I think this shows that the subjective noise level depends on the probability distribution as well as on the RMS value. That's actually why the ITU-R 468 standard prescribes a quasi-peak detector rather than an RMS detector. It also means that we're not going to find out anything about the audibility of the higher-order moments this way, because I don't know how to subjectively level match the noise.
In any case, you didn't complain about distortion, so apparently the dithered quantization error sounded like noise to you for both cases.
Thanks for participating!
- I agree with your comments re subjective noise level dependence on probability distribution
- I did no complain about distortion specifically but I did complain about overall file sound qualities (defined it as "defective" and asked you if you checked sound quality of the samples), so it depends if distortion is meant as non-linear distortion only or the meaning of the term distortion is more complex. If the later is considered, then I definitely complained.
- Thanks for the test!
I didn't so much notice a difference in noise level, more a difference in the makeup of the noise. Silvery7 seems more 'granular', not as smooth for want of a better word.
That gives me an idea for a new test: triangular PDF and quantization versus pure additive noise made of the sum of three uniformly distributed noise signals. To be continued!
I put two new files on WeTransfer, with the same music fragment, but now with 6.02 dB less noise:
WeTransfer
One file is rounded to 8 bits with triangular dither, the other is a floating point file with additive noise. The RMS levels of the quantization+dither noise and the additive noise match within 0.01 dB, the peak levels within 0.09 dB.
Again, please do an ABX test if you think you hear or might hear a difference and report the results of all such trials.
WeTransfer
One file is rounded to 8 bits with triangular dither, the other is a floating point file with additive noise. The RMS levels of the quantization+dither noise and the additive noise match within 0.01 dB, the peak levels within 0.09 dB.
Again, please do an ABX test if you think you hear or might hear a difference and report the results of all such trials.
What is the goal of these tests with super noisy and highly distorted files? (the "holiday" word, just to pick up one example, is unlistenable). Are you working on some new compression algorithm as a professional? Shall we expect 8-bit or 4-bit music in future? The current practices in consumer music mastering tend to admit that.
I am a professional electronics engineer, but my work generally has little to do with audio and besides, at work I'm not allowed anywhere near anything digital. I certainly don't work on audio compression algorithms.
In fact I'm just curious to know whether the assumption that the total error of a dithered quantizer is indistinguishable from additive noise is correct. I could make the dither+quantization noise much weaker for the test, but that doesn't seem to make sense as it is the noise that interests me.
By the way, I used a fragment from an unprocessed live recording from an amateur chorus. I don't think the recording is distorted, sometimes some of them just sing off key.
In fact I'm just curious to know whether the assumption that the total error of a dithered quantizer is indistinguishable from additive noise is correct. I could make the dither+quantization noise much weaker for the test, but that doesn't seem to make sense as it is the noise that interests me.
By the way, I used a fragment from an unprocessed live recording from an amateur chorus. I don't think the recording is distorted, sometimes some of them just sing off key.
The quanization error is white noise, if the audio signal is clearly above the noise level.
You can test this simply by doing a FFT plot. White noise is independent of frequency.
Up to now i have assumed that additive dithering noise should be equally distributed
in the interval [-LSB, +LSB] (or maybe somewhat less, but a range of 1 LSB is not enough).
Why do you use a triangular distribution?
Do you have a script doing the 11'th order dithering to play with?
You can test this simply by doing a FFT plot. White noise is independent of frequency.
Up to now i have assumed that additive dithering noise should be equally distributed
in the interval [-LSB, +LSB] (or maybe somewhat less, but a range of 1 LSB is not enough).
Why do you use a triangular distribution?
Do you have a script doing the 11'th order dithering to play with?
The quanization error is white noise, if the audio signal is clearly above the noise level.
This is the old theory of Bennett, that only holds when there is no rational relation between signal frequencies and sample rate.
You can test this simply by doing a FFT plot. White noise is independent of frequency.
Try it with a soft digitally generated sine wave of which the frequency has a simple rational relation to the sample rate and you will see completely messed up spectra. For example, a 1 kHz sine wave of a few LSB peak-peak at 44.1 kHz sample rate will give you distortion products at all multiples of 100 Hz, 100 Hz being the greatest common divisor of 1 kHz and 44.1 kHz.
Up to now i have assumed that additive dithering noise should be equally distributed in the interval [-LSB, +LSB] (or maybe somewhat less, but a range of 1 LSB is not enough).
Why do you use a triangular distribution?
Do you have a script doing the 11'th order dithering to play with?
Uniformly distributed dither from -0.5 LSB to +0.5 LSB makes the mathematical expectation (ensemble average) of the error independent from the signal, which eliminates the distortion peaks in the spectrum, but you still have modulation of the RMS level of the noise by the signal. With triangular noise from -1 LSB to +1 LSB, you also get rid of that.
I use a simple expression in GoldWave for the dither:
Triangular:
wave
") +rnd(1/y)+rnd(1/y)-1/y with y = 128 for 8 bits, 32768 for 16 bits
+rnd(1/y)+rnd(1/y)-1/y with y = 128 for 8 bits, 32768 for 16 bits11th order:
wave
+rnd(1/y)+rnd(1/y)+rnd(1/y)+rnd(1/y)+rnd(1/y)+rnd(1/y)+rnd(1/y)+rnd(1/y)+rnd(1/y)+rnd(1/y)+rnd(1/y)-5.5/yTo get a signal rounded to 7 bits, I half it, apply 8-bits dither, save it as an 8-bits file, close it, open it again, multiply everything by two and save it again.
I am familiar with TPD dither and various noise shaping dithers, but did not know the 11th order dither.
BTW, I am sure that you know that your 8bit sample from your latest noise added test has seemingly 50% DC offset, at 128th amplitude level, half of the 8bit scale. Is it OK? Probably yes, just only sample value convention for 8bits?
BTW, I am sure that you know that your 8bit sample from your latest noise added test has seemingly 50% DC offset, at 128th amplitude level, half of the 8bit scale. Is it OK? Probably yes, just only sample value convention for 8bits?
Last edited:
Marcel, BTW, I have played a bit with your 8bit file, would you mind to listen to the result?
http://pmacura.cz/silverysea8bitnr.zip
The original recording might have been quite nice.
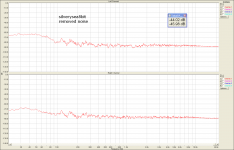
Edit: attached is the removed noise spectrum
http://pmacura.cz/silverysea8bitnr.zip
The original recording might have been quite nice.
Edit: attached is the removed noise spectrum
Attachments
Last edited:
It sounds OK until the women start singing, then you hear all the artefacts of the noise removing algorithm.
To satisfy your curiosity, I've put the recording without extra noise or requantization here:
WeTransfer
To satisfy your curiosity, I've put the recording without extra noise or requantization here:
WeTransfer
I am familiar with TPD dither and various noise shaping dithers, but did not know the 11th order dither.
BTW, I am sure that you know that your 8bit sample from your latest noise added test has seemingly 50% DC offset, at 128th amplitude level, half of the 8bit scale. Is it OK? Probably yes, just only sample value convention for 8bits?
The 8-bit formats supported by GoldWave are unsigned while the other formats are signed, so I think that explains the offset.
When you read the articles about non-subtractive dither, like
Robert A. Wannamaker, Stanley P. Lipshitz, John Vanderkooy and J. Nelson Wright, "A theory of nonsubtractive dither", IEEE Transactions on Signal Processing, vol. 48, no. 2, February 2000, pages 499...516
Stanley P. Lipshitz, Robert A. Wannamaker and John Vanderkooy, "Quantization and dither: a theoretical survey", Journal of the Audio Engineering Society, vol. 40, no. 5, May 1992, pages 355...375
it is explained that by using the sum of N uniformly distributed signals of 1 LSB peak-to-peak each as dither, you can make the first N moments of the error caused by dither and quantization independent of the signal. Usually one assumes that the first two moments (ensemble average and variance) are enough. When you add two uniformly distributed random signals of 1 LSB peak-peak you end up with 2 LSB peak-peak triangular dither.
I agree with you that the quantization error is not white noise. But the standard software usually uses to generate sine wave has some odd character(you may say it has a bug). 1kHz sinewave generated by this has the quantization noise of multiples of 100Hz as you wrote. This is because of the greatest common divisor between 1kHz and 44.1kHz. It's also true.
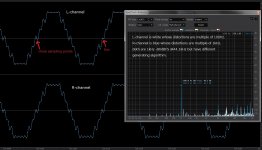
But I found this was an algorism oriented issue. Another algorism can have distortions of multiples of 1kHz like the attached. The standard software probably took the easy way to generate various sinewave. 1kHz sampled by 44.1kHz has 44.1 sampling points in one period. But a fraction can't be used. Then it used 100Hz to generate 1kHz; nine 44 sampling points and one 45 sampling point(44*9+45=441!). That's why it generates multiples of 100Hz instead 1kHz. The fundamental is not 1kHz but 100Hz. I think you can theoretically have multiples of 1kHz like R-channel.This is more preferable.
This is a very interesting thing for me. But few people think so. I guess you can enjoy the story.
But I found this was an algorism oriented issue. Another algorism can have distortions of multiples of 1kHz like the attached. The standard software probably took the easy way to generate various sinewave. 1kHz sampled by 44.1kHz has 44.1 sampling points in one period. But a fraction can't be used. Then it used 100Hz to generate 1kHz; nine 44 sampling points and one 45 sampling point(44*9+45=441!). That's why it generates multiples of 100Hz instead 1kHz. The fundamental is not 1kHz but 100Hz. I think you can theoretically have multiples of 1kHz like R-channel.This is more preferable.
This is a very interesting thing for me. But few people think so. I guess you can enjoy the story.
Attachments
Wow! You've just shown that you can hear the difference between a dithered quantizer with triangular PDF dither and real additive noise, even when the RMS value, peak value and probability distribution of the additive noise are made as similar as possible to that of a dithered quantizer with triangular PDF dither!
What did the difference sound like to you?
What did the difference sound like to you?
The difference was quite noticeable to me. If I could liken the second sample to placing a gramophone stylus in a plain groove, then that is how it came across. There was a different audible component to that track, more sort of midrange (in frequency) grungy noise. Quite pervasive and noticeable.
- Status
- This old topic is closed. If you want to reopen this topic, contact a moderator using the "Report Post" button.
- Home
- General Interest
- Everything Else
- High-order dither listening test