restored with local backups. Other stuff like potential local backup failure, electrical surge, theft, fire etc are handled by offsite backup.
Backblaze Backblaze Drive Stats: 2018 Hard Drive Failure Rates publishes failure rates for drives in their storage pods. I suspect most consumer drives fail more often from frequent power cycling. There is also a way to ready the SMART data with freeware CrystalDisk CrystalDiskInfo – Crystal Dew World . I've placed a few reports from my drives that experienced problems with errors, excess delay or low transfer rates indicating something was wrong and I went looking. The OS did not report these errors (that I know if) and both drives have since been replaced, I only use them for temp storage when I need it.
(large & slow), and the last 30 days of weekly/daily differential backups (small & fast). I have a set of drives on the PC as my dedicated backup store and I have a separate removable backup drive that gets updated every 2-3 months and sits in a bank safety deposit box. Local backups and rolling retention run automatically on a schedule so I don't have to remember to do it.
I have had bit rot and its only caught during access or backups as a file read error and its status is reported. Stuff like bit rot, operator error (accidental deletions/overwrites), sudden HD power on fail are restored with local backups. Other stuff like potential local backup failure, electrical surge, theft, fire etc are handled by offsite backup.
Backblaze Backblaze Drive Stats: 2018 Hard Drive Failure Rates publishes failure rates for drives in their storage pods. I suspect most consumer drives fail more often from frequent power cycling. There is also a way to ready the SMART data with freeware CrystalDisk CrystalDiskInfo – Crystal Dew World . I've placed a few reports from my drives that experienced problems with errors, excess delay or low transfer rates indicating something was wrong and I went looking. The OS did not report these errors (that I know if) and both drives have since been replaced, I only use them for temp storage when I need it.
Attachments
Last edited:
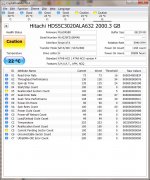
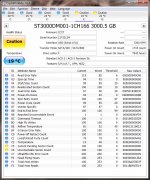
Very strange SMART data ,both drives looking very new , less than 100hrs operating time,but reallocated sectors problem !
Quality of desktop hdd's is getting worse and worse with time .That quality ,which was lets say 10 years ago ,manufacturers are keeping ,but at different price ,and naming that "business" segment or similar, like "WD RE" . About Hitachi hdd's i still can't say anything good ,how much i saw them ,all failed with bad sectors very frequently ,and that means you can purchase new drive and can't sleep well ,must wait for it to begin fail,can't be sure for your data safety. So where to backup is still interesting question .
Quality of desktop hdd's is getting worse and worse with time .That quality ,which was lets say 10 years ago ,manufacturers are keeping ,but at different price ,and naming that "business" segment or similar, like "WD RE" . About Hitachi hdd's i still can't say anything good ,how much i saw them ,all failed with bad sectors very frequently ,and that means you can purchase new drive and can't sleep well ,must wait for it to begin fail,can't be sure for your data safety. So where to backup is still interesting question .
Some of the CrystalDiskInfo columns are relative to 100% health and others are alarm thresholds and some contain raw data.
So the first drive actually has 30589 hrs (top right) or raw data (777D =30589). So this drive has been around for a while and is probably an end on life failure. The second drive only has 7643 hrs and is experiencing sector problems as well. They both pass
OS disk checks but IMO are now unreliable because I don't know if the problem is stable now or will increase. My past experience suggests this problem will only get worse.
P.S. I have also seen bit rot on CDs, DVDs, BluRay as well. Where about 2 per 100 discs have tracks or an entire disc that won't read on any player I have. Some fails are nearly 30yrs old but then others are less than 2yrs old.
So the first drive actually has 30589 hrs (top right) or raw data (777D =30589). So this drive has been around for a while and is probably an end on life failure. The second drive only has 7643 hrs and is experiencing sector problems as well. They both pass
OS disk checks but IMO are now unreliable because I don't know if the problem is stable now or will increase. My past experience suggests this problem will only get worse.
P.S. I have also seen bit rot on CDs, DVDs, BluRay as well. Where about 2 per 100 discs have tracks or an entire disc that won't read on any player I have. Some fails are nearly 30yrs old but then others are less than 2yrs old.
- Home
- Source & Line
- PC Based
- How to deal with music-file disk corruption?