Hi pnix, if you have a couple of hours to spare,
It's all in here:
http://www.diyaudio.com/forums/full-range/242171-making-two-towers-25-driver-full-range-line-array.html
It wasn't exactly a one day job") . I grew into the correction, sort of. Pretty much described the entire journey with plots and measurements. The first post has some shortcuts to the important subjects. But it is quite a long thread to go trough. My excuses .
. I grew into the correction, sort of. Pretty much described the entire journey with plots and measurements. The first post has some shortcuts to the important subjects. But it is quite a long thread to go trough. My excuses .
It's all in here:
http://www.diyaudio.com/forums/full-range/242171-making-two-towers-25-driver-full-range-line-array.html
It wasn't exactly a one day job
. I grew into the correction, sort of. Pretty much described the entire journey with plots and measurements. The first post has some shortcuts to the important subjects. But it is quite a long thread to go trough. My excuses .Wesayso,
One question about your line array design. What made you choose the straight vertical line array over a curved array, was that purely a space consideration or did you have something else in mind. Perhaps a curved array would have just been a pita as far as building the enclosure, just curious.
One question about your line array design. What made you choose the straight vertical line array over a curved array, was that purely a space consideration or did you have something else in mind. Perhaps a curved array would have just been a pita as far as building the enclosure, just curious.
Maybe it's jus me that is curious but this thread and the linked papers keeps intriguing me. I'd like to learn more about the views of the APL_TDA software.
I've asked jim1961 to run the demo, out of curiosity of 2 things. He started a thread about the audibility of group delay a while ago: http://www.diyaudio.com/forums/full-range/273971-group-delay-questions-analysis.html
His room is not quite standard, it is modelled after studio control rooms with a combination of absorption and diffusion to do what he wants it to do. A huge effort to optimise his listening room, for the main purpose of listening pleasure.
He uses a multi way speakers with second order crossovers and reflex subs to augment the low frequencies. All room effects directly after the main pulse are down by at least 20 dB or more by clever routing of that energy. There is a Haas Kicker at ~24 ms for psychoacoustic reasons. Carefully placed and timed with panels in the room.
The 2 things I was curious about:
1) Did he achieve his goal of the lowest group delay for his type of speaker with sub support? No digital processing here to correct any of it. Passively corrected speakers with sub support. This part is separate from the discussion in this thread. It was merely a question I had to see if what we tried to accomplish at that time had succeeded.
2) How would his room show up in this APL_TDA software. It's the best example of room treatment that I've personally had the pleasure of seeing and browsing trough the actual measured plots. This was to satisfy my own curiosity, to see what APL_TDA results looks like in that marvellous room.
His plot looks like this:
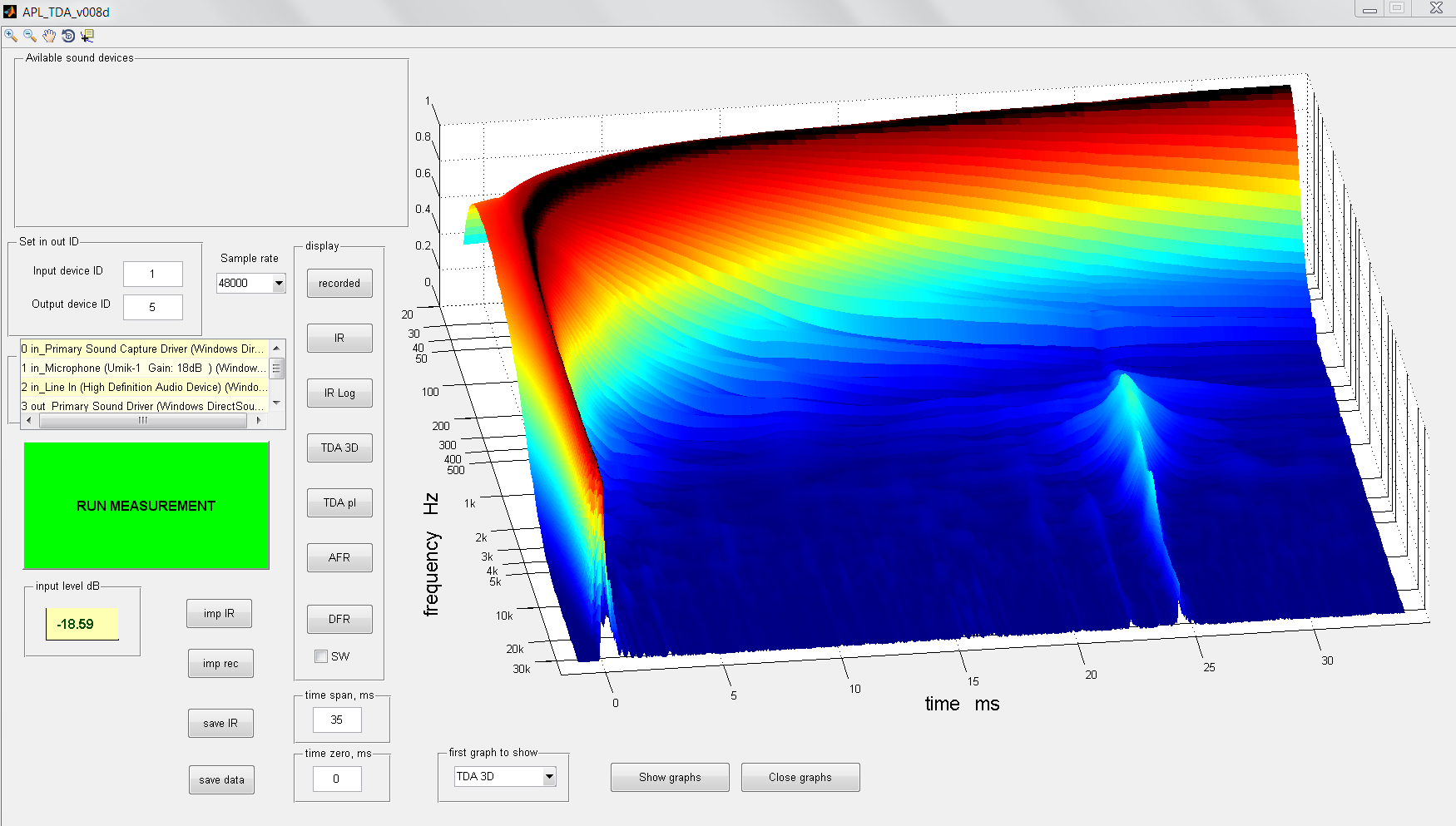
If I lay that next to my plot:

It becomes clearer to see his room is way cleaner than mine. My room barely has treatments compared to his. Obviously my crossover-less sealed speakers have less time delay, helped out by my specific FIR processing.
Other types of wavelet have been mentioned, for instance the result of Audiovero's STransform. It uses the S Transform to give a more accurate wavelet view. But one that obviously differs from APL_TDA's way of presenting data. Here's an example from Mitch:
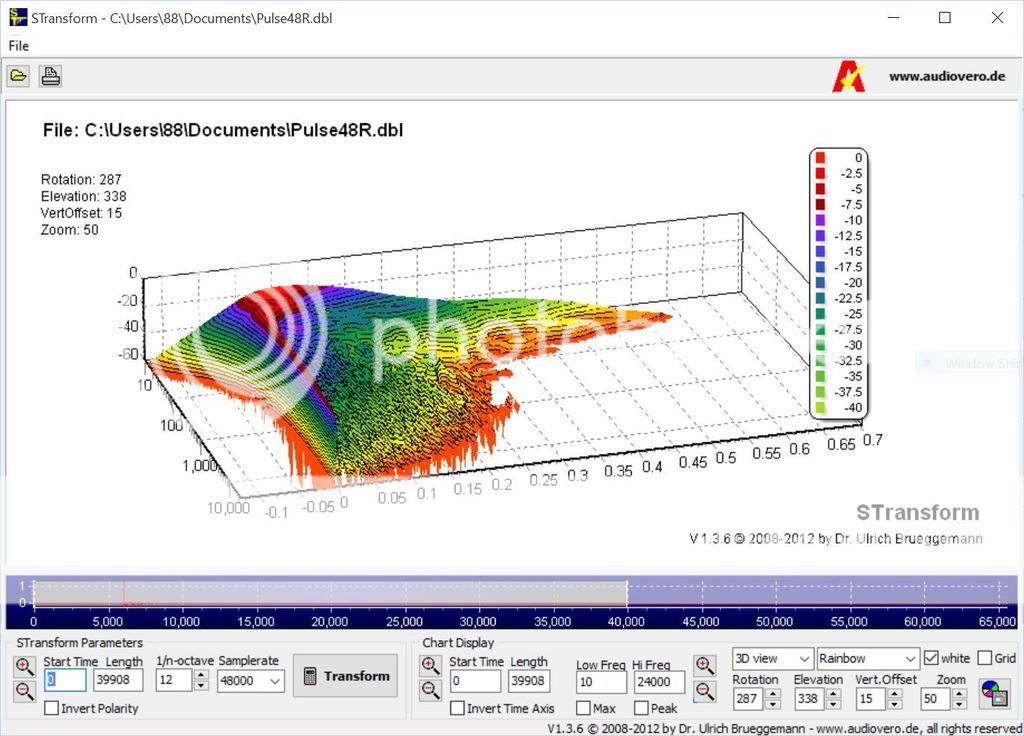
To me, the above S Transform graph seems to show time vs output vs frequency. In comparison the APL_TDA graph seems to apply a weighting to the time/energy presentation. (apart from the normalisation applied in the TDA graph)
Is this weighting based on an interpretation on how we perceive sound? I think that would be my question. Am I right there is weighting involved. Does this make enough sense to get an answer?
I've asked jim1961 to run the demo, out of curiosity of 2 things. He started a thread about the audibility of group delay a while ago: http://www.diyaudio.com/forums/full-range/273971-group-delay-questions-analysis.html
His room is not quite standard, it is modelled after studio control rooms with a combination of absorption and diffusion to do what he wants it to do. A huge effort to optimise his listening room, for the main purpose of listening pleasure.
He uses a multi way speakers with second order crossovers and reflex subs to augment the low frequencies. All room effects directly after the main pulse are down by at least 20 dB or more by clever routing of that energy. There is a Haas Kicker at ~24 ms for psychoacoustic reasons. Carefully placed and timed with panels in the room.
The 2 things I was curious about:
1) Did he achieve his goal of the lowest group delay for his type of speaker with sub support? No digital processing here to correct any of it. Passively corrected speakers with sub support. This part is separate from the discussion in this thread. It was merely a question I had to see if what we tried to accomplish at that time had succeeded.
2) How would his room show up in this APL_TDA software. It's the best example of room treatment that I've personally had the pleasure of seeing and browsing trough the actual measured plots. This was to satisfy my own curiosity, to see what APL_TDA results looks like in that marvellous room.
His plot looks like this:
If I lay that next to my plot:
It becomes clearer to see his room is way cleaner than mine. My room barely has treatments compared to his. Obviously my crossover-less sealed speakers have less time delay, helped out by my specific FIR processing.
Other types of wavelet have been mentioned, for instance the result of Audiovero's STransform. It uses the S Transform to give a more accurate wavelet view. But one that obviously differs from APL_TDA's way of presenting data. Here's an example from Mitch:
To me, the above S Transform graph seems to show time vs output vs frequency. In comparison the APL_TDA graph seems to apply a weighting to the time/energy presentation. (apart from the normalisation applied in the TDA graph)
Is this weighting based on an interpretation on how we perceive sound? I think that would be my question. Am I right there is weighting involved. Does this make enough sense to get an answer?
Last edited:
you can make the s-transform output look more like the APL one by adjusting the start and end time of the window relative to the impulse. This and the difference in scales + rendering engine (the s-transform one is not as pretty as the APL one) could easily account for the visible differences.To me, the above S Transform graph seems to show time vs output vs frequency. In comparison the APL_TDA graph seems to apply a weighting to the time/energy presentation. (apart from the normalisation applied in the TDA graph)
I'm not sure what the acourate dbl format is exactly (I would guess it's the impulse as raw 64bit doubles but am not sure about that) but if you want to see that impulse in s-transform then I can convert it for you (if you stick the file somewhere I can grab it).
It's not how the graphs look different that I'm curious about. It's why is the TDA graph presented this way that peaks my curiosity. Did you read the paper from Raimonds Skuruls? On page 7 of that paper he goes into depth about the difference between his method of measuring and the more widely used FFT approach. All in search of more resolution in the time domain.
The STransform program from Audiovero will probably be altered by Dr. Dr. Ulrich Brüggemann to also be able to read plain wav files on request from Mitch. So that would cover that part without the need for conversion of formats.
So my question still stands.
The STransform program from Audiovero will probably be altered by Dr. Dr. Ulrich Brüggemann to also be able to read plain wav files on request from Mitch. So that would cover that part without the need for conversion of formats.
So my question still stands.
I don't see what is different about this view tbh, what do you see that is actually different?It's not how the graphs look different that I'm curious about. It's why is the TDA graph presented this way that peaks my curiosity.
I read the paper, it is quite light on detail so it's hard to judge how it compares. This is why I suggested comparing the same impulse in both packages to see if you can see any substantial difference.Did you read the paper from Raimonds Skuruls? On page 7 of that paper he goes into depth about the difference between his method of measuring and the more widely used FFT approach. All in search of more resolution in the time domain.
I don't see what is different about this view tbh, what do you see that is actually different?
The choices made to present it this way. That was the original question. I don't have the impulse available that created the APL_TDA plot. It's a demo version of the program with limited function. But also not the point of my question. I don't see anything wrong with the Audiovero plot. Although I do not use Acourate myself it does have my interest as well as the other non free tools like Audiolense.
But this thread is about APL_TDA, and we are joined by the author of that program so I figured I'd ask about the reasons/choices of presenting the plot the way he does. I'm intrigued and it was a fun exercise to run that demo.
I'm not disappointed with my results, quite the opposite in fact, just trying to learn something. Trying to be open minded about the different method used by APL_TDA. So why not ask questions, right?
We may well be talking at cross purposes here I'm not saying don't ask questions or that one is better than the other.
My point was that we have 3 different implementations of a heatmap type view (s-transform, whatever APL is doing, REW wavelet transform) and we don't have detailed implementation details. Hence one way to learn about them is to prod the same data into them and compare and contrast the results.
I'm not saying don't ask questions or that one is better than the other. My point was that we have 3 different implementations of a heatmap type view (s-transform, whatever APL is doing, REW wavelet transform) and we don't have detailed implementation details. Hence one way to learn about them is to prod the same data into them and compare and contrast the results.
Raymonds said:The idea that pre distortions introduced into loudspeaker’s performance will be eliminated (compensated, neutralized) by room distortions is utopia and incorrect.
We should have uncolored loudspeaker to be able to create uncolored acoustic image.
Hi Raymonds,
this is speaking "from my heart and mind".
At least above around 400Hz there is no such thing like "auditively valid room correction" (by superposition of modified direct and reflected sound measured in a spot using an omnidirectional microphone at wavelenghs <80cm ? Too sad to laugh out loud ...)
So above "lower midrange" all DSP can do in a useful manner is "speaker correction", when done right and adressing things which "should be corrected".
Most important is still to leave hands from things that should not be corrected or "overcorrected".
But all that should not be an end-users business anyway, if the speaker designer and manufacturer did their jobs well ...
Above midrange such modifications are not "room correction". That notion of room correction IMO is a kind of religion with some known rituals followed by individuals having very little understanding of room acoustics, binaural hearing etc.
Especially "grown up" german listeners using known german speaker brands (active, controlled) are easy victims for this religion and we have some forums specialized in "digital esoterics and religion" round here.
(Time to look for the crossbow, the wooden plugs and the silver bullets ... if you meet some of them
)At LF things are different, but DSP cannot heal anything even there ...
You need dedicated woofer systems interfacing to the room in a certain way to get the real advantage from DSP IMO.
Cheers !
Last edited:
Most people that tried Dirac Live full range room correction like it. For certain hearing processes full range correction might lead to better results. The old mantra "you can't improve reproduction by correcting the steady-state response because it will distort the direct sound" might not be universally applicable.
The physical properties of our hearing suggest that it is a data reduction device (see Schnupp, "Auditory Neuroscience"). This might be key to define areas where reproduction can take short cuts and where it can't.
The physical properties of our hearing suggest that it is a data reduction device (see Schnupp, "Auditory Neuroscience"). This might be key to define areas where reproduction can take short cuts and where it can't.
pnix said:The old mantra "you can't improve reproduction by correcting the steady-state response because it will distort the direct sound" might not be universally applicable.
Hi,
as i wrote, it depends on the frequency range (wavelength range) we are talking about.
In the frequency range, where the mirror sources' distances from the speaker in a room exceed the wavelengths under question, you need to be a true "listening masochist" when "correcting" a speaker's energy response by "correcting" on axis too: You can't "correct on axis" for "off axis faults" in the mid to high range.
Most experienced loudspeaker designers will tell you this and they are simply right in doing so IMO ... (*)
What is needed is an adjustable DI curve of a loudspeaker, allowing for modification of the midrange to hirange energy response - to better match an actual listening room where the speaker is placed in - without virtually touching the on axis response of the speaker, which should be/stay reasonably flat and smooth.
This will solve or at least mitigate a loudspeaker/room "mismatch" at mid to higher frequencies in a causal manner, when done in an intelligent way (**).
Everything else is just "dancing around the fire" with no solution at hand regarding this issue ...
Kind Regards
_______________
(*) Another solutions with "room correction" above lower midrange: Let only your customers listen to it and avoid listening by yourself strictly ...
(**) I am in a position luckily to deliver such solutions in my customer's projects, so i not only do know what i am talking about here, i also provide a practical and proven solution, being effective at the cause of the problem:
Finally you get a speaker having a DI curve matching closely to your setting in your room.
Last edited:
LineArray, looks to me you pretty much say this stuff cannot work.
I kindly disagree with that point of view. But I correct my speaker response, way more than I want to touch on room correction, not by accident but by intent.
That means you've got to use short frequency dependant correction windows and a lot of control measurements.
As to the on axis correcting having an effect on the off axis response. Of coarse it does. But what made you think that off axis response you mention was that correct without any on axis correction?
I suppose you don't want to correct a speaker with gross off axis errors to begin with. But isn't it wise then to not use a speaker that has gross off axis errors at all?
I'll keep on dancing around the fire. To my corrected speakers playing music.
There's more than one way to skin a cat. Don't lump all solutions on one big pile and judge it. Read Raimonds paper if you will, it might clear up a thing or two.
If it's not for you? Fine, no harm there. But do you know what it is Raimonds is suggesting we use? Did you read about his EQ solution? A correction that is using more than one point in the room?
Still it's funny to me how people react to that one point measurement. I thought the same a while back. That was until I decided to try that correction. Use it and measure all areas of interest and compare. Came as a shock, it worked. But it works a bit different from what you are suggesting it does.
I kindly disagree with that point of view. But I correct my speaker response, way more than I want to touch on room correction, not by accident but by intent.
That means you've got to use short frequency dependant correction windows and a lot of control measurements.
As to the on axis correcting having an effect on the off axis response. Of coarse it does. But what made you think that off axis response you mention was that correct without any on axis correction?
I suppose you don't want to correct a speaker with gross off axis errors to begin with. But isn't it wise then to not use a speaker that has gross off axis errors at all?
I'll keep on dancing around the fire
. To my corrected speakers playing music.There's more than one way to skin a cat. Don't lump all solutions on one big pile and judge it. Read Raimonds paper if you will, it might clear up a thing or two.
If it's not for you? Fine, no harm there. But do you know what it is Raimonds is suggesting we use? Did you read about his EQ solution? A correction that is using more than one point in the room?
Still it's funny to me how people react to that one point measurement. I thought the same a while back. That was until I decided to try that correction. Use it and measure all areas of interest and compare. Came as a shock, it worked. But it works a bit different from what you are suggesting it does.
Last edited:
You can't "correct on axis" for "off axis faults" in the mid to high range.
I just presented you with anecdotal evidence that this might not be true. This is certainly something that should be investigated even if it's against your beliefs. That's the difference between science and religion.
LineArray, looks to me you pretty much say this stuff cannot work.
I wrote specifically, in which context and frequency range "it doesn't work" (*), that surely makes a difference.
Causal solutions are needed in this field, which can come from
- room treatment / speaker and listener placement
and/or
- loudspeaker design in modifying DI curve and dispersion pattern while maintaining flat on axis response
but as we know: Most listeners have very limited ambitions in room treatment for many reasons.
So "let's face the music" guys ...
___________________
(*) namely mid to high frequencies, wavelength shorter than speaker's distances to the room's walls
Last edited:
- Home
- Loudspeakers
- Full Range
- The room correction or speaker correction? What can we do with dsp power now availabl