My comment has nothing to do with sensory evaluation, I am talking rewriting basic principles like conservation of energy or charge, super-luminal propagation...
Scott, I think what it is, is that there are many different voices here with different opinions. When people such as Jakob2 write, their words may be directed at, or in response to many different, yet mostly similar posts and intended for reading by many different people. As such, he may feel a need to keep clarifying his points in posts in a way different from private conversation between only two people. Also, I don't think Jakob2 is defending or believes in claims of non-physical hearing abilities.
Last edited:

Ebay $30.00 USB interface/DAC, $20.00 headphones, $10.00 USB thumbdrive, two copies of the same FLAC file (same but different).
After a couple of five minute training sessions I'm picking some really fine differences here.
This is only one test session I will do more in the near future, perhaps I should revisit some earlier tests put up here that I still have on my HD's (somewhere).
Dan.
Last edited:
We have no disagreement there. But, the test equipment needs to be good enough for what is to be measured, that's all.
Right, but I would include not just the test equipment but also the test procedures & the listeners/participants in such an evaluation - is the test capable of differentiating known differences. The sensitivity of the test setup can then be evaluated by use of lower & lower known differences until the JND perceptual threshold for that test is established.
Then it's a matter of using said JND differences as hidden controls within the test itself to establish if during the actual test itself, this perceptual threshold has remained intact or has the actual test now changed this differentiation ability.
It's a test of the claim by some that nothing, except knowledge, has changed in one's auditory perception during blind testing.
Without these internal self-checks, it is just another anecdotal listening impression but done under unnatural test conditions & should be treated the same as other anecdotal listening impressions.
To make the claim that it has more veracity & somehow more scientific is just more wishful thinking
We have no disagreement there. But, the test equipment needs to be good enough for what is to be measured, that's all.
EDIT: By the way, I don't claim any extraordinary abilities.
Fair enough, let me rephrase that a little. I hope you would accept failure to get most ordinary listeners to do better than chance on some, to be specified, DAC listening test.
I hope you would accept failure to get most ordinary listeners to do better than chance on some,
Most people will probably do about the same as what old hearing research shows. The top 5% will probably do a lot better, at least some of them will. The top .01% might surprise everybody, we don't know because we have never really tried to properly test for whatever it is they might be able to do. Whatever they can do, it will not be non-physical, I think we can agree on that in advance.
Last edited:
Right, but I would include not just the test equipment but also the test procedures & the listeners/participants in such an evaluation - is the test capable of differentiating known differences. The sensitivity of the test setup can then be evaluated by use of lower & lower known differences until the JND perceptual threshold for that test is established.
Then it's a matter of using said JND differences as hidden controls within the test itself to establish if during the actual test itself, this perceptual threshold has remained intact or has the actual test now changed this differentiation ability.
I was confused the first time about what you mean here. I mentioned 1dB level change threshold, but what does that have to do with say comparing a Benchmark DAC to a good $300 ESS reference design which can be level matched to <<<1dB?
You seem to be suggestion hiding random -1dB versions of each DAC in the tests or something like that.
Jakob does this fit into use of controls in your experience?
EDIT - On further thought this just open up a cheat like the relay click. Identifying the +-1dB trials 100% would enable manipulation of the statistics if one can not distinguish the other trials.
Last edited:
Somebody who does not understand statistics or the meaning and interpretation of experimental results can not be an engineer.
Depends on the definition and if you like to define it that way it obviously is true, but in a broader sense i think the ongoing discussions in this and other audio forums provide sufficient evidence for my assertion.
Of course, more precisely i have to assume that those who claim to be engineers really are.
From first hand experience (long time ago though) i can assure you that passing quite difficult written exams on statistics is possible without really understanding what it is all about. If you follow formal recipes it will often be sufficient, deeper understanding isn´t required.
To provide further corrobation, over the decades several studies were done to examine the understanding of certain areas of statistical tests among students and scientists in psychology and as an additional group professors/teachers lecturing statistics. The results were consistent and quite surprising/depressing.
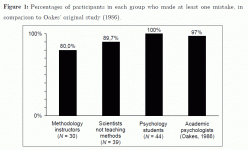
See the attached gif; the graph from the 2001 study includes the result from the experiment from 1986.
@scott wurcer,
i´m in a hurry right now but will address your question about the control and the other points later on.......
Attachments
Last edited:
No, I'm not suggesting that.I was confused the first time about what you mean here. I mentioned 1dB level change threshold, but what does that have to do with say comparing a Benchmark DAC to a good $300 ESS reference design which can be level matched to <<<1dB?
You seem to be suggestion hiding random -1dB versions of each DAC in the tests or something like that.
You seem unable to get your head around the fact that the test itself (including its participants) needs to be verified as capable of differentiating small differences - just like I'm sure you have different measurement equipment whose capabilities differ in this regard.
Do you blindly accept that this equipment is sensitive enough to measure at the sensitivity written on the spec? No, you trust that this has been calibrated correctly & you run routine re-calibrations on scopes, etc.
Here we are using a test with unknown sensitivity & assuming its results have validity - are we trying to measure centimeters with a ruler which only shows meters?
Maybe it's your assumption that auditory perception is like a measuring device - always delivers the same output with the same input? And you believe that the only change being made in a blind test to auditory perception is the removal of knowledge? I'm not sure where your problem in comprehension is?
I'm trying to explain it as best I can but if you prefer Jakob's explanations that's fine.
Last edited:
To provide further corrobation, over the decades several studies were done to examine the understanding of certain areas of statistical tests among students and scientists in psychology and as an additional group professors/teachers lecturing statistics. The results were consistent and quite surprising/depressing.
See the attached gif; the graph from the 2001 study includes the result from the experiment from 1986.
Pretty much what I would expect from psychology students.
You can not use that to infer anything whatsoever with regards to engineering students.
No, I'm not suggesting that.
You seem unable to get your head around the fact that the test itself (including its participants) needs to be verified as capable of differentiating small differences - just like I'm sure you have different measurement equipment whose capabilities differ in this regard.
Do you blindly accept that this equipment is sensitive enough to measure at the sensitivity written on the spec? No, you trust that this has been calibrated correctly & you run routine re-calibrations on scopes, etc.
Here we are using a test with unknown sensitivity & assuming its results have validity - are we trying to measure centimeters with a ruler which only shows meters?
Maybe it's your assumption that auditory perception is like a measuring device - always delivers the same output with the same input? And you believe that the only change being made in a blind test to auditory perception is the removal of knowledge? I'm not sure where your problem in comprehension is?
I'm trying to explain it as best I can but if you prefer Jakob's explanations that's fine.
So instead of testing the hypothesis "there are audible differences between A and B" you want to test the hypothesis "there are humans that can hear differences between A and B". And your procedure is, even so, still incorrect since as Mr. Wurcer said, it can easily lead to manipulating of statistics and guesswork.
BTW, a negative answer (statistical null) to "there are audible differences between A and B"doesn't preclude a positive answer to "there are humans that can hear differences between A and B". If this possible positive result is in general relevant, other that as a curiosity, that's for the community to decide.
No, I'm saying let's test the sensitivity of the test itself & I'm not talking about sensitivity in the statistical sense - just a simple question "is the particular blind test being run & & participants, capable of differentiating between known differences" Let's see some sort of QA measure for the test itself before looking at the results
Are we using a test which can't differentiate known audible differences to evaluate audible differences in the DUT?
It's simple logic but seems to twist some people into pretzels.
Are we using a test which can't differentiate known audible differences to evaluate audible differences in the DUT?
It's simple logic but seems to twist some people into pretzels.
It's simple logic but seems to twist some people into pretzels.
Indeed. Once again, you failed to follow any logic way of thinking and prefer to stay in your own realm of reality. No problem, just don't wonder why people don't take you seriously.
Sounds like it could be used as another excuse not to except the results
Precisely so. Just an excuse to invalidate any result that doesn't match the desired outcome "mains cable A sounds different from mains cable B". If you can't prove a positive, at least claim missing "proper positive controls", spread FUD and make the statistical null result look irrelevant. And of course, ask for more money to conduct more testing.
Do you blindly accept Foobar ABX results without knowing whether the test was capable of discriminating known audible differences first?Sounds like it could be used as another excuse not to except the results
I can provide you with null results for anything you care to 'test' me with - it's no problem.
Indeed. Once again, you failed to follow any logic way of thinking and prefer to stay in your own realm of reality. No problem, just don't wonder why people don't take you seriously.
And once again you fail to address any points I post & simply revert to ad-hom - it really is tedious & yet very revealing
I see you are bereft of any other argument, never dealing with any point I make
Last edited:
Jeez, if you guys would only do a modicum of reading to acquaint yourselves with the ITU recommendations for blind testing (links already given earlier in the thread)
Sorry to say this but you really need to educate yourselves!!
From "Methods for the subjective assessment of small impairments in audio systems "
From "Method for the subjective assessment of intermediate quality level of audio systems"
Sorry to say this but you really need to educate yourselves!!
From "Methods for the subjective assessment of small impairments in audio systems "
3.2.2 Post-screening of subjects
Post-screening methods can be roughly separated into at least two classes; one is based on inconsistencies compared with the mean result and another relies on the ability of the subject to make correct identifications. The first class is never justifiable. Whenever a subjective listening test is performed with the test method recommended here, the required information for the second class of post-screening is automatically available. A suggested statistical method for doing this is described in Attachment 1.
The methods are primarily used to eliminate subjects who cannot make the appropriate discriminations. The application of a post-screening method may clarify the tendencies in a test result. However, bearing in mind the variability of subjects’ sensitivities to different artefacts, caution should be exercised.
From "Method for the subjective assessment of intermediate quality level of audio systems"
4.1.2 Post-screening of assessors
The post-screening method excludes assessors who assign a very high grade to a significantly impaired anchor signal, and those who frequently grade the hidden reference as though it were significantly impaired, as defined by the following metrics:
– an assessor should be excluded from the aggregated responses if he or she rates the hidden reference condition for > 15% of the test items lower than a score of 90;
– an assessor should be excluded from the aggregated responses if he or she rates the mid range anchor for more than 15% of the test items higher than a score of 90. If more than 25% of the assessors rate the mid-range anchor higher than a score of 90, this might indicate that the test item was not degraded significantly by the anchor processing. In this case assessors should not be excluded on the basis of scores for that item.
YOU don't constitute as a statistic, so what you can or can't do is irrelevant. Of course, one can willingly ignore anything he's hearing, even 20dB level differences, and just pick randomly. This would guarantee a null result. For such a subject, a "positive control" won't help at all. Or maybe some subjects are drunk. Or maybe some subjects are tired, Or maybe some subjects don't care. This is where statistics is coming into play, and the audience sample size determination is a critical step.Do you blindly accept Foobar ABX results without knowing whether the test was capable of discriminating known audible differences first?
I can provide you with null results for anything you care to 'test' me with - it's no problem.
Once again, you seem to test the audience sensitivity and not DUTs audible differences.
Eliminating extreme results, as indicated by ITU, is a common practice in any statistical analysis, nothing is specific to audio testing there. There are specialized statistical/mathematical methods for that, chi-squared test comes to mind.
Last edited:
- Status
- Not open for further replies.
- Home
- Member Areas
- The Lounge
- What kind of evidence do you consider as sufficient?