Sure all questions about sighted listening can & are usually asked without the push back seen when questions are asked about ABX testing.Thank you for posting your analysis, George. I will post mine as well, but it is good to have yours as an independent one.
However, I do not think it is a technical point or real test parameters that are attacked. It is the ABX itself, by those who do not like the protocol. I understand it, but if I have a choice between technically well performed ABX and a sighted test, I would vote for the ABX. Further, where is the proof that the parameters like level equalization within 0.2dB were fulfilled in the sighted test? That would be my question to the oponnents.
Sorry but I disagree with your categorization of your ABX tests as "technically well performed" for the reasons already stated
As you know well, level difference is not only a result of "volume control setting", but it is however a quite complex result of frequency response and non-linearities as well. As a non-linearity in my DUT goes up to 1%, it affects the "level" as well, should it be a peak level, peak rms, avg rms and min/max rms. Please check the file stats I have shown in my previous post.
However, we still have a "null" ABX result, so we should not blame the result to a "poor" 0.2dB level matching.
You miss the point completely.
Thank you for posting your analysis, George. I will post mine as well, but it is good to have yours as an independent one.
You are welcome Pavel.
Note: Some differences in min, max RMS Power btn mine and Pavel’s statistics is due to a different setting of analysis settings. Pavel’s is at 50ms (Window Width), mine is at 1ms (Resolution). If I set mine to 50ms too, differences are at the second decimal point.
I’ve already said that the amp Pavel used does not change the dynamic range of the signal.
I have asked myself a relevant question though on this point.
When I am to arrange such a comparative test: In case one of the DUTs changes the dynamic range appreciably (>1-2dB), either due to increased noise floor or due to smooth compression of the high level peaks or both, what instrument reading should I use for to level equalize the two files (target is equal perceived level of loudness)?
Peak hold, VU peak, average RMS power?
George
Oh, I see. In a test setup itself, the level difference is verified to be in order of 0.01dB. Less than 0.1dB. Now, please tell me why you ask, if there has been no positive ABX protocol yet?.
I´m not sure to which event you are referring to?! In which context did i ask "why there has been no positive ABX protocol yet?" (you surely meant ABX result, don´t you?).
In case there are positive results, I understand there is a reason of being suspicious to the level difference only. I still have a strong feeling there is a reluctance to the ABX method itself, rather than to real technical issues. Seems to me as a substitute issue.
I´ve presented the results from various studies where different "blind test" protocols were compared. Did you miss these?
Results of these comparison (comparison means to present the same sensory difference to the test subjects and to look for differences in the results/correct answers) were always that the proportion of correct answers in the ABX tests was significantly lower than in the other tests (like A/ or 3AFC) .
That was already noted shortyl after the invention of the original ABX protocol in the 1950s. Tests by other experimenters found that (when testing pitch difference) the DL found was always lower in A/B tests than in ABX tests, which means that the sensitivity of the detectors (aka participants) was higher in A/B than in ABX.
In addition the test participants reported their subjective feeling of beeing more uncomfortable in the ABX tests.
So there exist hard scientific evidence for the fact that the ABX protocol indeed makes it more difficult for participants not only in listening test but in food tests as well.
That holds true for simple directional tests - like the pitch example i´ve mentioned - and it gets surely even more difficult in the case of multidimensional tests (aka listening for any difference/preference with music as stimulus).
Your next point needs a extra post....
")
A positive control is a difference (known to be detectable) presented within a test setup to check if everything works as intended.
So, the answer to your question is simple, use material where such difficulties does not exist; for example take the "wire sample" and use it to present the mentioned level difference as a positive control.
Hello Jakob, once again to this. I made a "wire test" against a "rip" (same music sample, but a little bit different length for the obvious reason - totally same sample would disclose which is which in my hybrid amp listening test). Please see that I was not kidding when speaking about level matching within 0.01dB order.
Attachments
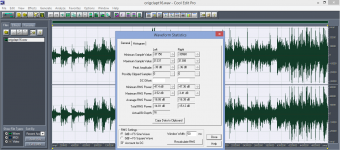
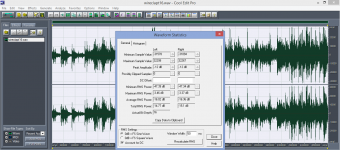
Hello Jakob, once again to this. I made a "wire test" against a "rip" (same music sample, but a little bit different length for the obvious reason - totally same sample would disclose which is which in my hybrid amp listening test). Please see that I was not kidding when speaking about level matching within 0.01dB order.
Again, you are completely blind (bias?) to what I & Jakob are saying.
I´m not sure to which event you are referring to?! In which context did i ask "why there has been no positive ABX protocol yet?" (you surely meant ABX result, don´t you?).
This one
Can you tell original file from tube amp record? - test
The test is described in the 1st post of the thread.
As a "protocol" I mean a protocol that is provided by an ABX Foobar plug-in (foo_abx 2.0.2 report). This protocol my be checked for validity here
foobar2000 ABX Log Signature Tool
An example of such protocol/report is my result
Can you tell original file from tube amp record? - test
Such report and the signature check makes at least some proof that the test was not cheated by file modification etc., as it is a long-distance test.
So you accept that what you claimed has not not been said 'on here' has been said 'on here'? Even if it had not been said before (which I doubt) it has now been said by you, and you were 'on here' when you said it.mmerrill99 said:Semantics, semantics - you know what I mean but choose to take a different meaning - I wonder should you be accused of "putting words in my mouth"?
Hhoyt has given you some evidence.Try me with some evidence rather than some spurious argument.
My bias is that I would take any reasonable unsighted test over any sighted test. There: my bias is out in the open for all to see. It seems to me that this is a common-sense position to take, given all the false positives which can easily be introduced into sighted tests.Of course there can be false positives in sighted listening, I stated that many times already but you fail to admit that ABX testing is prone to false negatives despite evidence & many here still use ABX test results (of any quality) to try to claim that a sighted listening report is a false positive. Fact of the matter is you are trying to elevate some unknown quality listening 'test' to a status that is unwarranted & unscientific & trying to use it to negate sighted listening
My bias is that a genuinely obvious difference will be heard in an ABX test; not necessarily by everyone, and not necessarily every time, but often enough (as shown by the statistics). Whether some other blind test will be better or worse at doing this is a separate issue. I make no claims about how 'scientific' ABX is; I merely believe that all sighted tests are 'unscientific' and some are merely marketing.
I make no claims about how 'scientific' ABX is; I merely believe that all sighted tests are 'unscientific' and some are merely marketing.
On this I agree completely, though it took my years (unfortunately) to come to the same conclusion.
<snip>
Now, to your test with black boxes. I have read your description carefully. Please tell me, you, who say that 16 attempts in ABX is not enough and you consider it statistically unimportant, how valid is your 5/5 result in a semi-sighted, semi-blind test as you have described.
First of all it wasn´t "semi-blind" or "semi-sighted" it was an A/B paired comparison preference test "double blind" .Neither did i know about the marking of the variants when handing them over, nor did the listener know which of the two DUTs they "had to prefer".
And during my own test we followed the same procedure....
Addressing your question for the statistical part unfortunately needs a short recap of some basics. (for simplicity i neglect all philosophical differences between NHST, Fisherian experiments and the Neyman/Pearson approach)
The null hypothesis is stated before (random guessing, H0: p = 0.5), so two different errors can be made when analysing the results of a listening experiments:
The null hypothesis could be rejected although it is true (so-called alpha error)
and
the null hypothesis could _not_ be rejected although it is _false_ (so-called beta error)
The guard against alpha errors is to choose a significance level that is sufficiently low; the usual SL = 0.05 means that in the long run the alpha error will be <= 5%.
So this required SL decides which minimum number of samples is needed.
Therefore 5 samples are sufficient (in a one-sided test) as the probability to get 5 hits in 5 trials is 0.032, which is below 0.05
The guard against beta errors is the statistical power (1- beta), so if you want to keep the beta error as low as the alpha error, you need a statistical power of (1-0.05) = 0.95.
The usual minimum required statistical power is 0.8, which means to accept a beta error of 0.2 , that is already 4 times higher as the alpha error.
To calculate the statisticial power you have to assume something about the difference under test conditions.
The calculations i´ve shown before therefore assumed p2 = 0.6 (instead of the p = 0.5 as assumed under the null hypothesis) .
I hope that helps to understand why the requirements for low alpha and low beta errors are different.
And i hope it shows why training under the specific test conditions helps, because it might (if a difference is detectable) the proportion of correct answers and therefore lowers the number of samples required.
Last edited:
Wow, is this not a perfect example of pedantry? What are you trying to prove with this?So you accept that what you claimed has not not been said 'on here' has been said 'on here'? Even if it had not been said before (which I doubt) it has now been said by you, and you were 'on here' when you said it.
I asked him for the details of this - do you have the details?Hhoyt has given you some evidence.
I know what your bias is - you will accept any test results even if all are false negatives, as long as it supports your worldview. Your failure to accept that ABX testing, in particular, is skewed towards false negatives is a perfect example of your bia sin this matter. If you understood statistics you would see this but you don't need to be able to understand statistics to see that Jakob2's evidence & the use of internal controls is a crucially necessary factor in ABX testingMy bias is that I would take any reasonable unsighted test over any sighted test. There: my bias is out in the open for all to see. It seems to me that this is a common-sense position to take, given all the false positives which can easily be introduced into sighted tests.
Yes, that your bias is based on your beliefs is very obvious. And, indeed ABX tests, as seen on audio forums, are performance art & pseudo-scienceMy bias is that a genuinely obvious difference will be heard in an ABX test; not necessarily by everyone, and not necessarily every time, but often enough (as shown by the statistics). Whether some other blind test will be better or worse at doing this is a separate issue. I make no claims about how 'scientific' ABX is; I merely believe that all sighted tests are 'unscientific' and some are merely marketing.
Excellent execution of the social justice warrior's 5 Step protocol, I would have expected no less, congratulations, full marksI know what your bias is - you will accept any test results even if all are false negatives, as long as it supports your worldview. Your failure to accept that ABX testing, in particular, is skewed towards false negatives is a perfect example of your bia sin this matter. If you understood statistics you would see this but you don't need to be able to understand statistics to see that Jakob2's evidence & the use of internal controls is a crucially necessary factor in ABX testing
I’ve already said that the amp Pavel used does not change the dynamic range of the signal.
I have asked myself a relevant question though on this point.
When I am to arrange such a comparative test: In case one of the DUTs changes the dynamic range appreciably (>1-2dB), either due to increased noise floor or due to smooth compression of the high level peaks or both, what instrument reading should I use for to level equalize the two files (target is equal perceived level of loudness)?
Peak hold, VU peak, average RMS power?
George
I think you hit the point, George - the amp should not change the dynamics of the recording and also should not audibly increase the noise level of the recording.
And you are asking a good question - unfortunately I am not able to give you similarly good answer
.So how do you judge what is "any reasonable unsighted test"?...
My bias is that I would take any reasonable unsighted test over any sighted test. There: my bias is out in the open for all to see. It seems to me that this is a common-sense position to take, given all the false positives which can easily be introduced into sighted tests..
You are surely not trying to tell me that money could corrupt a technical discussion? After all, we have been assured that people can overcome their bias in sighted tests. Someone who can overcome sight/knowledge bias and simply report what their ears hear should surely have enough self-control to overcome any financial bias too?scottjoplin said:The marketing men will never give up trying to persuade you otherwise, it's their job
I am merely demonstrating that that which was alleged to be 'not said' 'on here' has now been said 'on here' by you at least. I strongly suspect it has been said in the past too, either by you or others with a similar view to you. You were talking as though this forum has a uniform view; it does not. On the basis that if something is not impossible then it is inevitable (if you wait long enough) then it is highly likely that almost every possible view on audio has been expressed by someone on this site at some point in the recent past. Hence it seems rather silly to claim that a particular view has not been said, as though that sums up everyone here.mmerrill99 said:Wow, is this not a perfect example of pedantry? What are you trying to prove with this?
I am not aware that I have 'accepted' any test results, although I may have given some more credence than others. I genuinely don't know what would satisfy you, apart from an agreement to accept everything you assert on all subjects.I know what your bias is - you will accept any test results even if all are false negatives, as long as it supports your worldview.
Everyone has a worldview; everyone tends to reject anything which conflicts with that worldview, so I am happy to admit that I am a fairly normal person. Those who think that they are different from this are merely better at fooling themselves.
Everyone's bias is based on their beliefs. You should be pleased that in my case this is obvious. Obvious bias is easier to deal with.Yes, that your bias is based on your beliefs is very obvious.
And sighted tests are not?And, indeed ABX tests, as seen on audio forums, are performance art & pseudo-science
I will show another piece of bias: I suspect that your position is at least partly motivated by a commercial interest in audio. What form that takes I don't know, but my experience is that dogged persistance (and faith in sighted tests) is often a sign of commercial interest. My experience is also that people with a commercial interest are often reluctant to say so, until one day it spills out when they use commercial success bragging in lieu of reasoned argument.
I only added the "reasonable" adjective to avoid being accused of accepting any old junk as evidence.So how do you judge what is "any reasonable unsighted test"?
Last edited:
@DF96, your pedantry is getting tedious for everybody, I suspect so I'l keep it short?
It's not a 'competition', just a debate on various flaws in listening tests
So you proffer no definition of what is a "reasonable" unsighted test to you - you simply "added the "reasonable" adjective to avoid being accused of accepting any old junk as evidence." So tell us how you know the unsighted test isn't just comprising of false negative results or are you not concerned about that, only wishing to minimize false positives?
It's not a 'competition', just a debate on various flaws in listening tests
So you proffer no definition of what is a "reasonable" unsighted test to you - you simply "added the "reasonable" adjective to avoid being accused of accepting any old junk as evidence." So tell us how you know the unsighted test isn't just comprising of false negative results or are you not concerned about that, only wishing to minimize false positives?
- Status
- Not open for further replies.
- Home
- Member Areas
- The Lounge
- John Curl's Blowtorch preamplifier part III