That was probably me (I don't remember, but I recommend this test frequently). It not only has a different timbre that one could probably live with but it shows extreme variation (phasing) with head movement/turn. Actually we use this extreme sound shift to find and center our sweetspot with pink or white noise and search for the amount of toe-in etc that gives the most benign results with head movement (at least that's what I do, and usually this correlates very well with positionings found with real music signals only).Originally posted by ShinOBIWAN
I'm no expert on such things but I heard it mentioned in another thread that there's colouration from the stereo effect. We've all got very used to this by now.Originally posted by eStatic
It's certainly intrinsic, but is it INTENDED, and if so why?Originally posted by phase_accurate
The crosstalk between left and right is intrinsic to and INTENDED for intensity stereo recordings.
The person who talked of this colouration outlined a simple way to demonstrate his thoughts. You take three identical speakers, place them in front of you arranged at the usual left, center, right positions. Play a mono signal into the center and then compare the same mono signal sent to only the left and right. Without the stereo colouration the left and right should produce a phantom image close to the same sound as the single center. However they don't.
As for the original question, all classic and modern miking techniques (especially all stereo mics of any kind, not restricted to intensity-only styles) used for recording classical/acoustical music were/are empirically developed to work with the standard stereo triangle as the reproducing setup, with its inherent crosstalk. That's why the crosstalk is intended and neccessary to give the expected results. By no means it is optimal, and the fathers of stereo were well aware of that (initially, stereo was a three channel thing). The classic stereo triangle, or better said, the reproduction of 2-channel recordings with 2 playback channels, was choosen for its more than adequate capabilities (at that time) with low hardware overhead compared to the trade-offs being made.
The "stereo" that we are used to hear is indeed an aquired perception, we just happened to get used to it, despite its obvoius shortcomings.
There is nothing wrong if someone uses some processing on the audio like crosstalk cancelling if that fits his/her likings better, but one must be aware that such processing unsually changes the timbre quite much as it alters the reverberant energy frequency response. The sound of each speaker is manipulated so as to combine in the right way at the listeners ears but all the off-axis components have a coloration (both in the frequency and time domains) that leaks through, more ore less. I got aware of that when I experimented with some processing similar to Q-sound which allows rendering of phantom sources way outside the speaker baseline, say 60deg to the right (while the speakers are at +-30deg). The needed correction of the speaker signals did strongly color the room response -- it got considerably darker. Also, all this HRTF-based localization tricks are very dependant on exact head position/angle just because of them being HRTF-based. And to some extend all HRTF-manipluations are personally specific (at least in groups, I have some papers on investigations about this).
Personally, I found my prefered way in a 3-speaker reproduction of 2-channel signals, with a left, center and right speaker. This requires a simple rematrixing of the source and there are various options (there are two independend matrix factors that can be adjusted). One of the better working variants for the coefficients is known as "trinaural" or "optimum linear matrix" (search here for these or look here). With this revectoring (only simple arithmetic involved which are reversible and time-invariant, also it it quite benign w.r.t. reverberant sound coloration) most recordings are reproduced in a way that is (to me) more realistic -- in that it gives a stronger, more convincing illusion. The sweet spot is widened (laterally, at the cost of being shorter) and is way more invariant to head turn, which I find one significant feature that gives that more realistic "live" reproduction. The stage does not collapse when you change your head position/angle -- say, when you reach out for your drink... just as it doesn't collapse when you do that in the live club...
- Klaus (sorry to have sidetracked the thread topic)
KSTR said:As for the original question, all classic and modern miking techniques (especially all stereo mics of any kind, not restricted to intensity-only styles) used for recording classical/acoustical music were/are empirically developed to work with the standard stereo triangle as the reproducing setup, with its inherent crosstalk. That's why the crosstalk is intended and neccessary to give the expected results.
Thanks for the clarification. Every thing you say makes sense except the use of the word "intended" and I think we need only substitute "accommodated" for "intended" to arrive at a logically and semantically robust statement.
poldus,
Using the chip is straigforward in the HW config mode. Just pick your digital i/o format with the csel input pins and add SPDIF receiver beofre and transceiver after the chip. No black magic here, just a little SMD soldering. Deactivate all power supplies on the U board, they are very noisy. Use clean digital and analog +5V supply.
Using the chip is straigforward in the HW config mode. Just pick your digital i/o format with the csel input pins and add SPDIF receiver beofre and transceiver after the chip. No black magic here, just a little SMD soldering. Deactivate all power supplies on the U board, they are very noisy. Use clean digital and analog +5V supply.
KSTR said:As for the original question, all classic and modern miking techniques (especially all stereo mics of any kind, not restricted to intensity-only styles) used for recording classical/acoustical music were/are empirically developed to work with the standard stereo triangle as the reproducing setup, with its inherent crosstalk. That's why the crosstalk is intended and neccessary to give the expected results. By no means it is optimal, and the fathers of stereo were well aware of that (initially, stereo was a three channel thing). The classic stereo triangle, or better said, the reproduction of 2-channel recordings with 2 playback channels, was choosen for its more than adequate capabilities (at that time) with low hardware overhead compared to the trade-offs being made.
Trick to handle the shortcomings of stereo (like vocal eq/vocal mix, sphere, soundfield or dummy head mics etc) work extremely well with XTC, because they either record a pinna-less HRTF or mimic something similar. What does not work that great usually is what a faulty stereo recording technique to begin with (wide spaced omnis, coincident mics, added ambience feeds etc), But even for those XTC works better than traditional stereo or 3 channel because it does not attach the sound to the speakers, neither L/R direction not front/back. Compared to XTC the normal stereo always force the "they are in the room" image, while XTC is free of boundaries. (Interestingly XTC without inverse HRTF can create images anywhere behind the speakers, XTC with inverse HRTF can create images behind AND even closer than the speakers) Not to mention, when things get busy and many instruments playing, stereo always collapses, while XTC can keep them separate.
There is nothing wrong if someone uses some processing on the audio like crosstalk cancelling if that fits his/her likings better, but one must be aware that such processing unsually changes the timbre quite much as it alters the reverberant energy frequency response.
Yes, hou have to choose betwen corect timbre at the listening position and weird off axis response (XTC ) or correct (?) off axis response and weird response at the sweet spot (stereo).
A normal hi fi listening room is a crappy environment to begin witht, with or without the "reverberant energy mimicking the mains signal" speakers.
The early reflections in a listening room are too loud and arriving too early, and the reverberant trail is too short and have too fast decay. Controlled dispersion or room treatments will make early reflections less dense/loud, but also makes reverberant trail even shorter. In a completely dead room reverberant field is non existent, dispersion does not matter, but that is the most unnatural setup.
There is no speaker directivity or room treatment what could create a realistic sound field from a stereo speaker setup.
The solution is multichannel. You can play back the recorded (or synthetize if you have only 2 channel recording) the missing reverberant field. This ambient field is usually masking the room's own sound very vell in a treated room, making the speaker off axis response and room sound less of an issue.
fcserei said:A normal hi fi listening room is a crappy environment to begin witht, with or without the "reverberant energy mimicking the mains signal" speakers.
The early reflections in a listening room are too loud and arriving too early, and the reverberant trail is too short and have too fast decay. Controlled dispersion or room treatments will make early reflections less dense/loud, but also makes reverberant trail even shorter. In a completely dead room reverberant field is non existent, dispersion does not matter, but that is the most unnatural setup.
There is no speaker directivity or room treatment what could create a realistic sound field from a stereo speaker setup.
The solution is multichannel. You can play back the recorded (or synthetize if you have only 2 channel recording) the missing reverberant field. This ambient field is usually masking the room's own sound very vell in a treated room, making the speaker off axis response and room sound less of an issue.
I carpeted the floor and walls of our media room.
http://www.diyaudio.com/forums/attachment.php?s=&postid=1421820&stamp=1202345103
I may add a 6 foot wide band of sound absorbing pannels above and moslty in front of the mains. But the room is very dead as is.
At present I am using the Carver C9 for ICC cancellation. It is working very well considering the TV. It will be replaced next year with one that can be placed against the wall and some time this year the Mrs. has agreed to removing the TV so I can play with Ambiophonics
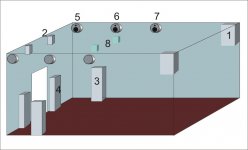
And I'm in the process of adding ambience channels as shown below. Pairs 1 and 2 are in place and get signal from a Yamaha DSP-100U. Pairs 3 and 4 are fed from a Rotel RSP-1066. It has a good number of music settings that feed the surrounds. All of them degrade clarity and imaging when the level are set so that they work for 5.1. One is usable if I reduce the volume of the surrounds—has to be done manually. I have the drivers for pairs 5, 6, and 7 and am about to build the cabinets for those. Overhead and slightly ahead of the sweet spot there will be at least two channels, 8
I plan to feed the ambience and probably surround speakers from a collection of midi controlled reverb processors. The DSP-100U will likely be retained as is. The positions of pairs 1 and 2 are fixed the others are flexible. I’m sure I will be looking for help when I start working out the settings for the ‘verbs. The DSP-100U has 4 settings that are usable with the kind of music I listen to so I will need four “matching” sets of parameters for the verbs. At present I’d be grateful for y’alls reflections on the position of the ambience channels.
Attachments

Common PS does it, you don't need clean power for the on-chip dac, but as far as i remember even if you don't use it, you need the analog PS.poldus said:fcserei,
Do i need two independent 5v power supplies (for analog and digital), or one for both?
Could you point me to an spdif receiver and transceiver that I could buy for this application? I don´t know what these things are.
I was thinking about cs8404/cs8414 or similar transceivers.
I already ordered a pair of receiver boards, not expensive at all with the current dollar, so I won´t necesarily be pulling my hair in anger if things don´t work out as expected.
Here is a layout. How do I connect these to the yss901? http://www.twistedpearaudio.com/images/opus2/wm8804_layout.jpg
http://www.twistedpearaudio.com/images/opus2/wm8804_layout.jpg
Here is a layout. How do I connect these to the yss901?
http://www.twistedpearaudio.com/images/opus2/wm8804_layout.jpgpoldus said:fcserei:
Someone in another thread has remarked that the yss uses a 64fs format. Would that be incompatible with the twisted pear receiver?
Not nearly as incompatible as the other 3 input formats.
facserei:
I started a new thread under the name: help this clueless newbie in a mission, so I don´t hijack this thread or bug you with so many questions. I am getting great help there and learning a lot.
However, you have hands-on knowledge on the chip and I figure your insight is a must.
I have figured this connection diagram based on your early posts on how to connect to a panasonic receiver. Does it look o.k to you?
You said that SYNC needs one BCLK delay, and DOUT needs delay also when connected to LCRK from the pana.
Would that apply to my configuration as well? How do you achieve delay?
I started a new thread under the name: help this clueless newbie in a mission, so I don´t hijack this thread or bug you with so many questions. I am getting great help there and learning a lot.
However, you have hands-on knowledge on the chip and I figure your insight is a must.
I have figured this connection diagram based on your early posts on how to connect to a panasonic receiver. Does it look o.k to you?
You said that SYNC needs one BCLK delay, and DOUT needs delay also when connected to LCRK from the pana.
Would that apply to my configuration as well? How do you achieve delay?
Attachments
I already have a yss901 working with analogue in/out and the physical barrier has been removed.
I am currently experimenting with the separation/angle of the stereo dipole to achieve the widest image.
I think I will build a dipole where the left and right drivers´ rims converge at the center of the box (minimum possible distance between them) and facing slightly outwards (convex baffle).
So far I´m convinced this widens the image the most.
I would like to know if this matches others´ experiences.
On a different note, I have some digital background noise that I´m trying to remove (by hit-or-miss trials since I have no training in electronics whatsoever). I just found the quietest spots on the board so far to apply external analog and digital 5V but I´m looking to improving this area.
I will soon attempt digital in/out with another chip (I bought ten from China)
I am very, very excited over my achievements so far !
I am currently experimenting with the separation/angle of the stereo dipole to achieve the widest image.
I think I will build a dipole where the left and right drivers´ rims converge at the center of the box (minimum possible distance between them) and facing slightly outwards (convex baffle).
So far I´m convinced this widens the image the most.
I would like to know if this matches others´ experiences.
On a different note, I have some digital background noise that I´m trying to remove (by hit-or-miss trials since I have no training in electronics whatsoever). I just found the quietest spots on the board so far to apply external analog and digital 5V but I´m looking to improving this area.
I will soon attempt digital in/out with another chip (I bought ten from China)
I am very, very excited over my achievements so far !
durwood said:estatic-
Did you write a RACE VST encoder plugin that can be used in Console? If so is it possible or would you be willing to share it to experiment with it?
The one I've written is done in Reaktor which will run as a VST plugin but you have to have Reaktor.
I'm thinking about writing a VST for the Choueiri convolution based system. If I get over the VST API learning curve I'll do one for RACE first and post the source. BTW RACE seems to attenuate the center stage component of the stereo signal. I've talked to several others that also experience that. Anyone here have input on that?
eStatic said:
The one I've written is done in Reaktor which will run as a VST plugin but you have to have Reaktor.
I'm thinking about writing a VST for the Choueiri convolution based system. If I get over the VST API learning curve I'll do one for RACE first and post the source. BTW RACE seems to attenuate the center stage component of the stereo signal. I've talked to several others that also experience that. Anyone here have input on that?
Ya I saw your other post later after I posted that. The attenuation also happens with the Choueiri. This is normal and how it's supposed to work from my understanding. With a standard equilateral stereo setup (60% acoustic crosstalk), the geometry and crosstalk creates a phantom center image when the image is located in the center. When you push the speakers close together this center image becomes stronger due to the amount/percentage of crosstalk increasing. Therefore, the crosstalk cancelation corrects this and evens it out. That is my understanding but don't take my word for it.
If you could code a VST that would be great! I wish I could help
I'm currently using the X-volver VST and impluse files, but I have to load them up everytime the PC restarts. I've also got some older ambiophonic VST plugins from the nice people over at doom9.org. They are older (2004) and don't seem to give me the same results, but there are no impulses to load so that is a plus.durwood said:
The attenuation also happens with the Choueiri. This is normal and how it's supposed to work from my understanding.
Well that's a bug not a feature as far as I can tell. When one pans a signal across the sound stage the volume should not change perceptibly, but it does. It looks like I will be seeing Robin Miller in the first part of May. I'll definitely ask him about this.
- Home
- Loudspeakers
- Multi-Way
- Try Ambiophonics with your speakers