the participants also have no freedom in what music they play or how/on what it was recorded.I agree on both. Too high volume can pick up noise-only related issues. 16 trials at least, agreed.
For the reason of possible "too high volume" issue, I constituted both of my latest test to be immune to this manipulation. This is made by sample music choice, cutting no-signal beginning and ending of files and further tests and file comparing.
That does seem like a dodge - unless you have some controls you will never be able to answer the question I posed & the people doing your tests should also be aware that they are using a test procedure with unknown sensitivity.Regarding test to hidden controls sensitivity, IME I did what I could.
the participants also have no freedom in what music they play or how/on what it was recorded.
That is correct. However, in the latest test they are comparing an original file vs. the recorded file, that means an original with a chain: D/A - hybrid tube/SS power amp - A/D. The recorded file has so many variables and influences that the participants might have been able to get a positive ABX result?
I would understand if you complained against validity of a positive result, but why against negative result? Just a suspicion?
That does seem like a dodge - unless you have some controls you will never be able to answer the question I posed & the people doing your tests should also be aware that they are using a test procedure with unknown sensitivity.
What kind of "some controls" are you requesting, and please describe it exactly.
I guess that any kind of measurements or file analysis is not enough for you.
@PMA, what I'm pointing out is that your statement "absolutely free choice of almost anything," really doesn't stand up to scrutiny & the very fact that participants know they are being 'tested' is an overriding stressor. So I don't about you are free argument, either.
As I & & others have said, a relaxed listening to many types of music over some extended period is far different to what you are doing.
I also just have to point out the underlying bias that is seen in this form of testing - you just spent to some lengths in your latest test files to eliminate 'cheating' by too high a volume, yet you dismiss any effort to test the sensitivity of the test itself.
This bias is also seen in the writers of Foobar ABX who updated it a while back adding on anti-cheating measures (log file checksum) but not paying the slightest effort in implementing hidden controls - it would be easy for the ABX utility implement the hidden control I suggested.
All the efforts are to minimise positive results - no effort to validate the test itself
As I & & others have said, a relaxed listening to many types of music over some extended period is far different to what you are doing.
I also just have to point out the underlying bias that is seen in this form of testing - you just spent to some lengths in your latest test files to eliminate 'cheating' by too high a volume, yet you dismiss any effort to test the sensitivity of the test itself.
This bias is also seen in the writers of Foobar ABX who updated it a while back adding on anti-cheating measures (log file checksum) but not paying the slightest effort in implementing hidden controls - it would be easy for the ABX utility implement the hidden control I suggested.
All the efforts are to minimise positive results - no effort to validate the test itself
Last edited:
I already described it in sufficient detail for anyone interested to implement - please reread a couple of posts backWhat kind of "some controls" are you requesting, and please describe it exactly.
Is the reason for DBTs not to ascertain audibility? If not then why not just stick to measurements if you're sure they define all that can be heard?I guess that any kind of measurements or file analysis is not enough for you.
If someone says he clearly hears a difference in a sighted test and he was listening to two bit identical files, then it is a false positive result produced by the sighted test.
How do I know that the ABX has produced a false negative result?
The usual approach to get more information would be an analysis following the hit/miss scheme used in the SDT experiments.
Unfortunately you must have a log of the trials to know what was presented as "A, B and X" and to look for some patterns in the results.
<snip>
So, IMO, all your suggestions are fulfilled, the participant has absolutely free choice of almost anything, no stress, he does not have to go somewhere and fulfill the protocol of the test in unknown place with unknown people.
So, taking into account this almost absolute freedom of choice and no pressure, why are there almost no positive ABX results in tests like wire x tube pre with 0.5 - 1% distortion, or even when testing the original file vs. recording through hybrid power amp with same distortion, loaded with speakers? Is it because of "stress", or for the reason that the sound differences are at the threshold of hearing resolution, hearing cleaned from sighted biases like look, brand, good highend story etc.?
Which means that listeners that aren´t used to do such tests should figure out themselves which method provides correct results. But they don´t get help by any advice or positive controls that can be used for training purposes.
Good questions what the reason for having nonpositive ABX results is; usually an experiment should be designed to help answer those questions, but as you might remember, if it can´t be shown that a test is objective, reliable and valid you can´t draw further conclusions from the results.
That´s the reason why the test is done and still the questions remain.
Last edited:
That is correct. However, in the latest test they are comparing an original file vs. the recorded file, that means an original with a chain: D/A - hybrid tube/SS power amp - A/D. The recorded file has so many variables and influences that the participants might have been able to get a positive ABX result?
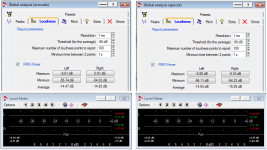
In terms of level balancing, you have done a great job. Plus the amp does not change the dynamic range of the signal (<0.2dB)
I already described it in sufficient detail for anyone interested to implement - please reread a couple of posts back
Is this one?
The use of some form of hidden controls, as recommended in ITU guidelines, is one possibility to ascertain is the participant sensitive to a certain level of known audible difference - for instance in one or more of the 16 trials of an ABX test, B could be an exact copy of A except that it has been adjusted by 1dB (or whatever is deemed appropriate) & if X is not identified correctly as A or B then we have an indication of false negative for this particular type of difference - does it generalize to lack of sensitivity to other small impairments? More than one trial & more than one run of ABX would be needed to evaluate the sensitivity of the participant/test to small impairments. Volume level is just one suggestion, easy to implement, to act as a hidden control - other differences are possible & other approaches have been suggested in the past
George
Attachments
@ PMA,
we addressed the question for a positive control in the other threads already quite extensive.
The level difference is a good one, as listeners usually (means in a multidimensional evaluation) , if the level difference gets small between the samples, don´t recognize it as a level difference but as a sound difference.
It depends on the experience, at first listeners may have difficulties to recognize a level difference of 1 dB as such, while experienced listeners will still be able to do it.
Below 0.3 dB it gets more and more difficult and that´s usually the region where imE all listeners only notice the sound difference but not the level difference as such.
So using level difference at different niveaus even allows to monitor the effect of training.
Wrt the sample size needed; what Leventhal did was to reinvent the power analysis concept that Jacob Cohen revided already in the mid 1960s.
To reach the usual SL = 0.05 you don´t 16 samples (that´s why our preamplifier could be used although there were only two tests of 5 samples done) and wrt statistical power 16 samples do not really help either.
I´ve posted some power calculations before, so only in short now; if you want a power of at leas 0.8 and want still be able to get positive results for low detecting abilities under the test conditions, then it the variables are:
power = 0.8
SL = 0.05
p2 = 0.6
p = 0.5
and therefore the sample size needed would be 158.
Otoh, we could calculate the power that results for the same variables but a given sample size of 16:
SL= 0.05
p2 = 0.6
p = 0.5
sample size = 16
and then the actual power will be 0.167. Which means the chance to miss this difference (which _is_ perceptable, so the null hypothesis must be rejected) is a whopping 83.3 % .
If you would like to balance SL and statistical power to have the same error risk in all cases, things are getting even more worse.
Small effects, as DPH already mentioned, to detect is difficult.
we addressed the question for a positive control in the other threads already quite extensive.
The level difference is a good one, as listeners usually (means in a multidimensional evaluation) , if the level difference gets small between the samples, don´t recognize it as a level difference but as a sound difference.
It depends on the experience, at first listeners may have difficulties to recognize a level difference of 1 dB as such, while experienced listeners will still be able to do it.
Below 0.3 dB it gets more and more difficult and that´s usually the region where imE all listeners only notice the sound difference but not the level difference as such.
So using level difference at different niveaus even allows to monitor the effect of training.
Wrt the sample size needed; what Leventhal did was to reinvent the power analysis concept that Jacob Cohen revided already in the mid 1960s.
To reach the usual SL = 0.05 you don´t 16 samples (that´s why our preamplifier could be used although there were only two tests of 5 samples done) and wrt statistical power 16 samples do not really help either.
I´ve posted some power calculations before, so only in short now; if you want a power of at leas 0.8 and want still be able to get positive results for low detecting abilities under the test conditions, then it the variables are:
power = 0.8
SL = 0.05
p2 = 0.6
p = 0.5
and therefore the sample size needed would be 158.
Otoh, we could calculate the power that results for the same variables but a given sample size of 16:
SL= 0.05
p2 = 0.6
p = 0.5
sample size = 16
and then the actual power will be 0.167. Which means the chance to miss this difference (which _is_ perceptable, so the null hypothesis must be rejected) is a whopping 83.3 % .
If you would like to balance SL and statistical power to have the same error risk in all cases, things are getting even more worse.
Small effects, as DPH already mentioned, to detect is difficult.
Yes it is really a scientific process steered by real-life KPI like lap-times on the Ring etc. Due to these KPIs, all tweakers and boutique components are since long gone. Our "game" don't have the corresponding undeniable KPIs so wodo may still reign. From this, one realises that it is not the audio components that is in dear need to be progressed but the KPIs - would we want to advance the field.
//
Yet, blind testing apparently never has become a great succes in automobile development either. There must be a lesson in this for audio!
Yet, blind testing apparently never has become a great succes in automobile development either. There must be a lesson in this for audio!
But it's not all measurements/simulations in F1 car development - drivers, test drive & give feedback about car handling, etc.
I may be wrong, but I suspect that you have suggested it. Certainly someone has. You talk as though you are not 'on here' but merely talking to people 'on here' (from an imagined position of superiority?).mmerrill99 said:But I've never seen anybody on here suggest that if you are negatively biased towards there being an audible difference in amplifiers (for instance, could be DACs, cables, whatever) then you are likely not a suitable listener for ABX testing of amplifiers, as you will be biased towards a null result - have you?
Everyone has prior assumptions, 'positive' or 'negative'. A good test will help overcome them, unless they are so strong that they are forced to reject the test results.What if people don't know or admit to their negative bias, how do you discover it?
Nobody has evidence which you will accept, because your bias is so strong.Have you got some acceptable evidence that the results from 'sighted' listening ala how Hoyt stated are more wrong than the results from ABX listening?
Do I detect some wriggling and squirming in the light of an inconvenient test result? Differences clearly 'heard' between bit-identical files are somehow not a false positive? Differences between item A (seeing A) and item A (seeing B) are not a false positive?Perhaps but there can be other physical factors besides bit patterns that may not be the same between listening sessions & could result in audible differences.
Surely this is not bias at work?
In terms of level balancing, you have done a great job. Plus the amp does not change the dynamic range of the signal (<0.2dB)
Is this one?
George
Thank you for posting your analysis, George. I will post mine as well, but it is good to have yours as an independent one.
However, I do not think it is a technical point or real test parameters that are attacked. It is the ABX itself, by those who do not like the protocol. I understand it, but if I have a choice between technically well performed ABX and a sighted test, I would vote for the ABX. Further, where is the proof that the parameters like level equalization within 0.2dB were fulfilled in the sighted test? That would be my question to the oponnents.
Attachments
Below 0.3 dB it gets more and more difficult and that´s usually the region where imE all listeners only notice the sound difference but not the level difference as such.
So using level difference at different niveaus even allows to monitor the effect of training.
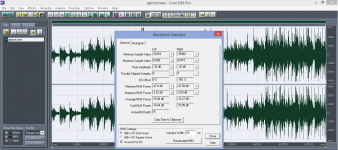
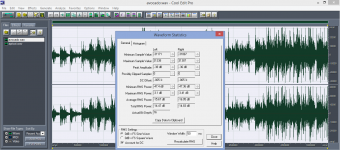
As you know well, level difference is not only a result of "volume control setting", but it is however a quite complex result of frequency response and non-linearities as well. As a non-linearity in my DUT goes up to 1%, it affects the "level" as well, should it be a peak level, peak rms, avg rms and min/max rms. Please check the file stats I have shown in my previous post.
However, we still have a "null" ABX result, so we should not blame the result to a "poor" 0.2dB level matching.
Last edited:
As you know well, level difference is not only a result of "volume control setting", but it is however a quite complex result of frequency response and non-linearities as well. As a non-linearity in my DUT goes up to 1%, it affects the "level" as well, should it be a peak level, peak rms, avg rms and min/max rms. Please check the file stats I have shown in my previous post.
A positive control is a difference (known to be detectable) presented within a test setup to check if everything works as intended.
So, the answer to your question is simple, use material where such difficulties does not exist; for example take the "wire sample" and use it to present the mentioned level difference as a positive control.
But it's not all measurements/simulations in F1 car development - drivers, test drive & give feedback about car handling, etc.
It will soon be over...
YouTube
//
Semantics, semantics - you know what I mean but choose to take a different meaning - I wonder should you be accused of "putting words in my mouth"?I may be wrong, but I suspect that you have suggested it. Certainly someone has. You talk as though you are not 'on here' but merely talking to people 'on here' (from an imagined position of superiority?).
Yes, you make my point - so let's try to use a "good test" by using some controls that internally validate the test procedure - simple, reallyEveryone has prior assumptions, 'positive' or 'negative'. A good test will help overcome them, unless they are so strong that they are forced to reject the test results.
Try me with some evidence rather than some spurious argument. I have a feeling that you are really being self-revealing in this as I seem to remember that you rejected Jakob2's evidence about the insensitivity of ABX testing - am I wrong?Nobody has evidence which you will accept, because your bias is so strong.
Do I detect some wriggling and squirming in the light of an inconvenient test result? Differences clearly 'heard' between bit-identical files are somehow not a false positive? Differences between item A (seeing A) and item A (seeing B) are not a false positive?
Surely this is not bias at work?
Of course there can be false positives in sighted listening, I stated that many times already but you fail to admit that ABX testing is prone to false negatives despite evidence & many here still use ABX test results (of any quality) to try to claim that a sighted listening report is a false positive. Fact of the matter is you are trying to elevate some unknown quality listening 'test' to a status that is unwarranted & unscientific & trying to use it to negate sighted listening
A positive control is a difference (known to be detectable) presented within a test setup to check if everything works as intended.
So, the answer to your question is simple, use material where such difficulties does not exist; for example take the "wire sample" and use it to present the mentioned level difference as a positive control.
Oh, I see. In a test setup itself, the level difference is verified to be in order of 0.01dB. Less than 0.1dB. Now, please tell me why you ask, if there has been no positive ABX protocol yet?. In case there are positive results, I understand there is a reason of being suspicious to the level difference only. I still have a strong feeling there is a reluctance to the ABX method itself, rather than to real technical issues. Seems to me as a substitute issue.
Now, to your test with black boxes. I have read your description carefully. Please tell me, you, who say that 16 attempts in ABX is not enough and you consider it statistically unimportant, how valid is your 5/5 result in a semi-sighted, semi-blind test as you have described.
<snip>
Further, where is the proof that the parameters like level equalization within 0.2dB were fulfilled in the sighted test? That would be my question to the oponnents.
There must exist (still after all these years
") ) some profund misunderstandings.
) some profund misunderstandings.The most outspoken advocats for strict level equality were indeed the proponents of "blind" listening tests (in which was back then usually the ABX comparator was used). Level difference should be below 0.1 dB (iirc in the Clark amplifier challenge hhoyt mentioned the target was below 0.05 dB).
Despite the "partisan" attribution there is good reason for best possible level equality especially when using fast/easy switching between the DUTs.
In sighted listening the most common routine (i´ve seen used) is/was to reduce the level to zero before changing the DUT and after the exchange to step the level up until listeners think it´s almost the same loudness as before.
I have done some tests with (obviously unbiased listeners due to the results) humans to monitor what level difference using this routine will be actually result and found (by using music) that the difference was in the region of 0.3 dB - 0.8 dB, but randomly distributed between the two DUTs.
As written quite often before, in this case the level difference presents an additional "noise" that might make detecting the real difference (if any exists) more difficult.
If listeners are biased (under sighted conditions) it obviously can happen that the level difference will not be randomly distributed but in favour of one of the DUTs, so that should be monitored/ruled out.
- Status
- Not open for further replies.
- Home
- Member Areas
- The Lounge
- John Curl's Blowtorch preamplifier part III