I admit I'm fishing for good ideas.
I have some concerns about GNFB, particularly imaging and 'engagement', aspects of sound quality which are almost impossible to measure.
MiiB, you have a good idea here. How would you quantify the global v. nested levels?
Hugh
Have you looked into the work of Aubrey Sandman on feed forward systems - also his Class S using an auxiliary amplifier circuit to increase the apparent speaker load presented to the main amplifier.
A Darlington output pair has a THD % of 2.2 into a 10R load but less than .02% into 5k - these results at 20kHz and 5V rms. I understand the principle was noted by a manufacturer whom Sandman took to Court. The circuit was published in Wireless World in September 1982.
That was a long time ago - I don't know if there is or was any patent granted but the improvement would lessen the constraints as to the amount of negative feedback required and allow better stability margins.
This would seem a more fruitful approach than pushing stability margins to achieve distortion percentages at 20 kHz ten or more times lower than would be audible.
I've been harping for years that we really won't make progress (or dispense with threads like this one) until the industry places the human hearing/perceptual rules at the foundation of its goals. Right now they often get ignored- and its been that way for decades.
I agree. Psychoacoustics is an empirical science.
You commented about tubes. Many decades ago (1974 I think) I built a tube power amplifier out of some salvage parts. I had great transformers and some other components and bought a chassis that allowed me to place the tubes farther apart, which allowed me to use premium output tubes. The circuit topology was nothing special, but I used a transistorized capacitor multiplier power supply for the 12AX7s. The result was a very low noise amp; no audible hum or hiss into 100 dB+ speakers. I did not measure it but it was obviously way better than any other tube equipment I'd ever heard (which always had at least a little hum) and it clipped nice and soft. It sounded good even when driving more modern acoustic suspension speakers too. You had to try to make it produce objectionable distortion.
I wish I had it today. It was stolen in the early 80s.
Full time domain and frequency domain analyses both contain exactly the same information - Fourier guarantees that. However, they present that same information in very different ways so we are free to choose the representation which best suits our own limited ability to process information. In some cases, as you describe, a hybrid might be best such as a wavelet analysis.ilimzn said:For one thing, someone in another thread recently mentioned how crossover distortion was just another form of harmonic distortion. If I was in a cartoon, I'd have little question marks popping over my head at that point. For HD, if yoi nput teo sine signals, you get harmonics of both and the IM products in all combinations. Try this with say 200Hz and 2kHz at 1:5 ratio at a level safely below clipping of the amp and look at the spectrogram (a proper number of FFT points has to be chosen to get enough time resolution in the spectrogram) and you can clearly see how IMD varies drastically depending on the 2k sine part crossing zero or not as it rides on the much larger amplitude, generating THD and IMD chirps. A regular static THD and IMD analysis will completely miss that - you'll get a number, but not know why.
One thing you can be sure of: if you input 200Hz and 2kHz (poor choices, as one is a harmonic of the other) then all the output frequency components will be harmonics or IM products of these (plus mains IM etc.). Crossover distortion does not magically create a third form of distortion which is neither harmonics or IM - however much it might look like that to someone who is puzzled by Fourier.
I agree. Psychoacoustics is an empirical science.
You commented about tubes. Many decades ago (1974 I think) I built a tube power amplifier out of some salvage parts. I had great transformers and some other components and bought a chassis that allowed me to place the tubes farther apart, which allowed me to use premium output tubes. The circuit topology was nothing special, but I used a transistorized capacitor multiplier power supply for the 12AX7s. The result was a very low noise amp; no audible hum or hiss into 100 dB+ speakers. I did not measure it but it was obviously way better than any other tube equipment I'd ever heard (which always had at least a little hum) and it clipped nice and soft. It sounded good even when driving more modern acoustic suspension speakers too. You had to try to make it produce objectionable distortion.
I wish I had it today. It was stolen in the early 80s.
I have heard a number of tube amplifiers - transformer coupled - that dispense with global feedback. At the time I was a member of an Audio Group that met monthly in an evening to demonstrate recordings and equipment.
There are different ways to take a journey and enjoy the experience. Whenever there was a meeting where people stayed around to chat and the mood was positive I thought the night had been made a success due to the equipment. I observed that happening with these particular test subjects and remember this well more than 10 years later. I think there are psycho acoustic factors which influences human reactions to sounds and environments - in the hunter gatherer days no doubt this had much to do with survival.
What would sound better
1. A device using feedback going into non linear zone of operation?
2. A device not using feedback going into its non linear zone of operation ?
1. A device using feedback going into non linear zone of operation?
2. A device not using feedback going into its non linear zone of operation ?
False premise. All devices are always nonlinear. Most devices have some built-in feedback.
However, if the situation you describe were possible then 'nonlinear plus feedback' would be closer to the original signal than 'nonlinear without feedback'. Which would sound "better" depends on the personal taste and goals of the listener: sound reproduction or a pleasing sound production?
However, if the situation you describe were possible then 'nonlinear plus feedback' would be closer to the original signal than 'nonlinear without feedback'. Which would sound "better" depends on the personal taste and goals of the listener: sound reproduction or a pleasing sound production?
This is all good and well until you realise that time-invariant (analogue) devices such as speaker amplifiers and loudspeaker drivers can't produce 10% 2nd order harmonics without also producing 2nd order intermodulation distortion when there is more than 1 tone present. IMD of any order subjectively sounds terrible. The more instruments playing or the more complicated the chords from a single instrument, the more IMD products produced which will give a subjectively grating sound. This is why (imo) highly non-linear devices have no place in a sound reproduction system, only as an artistic tool for individual instruments.10% THD comprised purely of 2nd order distortion isn't all that objectionable either as far as things go. Sure you can hear it, but it wont make your ears melt off.
It is however possible to introduce harmonic distortion without intermodulation distortion by using digital processing. The result is quite natural, and nothing like what a high THD speaker or amplifier sounds like.
Last edited:
Full time domain and frequency domain analyses both contain exactly the same information - Fourier guarantees that. However, they present that same information in very different ways so we are free to choose the representation which best suits our own limited ability to process information. In some cases, as you describe, a hybrid might be best such as a wavelet analysis.
One thing you can be sure of: if you input 200Hz and 2kHz (poor choices, as one is a harmonic of the other) then all the output frequency components will be harmonics or IM products of these (plus mains IM etc.). Crossover distortion does not magically create a third form of distortion which is neither harmonics or IM - however much it might look like that to someone who is puzzled by Fourier.
Agreed completely. The point is actually more about how our tools present the results of measurements. Granted I did not chose a good enough example as you rightly point out (just look at the time I wrote the post to see why 😛 ), but suppose you input such a signal and then took a screenshot of your FFT analysis tool - and what it's doing (VERY simplified), is doing a series of FFT's on 2^n successive samples using a windowing function to handle the fact there may be 'missing samples' between the 2^n successive ones, and integrates the result using some sort of averaging or peak detect function. You get a screen with a number of HD and IMD peaks. You could get an almost exact same situation using different root causes which would sound rather differently. Of course, experience is needed - but also the ability to properly represent measurement data, and sometimes it's surprising that it's not a given even in some high-end analyzers.
Experience is needed even at a much lower level, in understanding how the equipment does what it does. An example: when choosing a single frequency to analyze, it helps if the period is a whole number of samples 😛 and even better if the highest harmonic you want to measure has a whole number of samples. I.e. at 48k sampling, don't measure with 1kHz, use 1.2kHz.
Last edited:
Feedback operates on the assumption that you have sufficient reserves and the foundation holds, otherwise....
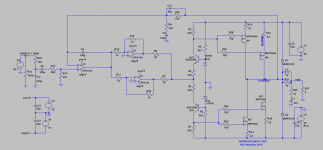
With feedback one can play around with circuits like these
Intriguing! But, ehh, don't you want to switch M3 and M4?
Jan
What would sound better
1. A device using feedback going into non linear zone of operation?
2. A device not using feedback going into its non linear zone of operation ?
1 has scope for hard non-linearity like clipping. As long as you avoid clipping, 1 is better. At clipping, 2 may be better.
Very, very general - depends on a host of other issues.
Jan
It is however possible to introduce harmonic distortion without intermodulation distortion by using digital processing. The result is quite natural, and nothing like what a high THD speaker or amplifier sounds like.
This might be harder to do than you think, decomposing a complex music waveform into individual frequencies would be complicated by the fact that multiple sampling frequencies would be needed. Unless your talking about synthesizing music.
Your problem is you believe it is a zero sum game. You think one topology is "superior" and "sounds better" in an absolute sense, for everyone.
So you have found your holy grail. Congrats.
This is an assumption of yours and is incorrect! Sheesh.
Stasis
And not to forget Nelson's Stasis.Have you looked into the work of Aubrey Sandman on feed forward systems - also his Class S using an auxiliary amplifier circuit to increase the apparent speaker load presented to the main amplifier.
No, the topology of the output section is paralleled pairs of common-source DMOS driven by the complementary common-base transistors.Intriguing! But, ehh, don't you want to switch M3 and M4?
Jan
I'd worry about the stability of the output devices' quiescent currents.
...also his Class S using an auxiliary amplifier circuit to increase the apparent speaker load presented to the main amplifier.
You could take a look at my patents #4,107,619 (1978) and #5,710,522
(1998), both of which fit that description also.
😎
I have heard a number of tube amplifiers - transformer coupled - that dispense with global feedback. At the time I was a member of an Audio Group that met monthly in an evening to demonstrate recordings and equipment.
This unit was nothing like that. It was a pentode ultralinear circuit with global feedback that included the transformer and was returned to the cathode of the input stage. Feedback compensation was empirically determined. It worked exactly like a modern amp and was fully compatible with modern hi fi equipment, including speakers. It was modern, clean and consistent, and wonderful.
patents #4,107,619 (1978)
😎
This is a great concept in practice, and addresses a significant source of nonlinearity that is often ignored by designers. Doug Self addresses it with his buffered Vas stage in his "blameless" amplifier, but your solution goes right to the source.
I prefer Sziklai topology in spite of the slight increase in complexity. It's worth it.
This unit was nothing like that. It was a pentode ultralinear circuit with global feedback that included the transformer and was returned to the cathode of the input stage. Feedback compensation was empirically determined. It worked exactly like a modern amp and was fully compatible with modern hi fi equipment, including speakers. It was modern, clean and consistent, and wonderful.
I've got one of those. Older than me. Must get it working again...
I've got one of those. Older than me. Must get it working again...
Ultralinear circuit is the best. With modern techniques you could build a truly superlative amplifier. The transformer is the fly in the ointment, but that can be solved $$$$$$$$$$.
McIntosh used to (still does?) make transformers in house. No expense was spared, and they had features like a separate winding for the feedback loop. They pulled out all the stops.
Just get out your wallet and join the club.
- Home
- Amplifiers
- Solid State
- Global Feedback - A huge benefit for audio