what special insight do you get into the sound quality of electronics/wire/whatever by peeking at the nameplate?
got a minor thrill, with this one, as this was the first time.
insight?
well ...
An externally hosted image should be here but it was not working when we last tested it.
Ken, what part of "The problem, to me, in double blind testing, even in my own environment, is that most differences do disappear" is unclear to you?
What exactly is leftover when you subtract "most differences" from all differences?
-
How about a sighted test with two pairs of expensive and non-expensive components--switch "nameplates" between one of each?
.
Last edited:
I wonder if all the talk of 'Listening Test' and DBTs is getting us confused to the purpose of doing the tests.
I am entirely unable to perform competitive listening, or 'decide the champion amplifier', -- listening only works if I'm relaxed enough to enjoy the Music as a pleasure.
It might take all evening to decide about some little change to a design, but that's OK, I listen critically only to improve what I do, not to claim my design surpasses someone else's.
As a designer, I am content with the process, and believe that my results move forward. Now & again, I get a second opinion to make sure my long term reference does not drift too far from natural sound.
But I understand why one would not wish to get involved in competitions of this kind.
I am entirely unable to perform competitive listening, or 'decide the champion amplifier', -- listening only works if I'm relaxed enough to enjoy the Music as a pleasure.
It might take all evening to decide about some little change to a design, but that's OK, I listen critically only to improve what I do, not to claim my design surpasses someone else's.
As a designer, I am content with the process, and believe that my results move forward. Now & again, I get a second opinion to make sure my long term reference does not drift too far from natural sound.
But I understand why one would not wish to get involved in competitions of this kind.
Double blind testing appears to set the listener into a different mode of listening than more open listening. I think this is a left brain-right brain switchover that has been shown to happen visually, in being not being able to draw pictures, by people not trained as artists, even when their mechanical skills are adequate. Training people to draw, means that their right brain has to be more utilized. I think it is the same in listening. Direct comparisons seem to obscure differences. Listening in a relaxed environment seems to bring out differences, that once noted, remain, even years later.
What exactly is leftover when you subtract "most differences" from all differences?
...
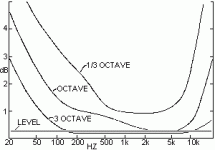
Clark's frequency response threshold curves?
clearly people can make relatively fine distinctions that are statistically significant in ABX tests - and the consequence is that anyone wanting to claim audible differences without matching to these levels is open to the obvious criticism that the level differences were the only "real" difference in a "relaxed" subjective test that didn't control for this
from: ABX Amplitude vs. Frequency Matching Criteria
Attachments
{kind=link}
Last edited:
What exactly is leftover when you subtract "most differences" from all differences?
People can hear all sorts of things in blind tests. Frequency response, phase, polarity, level compression, data compression, noise, crosstalk, distortion, overload, recovery time... for some reason, the bad vibes don't seem to inhibit those things. Hmmm.
I would rephrase your statement.
Only on very sensitive (and rare) loudspeakers, SET amps wouldn't distort on loud passages.
Furthermore, the extended details and microdynamics of SET amps are notable on almost any loudspeaker.
Josh, restatement or not, rare (your words) speakers are a minimum requirement to make a blind assesment of amplifier performance. My opinion remains that amplifier misbehavior and frequncy response deviation taint almost all casual "DBT's"
EDIT - Sorry Joshua my stepson is a Joshua G. and I am used to simply using Josh.
Last edited:
The problem, to me, in double blind testing, even in my own environment, is that most differences do disappear, YET they come back with normal listening.
That's about the best summary of several threads and 1000's of hours of people's time wasted that I have seen.
I'm glad that you like it, Scott. To me, it says that there is something wrong with double blind testing.
Except I'm not aware of any instance where the participant(s) suddenly declared they could perceive no differences once the test went blind. If they did, the test couldn't be conducted in the first place.
Instead, what typically happens is that the participants continue to perceive differences even when the test goes blind. The only difference is that their identification of the items under test based on those perceived differences are incorrect about as often as they're correct.
You seem to be operating from a false premise here.
se
Your beliefs have nothing to do with my reality.
[snip]
On the contrary. I believe that your reality is, well, real to you. Just as my reality, where my believe is a part of, is very real to me.
Anyway, calling my believe religious is unfair. You know quite well that this believe is based on numurous similar tests, documentation and experiences.
While we all know that calling someone religious is an often used attempt to discredit someone if you run out of intelligent arguments, I kind of hoped that most here would be more mature than that.
jd
Last edited:
[snip]The problem, to me, in double blind testing, even in my own environment, is that most differences do disappear, YET they come back with normal listening. Why, is unproven as yet, [snip].
No John, it has been known for DECADES why that is. It is just you and a few others who don't know. There is a clear, accepted, sure-fire explanation why it is so, whether you run away from it or not.
jd
Last edited:
@ janneman & SY,
let me cite "old retired j_j"") once again:
once again:
"Bah! Training and control stimulii for determining test sensitivity and listener performance are obligatory.
I don't know who claims that training is not required, both for ABX (or ABC/hr, or signal detection, or whatever) and for understanding what the stimulii and probe signals actually sound like.
Training is mandatory. Please do tell off the people who claim otherwise.
jj"
There at least two explanations why a difference in an audibility blind test was not detected (result of the statistics) and both are plausible:
1.) the difference is not audible
2.) the difference was not detected due to the test conditions
Without showing that the test was/is reliable, objective and valid, nobody knows if answer 1 or 2 is correct. Everything else is pure speculation.
let me cite "old retired j_j"
once again:"Bah! Training and control stimulii for determining test sensitivity and listener performance are obligatory.
I don't know who claims that training is not required, both for ABX (or ABC/hr, or signal detection, or whatever) and for understanding what the stimulii and probe signals actually sound like.
Training is mandatory. Please do tell off the people who claim otherwise.
jj"
There at least two explanations why a difference in an audibility blind test was not detected (result of the statistics) and both are plausible:
1.) the difference is not audible
2.) the difference was not detected due to the test conditions
Without showing that the test was/is reliable, objective and valid, nobody knows if answer 1 or 2 is correct. Everything else is pure speculation.
There at least two explanations why a difference in an audibility blind test was not detected (result of the statistics) and both are plausible:
1.) the difference is not audible
2.) the difference was not detected due to the test conditions
Fully agree. #2 is eliminated in the case of my offer to help John show the world the superiority of his design since, under all test conditions except no-peeking, he asserts that the differences are clear and repeatable to him. So if he gets a null result, we're only left with #1, at least for John- perhaps someone else could hear a difference. If he gets a significant result, he's instantly Very Big News.
Fully agree. #2 is eliminated in the case of my offer to help John show the world the superiority of his design since, under all test conditions except no-peeking, he asserts that the differences are clear and repeatable to him. So if he gets a null result, we're only left with #1, at least for John- perhaps someone else could hear a difference. If he gets a significant result, he's instantly Very Big News.
In the case, that this was your offer and that i did not miss anything:
"Originally Posted by SY
With no ABX box, but controlled blind level-matched conditions, your system, your choice of material, your control of changeover (other than seeing it), and arranged as repeated paired preference, could you tell the difference BY EAR ALONE between any of the preamps you have in house and a cheap opamp line stage? If "no," then case closed- you believe that can't tell the difference by ear, no matter your dancing. If "yes," I'll be happy to run that test for you, my expense, but you agree that the results be published no matter what the outcome.
Ready to stand up for what you loudly and repeatedly assert?"
I´m sure that it is only a malfunction of my browser
as i can´t see itcould you show me, where your proposal addresses these points:
" Training and control stimulii for determining test sensitivity and listener performance are obligatory."
It doesn't address that point, nor does it address the humidity, nor the exchange rate between the Euro and the dollar. For the specific aim of the test, as opposed to the aims of the excellent tests that JJ has done, it's not relevant. Some of the criteria I outlined are likewise irrelevant to the specific aims of JJ's testing.
- Status
- Not open for further replies.
- Home
- Member Areas
- The Lounge
- John Curl's Blowtorch preamplifier part II