That leaves me at an impasse. Is there perhaps a way to further extract the hidden signal and pull it out of the noise?
Hi Pano, if you give me a signal or a link, I will try to extract the signal from noise.
Here is a link to the Sinatra track and to the Sinatra track with the wind quartet mixed in.
low level - Google Drive
low level - Google Drive
I measured my speakers sometime and the thd was 1 to 5 % across the whole range.
This is -25 db to -35 db So I think the test would never work with a sound hidden 30 db below.
When I listen to a music track, if I turn down the volume 25 db down I don't hear anything because I listen low.
2 or 4 things explain the SET phenomenon.
1. I think the SET amp compress the music edge, the high power transients. This enables the ear to be more sensitive to smaller sound level changes because it is not attacked with sudden high pressure signals. The ears become less sensitive the higher the sound volume.
2. The driver of the speaker is not pushed as much during high excursions and have more 2n harmonics. This enables the speaker to deliver much more low level information without interferences from high power signals.
3. only an hypothesis: the circuit simplicity and no feedback help preserving the signal analog sound.
4. The compressing is done in a natural physical way which doesn't harm the analog sound (DSP and any digital compressing and equalization is to me unacceptable and sounds horrible)
This is -25 db to -35 db So I think the test would never work with a sound hidden 30 db below.
When I listen to a music track, if I turn down the volume 25 db down I don't hear anything because I listen low.
2 or 4 things explain the SET phenomenon.
1. I think the SET amp compress the music edge, the high power transients. This enables the ear to be more sensitive to smaller sound level changes because it is not attacked with sudden high pressure signals. The ears become less sensitive the higher the sound volume.
2. The driver of the speaker is not pushed as much during high excursions and have more 2n harmonics. This enables the speaker to deliver much more low level information without interferences from high power signals.
3. only an hypothesis: the circuit simplicity and no feedback help preserving the signal analog sound.
4. The compressing is done in a natural physical way which doesn't harm the analog sound (DSP and any digital compressing and equalization is to me unacceptable and sounds horrible)
Last edited:
FYI, the files are both 44.1/16. I did try making the mixed MP3s from 24 but and 32 bit float files but it didn't seem to make any difference. MP3 is limited to 16 bit depth, I suppose. I didn't save the mixed file in 24 bit, but could do so if that would help.
The files are just under 30 secs long and have a 4410 Hz marker 5 ms in. That marker helps greatly with alignment. I've found that the conversion to MP3 add a bit of silence to the beginning of the file, something to watch out for.
The files are just under 30 secs long and have a 4410 Hz marker 5 ms in. That marker helps greatly with alignment. I've found that the conversion to MP3 add a bit of silence to the beginning of the file, something to watch out for.
That's a good point but don't forget that we can hear detail below the noise, LPs, 45s and 78s making this very clear. How far below the noise floor I don't know, 30dB might be asking too much.This is -25 db to -35 db So I think the test would never work with a sound hidden 30 db below.
Good thoughts on the SET amps, the gentle peak limiting might help bring up some details.
 I'm mostly familiar with SET and SEP amps that use a little negative feedback, on the order of 6dB which seems reasonable and helps clean up a few things. To my ear they work just as well, or better, than zero feedback amps.
I'm mostly familiar with SET and SEP amps that use a little negative feedback, on the order of 6dB which seems reasonable and helps clean up a few things. To my ear they work just as well, or better, than zero feedback amps.Could be fun to see what can be extracted from a single ended triode amp vs a typical solid state amp. A good clean DAC/ADC loop would be helpful.
 Women do have a talent for detecting that low level detail.
Women do have a talent for detecting that low level detail.single ended triode amp vs a typical solid state amp
= I bet it is quite good for the s.e.t.
Wouldn't it be easier to have a listening test with specific tracks which have low level recorded sounds to be recognized?
For example in extract x from 1:00 to 1:10 there is a violin which plays with the bow out of synchronization.
For extract :30 to :35 if you can hear both lines of the alto score.
For :45 : 50 , hear the piccolo among the drums
For 50: 60, how many voices or instruments and words in choir music, harpsichords in orchestra etc.
as well as specific tones of instruments.
= I bet it is quite good for the s.e.t.
Wouldn't it be easier to have a listening test with specific tracks which have low level recorded sounds to be recognized?
For example in extract x from 1:00 to 1:10 there is a violin which plays with the bow out of synchronization.
For extract :30 to :35 if you can hear both lines of the alto score.
For :45 : 50 , hear the piccolo among the drums
For 50: 60, how many voices or instruments and words in choir music, harpsichords in orchestra etc.
as well as specific tones of instruments.
Here is a link to the Sinatra track and to the Sinatra track with the wind quartet mixed in.
low level - Google Drive
Hi Pano,
the objective difference between these 2 files is so tiny that I doubt it might be audible for anyone.
Edit: I mean that it is impossible to hear when comparing the 2 files. The difference itself, after subtraction of the 2 files, is audible. Posted plots are for the difference file.
Attachments
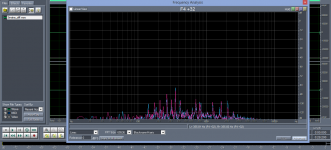
Last edited:
Pano, full credit for looking into this & it has uncovered some interesting things, such as the limitations of Diffmaker :& it's best operational procedures ( more questions about that later, maybe?) I can't find the original DDR thread from which this thread emerged (any link?) But I wonder if DDR means something other than what's being addressed in this thread or if there's another aspect to DDR that this thread isn't addressing? I'm thinking of dynamic range that is changing based on the signal being processed?
My thought is about approaching this from the other direction of exaggerating such a condition in a music piece so that it is easily audible & gradually reducing it down to the threshold of audibility. My first stab at this would be to use MATLAB to generate a signal dependent track of noise which fluctuates based on the music signal & add this noise track back into the music track at various amplitude to test audibility (a later refinement might be to look at changing the spectral makeup of the noise?)
Does anyone reckon this as a worthwhile first test? Is MATLAB the best approach or are the better ways of achieving this?
My thought is about approaching this from the other direction of exaggerating such a condition in a music piece so that it is easily audible & gradually reducing it down to the threshold of audibility. My first stab at this would be to use MATLAB to generate a signal dependent track of noise which fluctuates based on the music signal & add this noise track back into the music track at various amplitude to test audibility (a later refinement might be to look at changing the spectral makeup of the noise?)
Does anyone reckon this as a worthwhile first test? Is MATLAB the best approach or are the better ways of achieving this?
I'm don't remember, but think it might have been this thread:
An Objective Comparison of 3in - 4in Class Full Range Drivers
An Objective Comparison of 3in - 4in Class Full Range Drivers
FWIW, Diffmaker works very well as long as you keep the clips short. I stay under 30 seconds. It's also a big help to put in a maker near the beginning of the file. A few ms of silence followed by 2 cycles of 4410 Hz (or 1/10th the sample rate) followed by a short silence, is working for me.
Thanks for the link, Pano - I'll have a read
Yes those seem to the important criteria to ensure Diffmaker doesn't choke.
I'm also wondering about the clock drift correction - bill waslo mentioned that it handles upto 3 drifts - I wonder how it recognises a drift - a sample timing anomaly or what? Pity the software isn't open source to examine these aspects?
Yes those seem to the important criteria to ensure Diffmaker doesn't choke.
I'm also wondering about the clock drift correction - bill waslo mentioned that it handles upto 3 drifts - I wonder how it recognises a drift - a sample timing anomaly or what? Pity the software isn't open source to examine these aspects?
Thanks Pavel, Were you able to listen to the difference file after normalization? If so, what did you hear?
Hi Pano, after subtraction, there is a slow melody starting with a clarinet (?), small chamber orchestra and a flute starts about 20s. But when listening to "full" samples, this is impossible to tell, -80dB avg is inaudible below the main program. This is no surprise.
Hi Pano, did I answer your question, or were you asking anything else?
For info it looks REW "Import" menu can import audio data less than 87,4 seconds else it will be truncated, know its not the same as Diffmaker but importing two same audio data files one can use REW to look up their graphical differences use divide funchtion on "All SPL" tab.
- Status
- This old topic is closed. If you want to reopen this topic, contact a moderator using the "Report Post" button.
- Home
- General Interest
- Everything Else
- Low Level Detail: An experimental search and test.