While the arguement goes on here as to whether 2 opamps is better than 2 fets and is better than 2 tubes take the time admire what can be done with 2 spoons
https://youtu.be/_nLmM9kcBKs
https://youtu.be/_nLmM9kcBKs
<snip>
I did not specifically mention Foobar ABX. I was merely expressing surprise at Jakob's claim that a mountain of evidence would indicate test weakness rather than truth.
I hope at that point we are now on agreement that my comments were related to this specific example and which way the analysis works?
No, I am simply asking 'under these conditions can they distinguish A from B?'. That is all.
You were arguing that this was in fact "checking the properties of the detector" and i hope we can agree, that you can´t check the unknown properties of a detector by presenting a unknown difference to this detector?!
<snip>That is all. We know that allowing them to see A and B renders the test fatally flawed, because then they may reliably hear differences between A and A if they see B and hear A.
We don´t know if a sighted test is really flawed but we know that there is a risk of being flawed and furthermore we can´t show internal validity if doing a "sighted listening test" .
Reporting of differences in case of listening/testing identical stimuli isn´t associated with "sighted listening" as we already know that in multidimensional sensory tests the percentage of wrong answers (when presenting the exact same stimulus twice) can be as high as 80%.
That is one of the reasons why i often wrote that it is as easy to get incorrect results in "blind tests" as it is in "sighted tests" .
'Test stress' is only an issue for people whose reputation is on the line.
I prefer to use "distraction" instead of "test stress" as the latter seems to implicate something else.
But in any case the question would be how could you know that without testing it seperately?
True. What is the distraction in this case?
First, doing a "blind listening test"; it think/hope we can agree on the fact that doing such isn´t any "normal" for most consumers/listeners.
Second, furthermore using a test protocal like ABX that makes getting a (even true) positive result more difficult than other test protocols.
At that point i wonder, because i´ve written something like this:
I have posted in other threads the publications about experiments where ABX and other protocols were compared wrt sensory differences and percentage of correct (poc) and wrt limit numbers.
It was shown and corrobated by replications that the poc in ABX tests was significantly lower than in other protocols like A/B and even 3AFC when testing the same sensory difference.
It was also reported (earliest reference dated from ~1952 that differences for pitch found "distinguishable" were constantly lower in A/B tests than in ABX tests.
Imo you´ve neglect it always, but why? Do think it doesn´t mean anything?
I´m asking because the paragraph above describes why the "distraction level" in an ABX test is usually higher than in an experiment using another test protocol.
It is known (scientific evidence corrobated by different studies in different fields) that in case of a multidimensional test, the specific test protocol does have a significant impact on the test participants.
More precisely the percentage of correct answers is significantly different when testing the same sensory difference but with different test protocols.
All that without any "reputation" at stake; if reputation is a parameter it might be even more worse.
The interesting point in the comparison was that an ABX requires to process three stimuli for internal judgement and answering the question which is the same number as in case of a 3-AFC protocol, but nevertheless the percentage of correct answers was lower in the ABX tests.
OK, I take your point.
Another example would be the "Clark amplifier challenge" that hhoyt mentioned in the last days. Beside the fact that combining it with a serious money bet (which is known to represent another confounding variable) it was reported that although "a couple of thousands people tooke the test" not a single listener got more than 65% correct answers.
If you calculate the probability for such an outcome you get extremely low values. Of course everything is possible but chances are quite high that something else was wrong .....
I find statistics to be rather like quantum mechanics: lots of people can do the sums, but far fewer can actually explain what they mean - and there are different schools of thought who each claim to have the whole truth.
It is difficult, sometimes counterintuitive and there is actually no reason to restrict ourselfs in the methods used for analysis.
I remember in first-year QM we were taught the Copenhagen School understanding, but we were not told that this was merely one school and there were others; I was a bit annoyed when I later discovered this.
In statistics it is the different approaches like Frequentist, Bayesian or Maximum Likelihood and others as well. The replication crisis in some fields of science led to higher motivation to overcome the dogmatic restraints, as it is more wise to use several tools instead of only one.
As mentioned before, things are complicated as (according to several studies done over the last ~30 years) at least some misconceptions are believed, used and even teached by practioneers/teachers on university level.
<snip> However, I sometimes feel that statistics are being used to obscure things rather than reveal them.
Happens sometimes (intentionally and unintentionally) but given our example, the traditional ABX analysis (as used by "Foorbar) follows the Frequentist approach which is conceptually based/related "on the long run" means not single cases but larger samples and replications.
So if we are talking about "hundreds of tests/experiments" (or even more) this approach is reasonable for calculating the numbers under the assumption that the null-hypothesis (i.e. random guessing) is true.
While the arguement goes on here as to whether 2 opamps is better than 2 fets and is better than 2 tubes take the time admire what can be done with 2 spoons
https://youtu.be/_nLmM9kcBKs
Thanks for the link!
"As easy"? Surely a sighted test makes incorrect results (for 'hearing') at least slightly more likely?Jakob2 said:That is one of the reasons why i often wrote that it is as easy to get incorrect results in "blind tests" as it is in "sighted tests" .
Difference I would expect. Significant difference is perhaps a bit more surprising. How significant, enough to render some protocols unhelpful?More precisely the percentage of correct answers is significantly different when testing the same sensory difference but with different test protocols.
The problem with calculating probability is that you have to make some assumptions, which may or may not be reasonable assumptions and may or may not appear to be reasonable to others.If you calculate the probability for such an outcome you get extremely low values.
My concern remains that, as a general rule, people object to tests when they don't like the result - especially if they find the result commercially challenging. Having decided that they don't like the result, they can then almost always find some grounds on which to criticise the test. The same people can be curiously accepting when a test gives the result they prefer. This can happen on both sides of the 'audio debate', of course.
ABX seems to be acquiring the same notoriety as THD. It is just a protocol, as THD is just a number. It is not as important to us as those opposed to it seem to imagine. Instead of bashing ABX, perhaps some people ought to try to come up with good reasons why they trust the results of sighted tests?
Is that the royal we?We don't know if a sighted test is really flawed
") I know it has to be.....https://www.youtube.com/watch?v=q78ppqlOl1U
I know it has to be.....https://www.youtube.com/watch?v=q78ppqlOl1UHappy to help you out again, doesn't it get painful sitting on that fence?
I think you are misunderstanding the concept of what CG posted - noise floor modulation would not show up on an FFT as the noise floor itself is not specifically shown on an FFT (unless this is specifically being tested for) due to the way FFT works.
No the FFT shows everything in the data it is a completely reversible transform of all the information. The problem is with music there is information in all bins and what would be noise is obscured so the multi-tone test was suggested.
Demian is right diff gain and diff phase are virtually synonymous with AM and FM and these sidebands fill in (in the case of music) the noise "floor". But diff gain and diff phase at single tones are easily measured these days. The whole PIM controversy is well documented and as Ron Quan found many modern op-amps have virtually un-measurable amounts while well regarded low feedback and open loop designs often have large amounts. A simulation should be able to show this.
I was suggesting something like what we used to test ADSL drivers. A continuous stream of symbols with "holes" in the spectrum that fill up with the "noise". We actually had complex filters custom made to do analog verification of all our drivers. There were no DAC's at the time capable of -90dB floor on the notches at 30MHz but Allen Avionics could make L/C filters that did (IIRC they made some of them products). A ppt on some of this.
https://www.keysight.com/main/redir...31:epsg:apn&lc=eng&cc=US&nfr=-33237.536894531
I think you are misunderstanding the concept of what CG posted - noise floor modulation would not show up on an FFT as the noise floor itself is not specifically shown on an FFT (unless this is specifically being tested for) due to the way FFT works.
The "noise floor" of the FFT depends on both resolution (number of bits) and bin-width (equivalent to tuned notch BW). The narrower the bin-width (more samples in a FFT record), the "deeper" we get in the "noise floor". The so-called noise floor of the FFT spectrum plot is rather a spectral density with BW defined by a bin-width. The real "noise floor" is integrated over the whole audio band and may lie tens of dB above narrow band FFT "noise floor", it may be 50dB difference quite normally.
We don´t know if a sighted test is really flawed but we know that there is a risk of being flawed and furthermore we can´t show internal validity if doing a "sighted listening test" .
Agreed, Jakob. Although we cannot know if a specific test result was flawed, as you point out the technique certainly is. The results of our multiple tests conclusively showed that for relatively minor differences our sight takes precedence over our ears. There was no doubt or confusion in the test results. Having been there for the tests I can state with the minor differences heard between most quality amplifiers operating below clipping our sight cues trump our aural cues. This doesn't mean the minor differences are unimportant, on the contrary these differences define the SOTA and are likely the reason most of us joined this forum in the first place. The test results do however dismiss sighted testing as a valid technique to determine minor differences.
It has been established that sighted listening has an affect to aural perception by the very people who espouse it, as well as by testing I was witness to. I was under the impression that our goal was superior aural performance. Considering these facts I don't understand why anyone would still want to consider sighted preference testing a valid technique to determine purely aural performance. How about this idea: faux front panels so those preferring sighted testing could still do so, but both amplifiers would look the same. What do you think the results would be then?
It would be interesting to determine the threshold for certain types of differences (amplitude, freq response, distortion) by conducting sighted tests while increasing the amount of difference between sources until the aural cues outweighed the visual cues... which sounds like a huge PITA considering the possible confounding factors which we found plague ABX testing (repetition, fatigue, controlling light, temperature, time of day, belly filling factor...) and which are why I don't blindly accept ABX. And the result of these tests would be a comparison (in dB for each factor) of the relative precedence of visual stimulus over aural stimulus. Kind of interesting from a physiological viewpoint, but not terribly relevant to understanding aural performance of different circuit topologies...which is why I joined this group...
After having been unfortunately involved in many exhausting testing experiences, I now find the best way to evaluate components is ~30 minute relaxed listening sessions with a variety of music to excite system weaknesses in a dimly lit room I am familiar with. If I hear something I want to compare, I iterate between different components until I am satisfied the difference exists or does not and move on. If the difference is so small I cannot decide if it actually exists then the difference is unimportant and I get on with life. It does not matter to me nor does it make me inferior if someone else could hear that difference, the music in my head comes through my hearing apparatus not theirs. I know of no other more revealing technique if what I am interested in is actual aural performance minus all the other BS.
My vote would be to move on to other, more electronic topics like John just posted and agreeing to listening in dimly lit rooms of our choice.
Just my 2¢ worth,
Howie
The interesting point (or surprising at least for me) was that the ABX protocol does not lower the risk of false positives, as the guard against that is the SL (or alpha error; leaving aside for simplicity the philosphical differences between concepts for the moment) nor raises the efficiency - it´s still the same dichotomous results as in case of an A/B - but actually lowers the rate of _correct_ positives, if using for analysis the test statistic of accumulated correct trials and the exact binomial test.
Citation? How was the testing and analysis done?
Leventhal´s analysis would still hold true in case of using A/B protocols, as it was just based on Cohen´s power analysis (and recommendations) so would only reflect the specific problems presented by the ABX protocol by in the assumptions about lowering the percentage of correct answers.
As a general comment on Leventhal's critique (and not your comment), it carries with it the acknowledgment that small effects are hard to find, regardless the protocol. The only context I've seen Leventhal quoted is in attempts to discredit any and all ABX protocols, which raises alarm bells, rather than acknowledge that it essentially says, "we don't have the statistical power to say anything about small effects".
(Again not to you) but Clark, et al.'s part of the debate should also be read before passing judgment. A criticism I would make is that it'd be nice to show the effectiveness of Clark's chosen ABX protocol against varying, synthetic positives to have a better characterization of their overarching experimental design. If that data exists, I haven't seen it and would be most appreciative of anyone who can link it.
One thing that gets ignored is that Leventhal's assessment also leaves wide open that purported large effects are generally within the capability of these lower-N experiments. So a null result on a large effect means that the effect is smaller (up through the possibility of essentially nonexistent) than the test's sensitivity. So in the sense of acting like a coarse sieve for a lot of more extreme claims, an ABX is effective (as really most any commonly-accepted protocol, more a matter of getting a person to sit down and conduct a DBT of any sort).
I think Howie covers a lot of other points pretty well. Ultimately, we're in the business of making ourselves happy (I hope!) with listening to music, so do whatever gets you there.
And thanks to 1audio/Scott/PMA for clarifying the whole FFT vs noise modulation thing more clearly than I managed to do. It's admittedly afield of what I do, so I didn't know the present best practices to test the phenomenon. I was thinking more of interfering two signals (one passing through the DUT) and see if the misbehavior shows up as varying interference patterns based on signals. At the end of the day it's modulation so it's going to show up (just don't use a totally white source).
The "noise floor" of the FFT depends on both resolution (number of bits) and bin-width (equivalent to tuned notch BW).
The original comment was based on simulation with care you should be able to keep the numerical noise floor down to -300dB. A long transient analysis of a real amplifier circuit show what we are looking for.
^I was thinking in terms of square waves (albeit I guess I should call it a pulse train of ___ length rather than indefinite), which is essentially a band-limited multi-tone. But that was more for my own intellectual cleanliness; I'm sure a better designed multi-tone could be used.
I guess I should butt in one more time as to what I find, works! Double blind testing was tried by just about everybody, starting 40 years ago. What we found was a lot of false negatives due to the test. I am particularly susceptible to not hearing any real differences in an ABX test. Some others, that I know well, have done slightly better than me, but the ABX test still throws away most subtle changes in audio quality.
While I rarely use it today, being too old to really depend on myself, only, I best like the dual choice test, or do you prefer A or B (or even C)? Where A, B etc are randomly assigned, at least not by me. I was put to that test more than 40 years ago in Japan, with unfamiliar circuits under test, unfamiliar listening conditions, and yet I could hear the differences between 3 separate circuits designed by another designer. It shocked everyone around me that I could do it, but I took it for granted. That is what I have done all my life. Yet, I failed miserably with an ABX test at the same time in my life. Why? We have argued this for the last 40 years up to the present. Personally, I will go with what works, not what makes everything sound 'acceptable'.
While I rarely use it today, being too old to really depend on myself, only, I best like the dual choice test, or do you prefer A or B (or even C)? Where A, B etc are randomly assigned, at least not by me. I was put to that test more than 40 years ago in Japan, with unfamiliar circuits under test, unfamiliar listening conditions, and yet I could hear the differences between 3 separate circuits designed by another designer. It shocked everyone around me that I could do it, but I took it for granted. That is what I have done all my life. Yet, I failed miserably with an ABX test at the same time in my life. Why? We have argued this for the last 40 years up to the present. Personally, I will go with what works, not what makes everything sound 'acceptable'.
Last edited:
So to sum up:
1. you know that double-blind tests produce lots of false negatives, in that differences which can clearly be heard in sighted tests cannot be heard in DBT
2. we know that sighted tests produce lots of false positives, in that differences between A and A can be clearly heard when B is seen but A is heard
3. our explanation is that DBT generally finds exactly what existing psychoacoustics and circuit theory says it should find - but we are open to being surprised
4. your explanation is that there are subtle issues (some even claim new physics) which existing knowledge either denies or does not take proper account of - but you are puzzled that these issues never seem to appear in less demanding applications such as telecommunications or gravity waves
Should we just agree to ignore each others tests?
1. you know that double-blind tests produce lots of false negatives, in that differences which can clearly be heard in sighted tests cannot be heard in DBT
2. we know that sighted tests produce lots of false positives, in that differences between A and A can be clearly heard when B is seen but A is heard
3. our explanation is that DBT generally finds exactly what existing psychoacoustics and circuit theory says it should find - but we are open to being surprised
4. your explanation is that there are subtle issues (some even claim new physics) which existing knowledge either denies or does not take proper account of - but you are puzzled that these issues never seem to appear in less demanding applications such as telecommunications or gravity waves
Should we just agree to ignore each others tests?
The original comment was based on simulation with care you should be able to keep the numerical noise floor down to -300dB.
Wow! I am not that good
Anyway, would it have any practical significance to audio?
Attachments
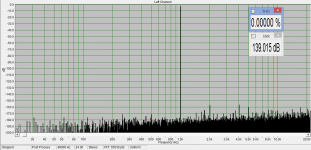
Of course, subtle changes are addressed in telecommunications or gravity waves. It is just that they are kept as 'trade secrets'. The military actually classifies these subtle techniques to keep an advantage over an adversary. Is this not the case where you work as well? I know that when I worked in an optical instrument company, one of the trade secrets was the best way to clean a lens. I never did learn the secret entirely, it was kept under wraps for only those who needed to know. Surely others have had similar experiences.
- Status
- Not open for further replies.
- Home
- Member Areas
- The Lounge
- John Curl's Blowtorch preamplifier part III