Human hearing is 130 dB from lowest intensity to threshold of pain, which for sound intensity is ten trillion to one. For voltage, however, 100 dB is somewhat over three million.
A 24 bit digital system has 16.7 million levels of quantization, and they are equal. So you get 16.7 million different voltage levels. I fail to see how that can cover the 1:10 trillion dynamic range of human hearing. Since the quantization is made of even differences between consecutive binary digits and not weighted, the quietest level you can represent is only at 16.7 million times lower voltage than the loudest. How can that be sufficient?
???
A 24 bit digital system has 16.7 million levels of quantization, and they are equal. So you get 16.7 million different voltage levels. I fail to see how that can cover the 1:10 trillion dynamic range of human hearing. Since the quantization is made of even differences between consecutive binary digits and not weighted, the quietest level you can represent is only at 16.7 million times lower voltage than the loudest. How can that be sufficient?
???
Hi,
Normal domestic listening levels do not exceed say ~ 100dB,
and ambient background level is always above say ~ 35dB.
🙂/sreten.
Normal domestic listening levels do not exceed say ~ 100dB,
and ambient background level is always above say ~ 35dB.
🙂/sreten.
We can represent 2^24 discrete levels which is 144.5 dB in voltage, but 72 dB in power ratio. The background noise in a very quiet listening room is say 35 dB as sreten remarked, so we can reproduce up to 107 dB range above the hearing threshold. The hearing threashold is considered as 20 uPa (0 dB). An average lodspeaker has 93 dB/1W/1m efficiency. It can produce 113 dB for 100 W drive at 1 meter, and 107 dB at 4 meters, which is extremely loud. I found some typical sound pressure levels at Wikipedia:
http://en.wikipedia.org/wiki/Sound_pressure_level
More interesting is how the 48 dB power dynamic range of the 16-bit DC audio can be sufficient.
http://en.wikipedia.org/wiki/Sound_pressure_level
More interesting is how the 48 dB power dynamic range of the 16-bit DC audio can be sufficient.
oshifis said:We can represent 2^24 discrete levels which is 144.5 dB in voltage, but 72 dB in power ratio. The background noise in a very quiet listening room is say 35 dB as sreten remarked, so we can reproduce up to 107 dB range above the hearing threshold. The hearing threashold is considered as 20 uPa (0 dB). An average lodspeaker has 93 dB/1W/1m efficiency. It can produce 113 dB for 100 W drive at 1 meter, and 107 dB at 4 meters, which is extremely loud. I found some typical sound pressure levels at Wikipedia:
http://en.wikipedia.org/wiki/Sound_pressure_level
More interesting is how the 48 dB power dynamic range of the 16-bit DC audio can be sufficient.
Hi,
You have your voltages and powers the wrong way round.
16 bit = 48dB voltage and 96dB power = signal to noise ratio.
One reason vinyl sounds good is 70dB power range is adequate.
🙂/sreten.
You guys have your math mixed up. dB in voltage is the same dB in power, or more accurately, the measure of dB is always a scale relative to power!
The decibel scale is defined as:
dB = 10 log(Watts)
When calculating using voltage you use the relationship
P = VxV/R --> V squared divided by R
mix the two equations together and
dB = 10 log(VxV/R)
now log (VxV) = 2 log(V) so you can simplify to
dB = 20 log (V/R)
since for the load R is gnerally a constant value, you can simplify to
dB = 20 log (V)
But this scale is still relating to power.
Now, with that confusion sorted out, lets look at the original post. Crowbars confusion comes from the incorrect statement that 130dB equals a range of 10 trillion discrete voltage levels. Using our equations from above,
V = 10 exp (130dB / 20) = 3.16 Million voltage levels.
Crowbars next statement that 24 bit = 16.7 Million levels is correct.
For reference:
21 bit = 2.10 Million = 126.4dB
22 bit = 4.19 Million = 132.5dB
and
10 Trillion = 260dB = 44 bit
Hope this helps.
Terry
The decibel scale is defined as:
dB = 10 log(Watts)
When calculating using voltage you use the relationship
P = VxV/R --> V squared divided by R
mix the two equations together and
dB = 10 log(VxV/R)
now log (VxV) = 2 log(V) so you can simplify to
dB = 20 log (V/R)
since for the load R is gnerally a constant value, you can simplify to
dB = 20 log (V)
But this scale is still relating to power.
Now, with that confusion sorted out, lets look at the original post. Crowbars confusion comes from the incorrect statement that 130dB equals a range of 10 trillion discrete voltage levels. Using our equations from above,
V = 10 exp (130dB / 20) = 3.16 Million voltage levels.
Crowbars next statement that 24 bit = 16.7 Million levels is correct.
For reference:
21 bit = 2.10 Million = 126.4dB
22 bit = 4.19 Million = 132.5dB
and
10 Trillion = 260dB = 44 bit
Hope this helps.
Terry
I never wrote that; I wrote intensity levels. Threshold of hearing is 10^-12 W/m^2, whereas threshold of pain is 10 W/m^2 -- that's a one to 10^13 = ten trillion difference.metalman said:Crowbars confusion comes from the incorrect statement that 130dB equals a range of 10 trillion discrete voltage levels.
Continuing then.
I've sketched in the image below the dynamic range compression that the ear has--the higher the intensity of a signal, the larger the difference has to be with a signal of similar intensity to be detectable. So differences on the order of the threshold of hearing at the bottom may be just around 10^-12 W/m^2, but higher up are much larger to be detectable.
So it would seem you don't need ten trillion-level quantization to fully capture the detail of audible dynamic range. Maybe the 16.7 million levels of 24-bit PCM are sufficient--that is, they might be sufficient if the quantization were nonlinear in the same way as actual hearing. The way it's now, either it can only capture a small portion of the dynamic range, or it is not sufficiently dense at the low end.
I want to bring an analogy from the video world, specifically high dynamic range displays. Regular displays are usually between 300:1 and 600:1, whereas the human eye is about 60 dB (a million to one). Most HDR displays have an LED array behind the LCD screen, so the dynamic range is the LED multiplied by the LCD. Both are usually 8 bit (256) levels. In this case, the nonlinear range happens naturally due to the multiplication. At the bottom you have differences of one, say LED:LCD intensities go as 1x1=1, 1x2=2, 1x3=3, 2x2=4, etc., but near the top differences get very large: 255x254=64770, 255x255=62065. This fits the eye's nonlinearity with lower sensitivity to level differences when intensity is higher. However, with audio the linear dynamic range of PCM DACs is hugely suboptimal.
Even as 32-bit PCM has even more levels, it is still linear and if you try to cover threshold of hearing to threshold of pain (as you should), then you'll still have too granular quantization in the low end. If you have a nonlinear quantization (I'm sure DACs can be built, R2R design would be trivial to modify), then perhaps even 24-bit is sufficient.
I've sketched in the image below the dynamic range compression that the ear has--the higher the intensity of a signal, the larger the difference has to be with a signal of similar intensity to be detectable. So differences on the order of the threshold of hearing at the bottom may be just around 10^-12 W/m^2, but higher up are much larger to be detectable.
So it would seem you don't need ten trillion-level quantization to fully capture the detail of audible dynamic range. Maybe the 16.7 million levels of 24-bit PCM are sufficient--that is, they might be sufficient if the quantization were nonlinear in the same way as actual hearing. The way it's now, either it can only capture a small portion of the dynamic range, or it is not sufficiently dense at the low end.
I want to bring an analogy from the video world, specifically high dynamic range displays. Regular displays are usually between 300:1 and 600:1, whereas the human eye is about 60 dB (a million to one). Most HDR displays have an LED array behind the LCD screen, so the dynamic range is the LED multiplied by the LCD. Both are usually 8 bit (256) levels. In this case, the nonlinear range happens naturally due to the multiplication. At the bottom you have differences of one, say LED:LCD intensities go as 1x1=1, 1x2=2, 1x3=3, 2x2=4, etc., but near the top differences get very large: 255x254=64770, 255x255=62065. This fits the eye's nonlinearity with lower sensitivity to level differences when intensity is higher. However, with audio the linear dynamic range of PCM DACs is hugely suboptimal.
Even as 32-bit PCM has even more levels, it is still linear and if you try to cover threshold of hearing to threshold of pain (as you should), then you'll still have too granular quantization in the low end. If you have a nonlinear quantization (I'm sure DACs can be built, R2R design would be trivial to modify), then perhaps even 24-bit is sufficient.
Forgot the image (I can't edit posts):
An externally hosted image should be here but it was not working when we last tested it.
{kind=link}
Originally posted by Crowbar
Threshold of hearing is 10^-12 W/m^2, whereas threshold of pain is 10 W/m^2 -- that's a one to 10^13 = ten trillion difference.
OK, I see your point, and I agree, 10 Trillion to one difference in W/m^2, which is a 130dB range.
But I think you missed some of what I was saying, which actually supports your view. PCM encoding uses discrete voltage levels that are converted to a wattage output by amplifier and speaker. Using P = V^2/R , roughly 3 million to 1 range of voltage, when squared produces the 10 Trillion to one intensity range you describe. This matches exactly with your description of an exponential relationship, which is already present when taking the square of voltae to produce intensity.
I'm likely not explaining this well, but I think we are two breeds of dog barking at the same cat, if you will.
The grey area is the music listening area which has a dynamic range of 65dB.
Even if this graph is not correct and the area is larger lets say 80dB, 16 bit imho is enough.
Did you ever hear the quantisation noise of the DAC ?
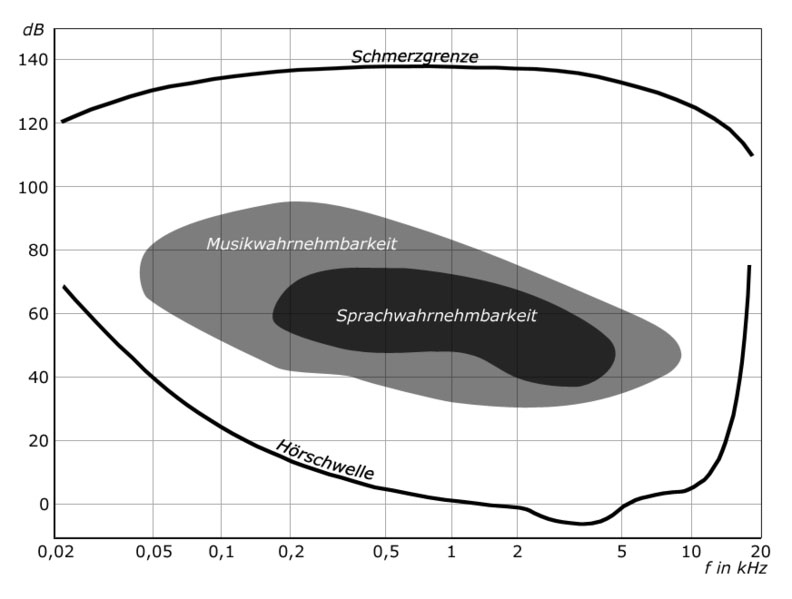
Even if this graph is not correct and the area is larger lets say 80dB, 16 bit imho is enough.
Did you ever hear the quantisation noise of the DAC ?
A speaker implements P = V^2/R? From what I had read, instantaneous delta-pressure is proportional to instantaneous delta-voltage, so wouldn't then intensity be proportional to RMS voltage? If I'm mistaken, I blame it on the painkillers I'm taking for a broken ankle here...
metalman said:You guys have your math mixed up. dB in voltage is the same dB in power, or more accurately, the measure of dB is always a scale relative to power!
...
Terry
You are absolutely right, my failure that I got confused with volts and watts. Each voltage level doubled means 6 dB up and each power level doubled is 3 dB up. 96 dB dynamic range in voltage is 96 dB dynamic range in power indeed. In a 16-bit system with regard to the absolute values, this is 30.5 uV to 2 V range (if we set 0 dB at 2 V), and 10^-12 W/m^2 to 4.3 mW/m^2 (if we set 0 dB at 20 uPa i.e. 10^-12 W/m^2).
My other mistake, I confused electrical power fed in a loudspeaker, and the resulting acoustical power. Correctly: if we feed a loudspeaker of 96 dB/1W/1m sensitivity with 1 W, it will create exactly the above mentioned 4.3 mW/m^2 acoustic power. If this is the full scale output of a 16-bit system, the granularity will be exactly at the hearing threshold, 0 dB SPL.
4.3 mW/m^2 is very quiet, considering threshold of pain is 10 W/m^2. While you don't want to listen to anything that's on average near this loud (hearing loss), the largest transients should be a few W/m^2, not milliwatts. You're loosing out on about 30 dB by using a 16 bit system--actually, more, since 16-bit DACs aren't accurate to the LSB.
Well, if you feed 20 dB more, i.e. 100 W into our hypothetical loudspeaker, it will give 0.43 W/m^2 which is just some 14 dB below the threshold of pain. Of course the quantization noise will be raised 20 dB beyond the hearing threshold, as well, but here the masking effect comes into picture.
There's only masking if you're always playing a mixture of the signals. There can be very quiet passages in music, barely audible, then very loud ones, with even louder transients. If you doubt this, it means you don't listen to much classical music 😛
Higher quantization is also of course needed for DSP.
It would make sense to me that the quantization levels should be matched to the granularity of human hearing along its dynamic range, otherwise you have a system that is suboptimal in one or both of the following: regions where quantization levels are further apart than hearing means suboptimal in terms of sonic performance, and regions where quantization levels are significantly closer than hearing granularity means suboptimal in terms of efficiency--wasting bits. The latter matters when you're doing DSP.
In digital imaging, this is considered explicitly, and thus HDR formats such as LogLuv which compress the dynamic range. I see no reason why in principle it's not useful for audio.
Higher quantization is also of course needed for DSP.
It would make sense to me that the quantization levels should be matched to the granularity of human hearing along its dynamic range, otherwise you have a system that is suboptimal in one or both of the following: regions where quantization levels are further apart than hearing means suboptimal in terms of sonic performance, and regions where quantization levels are significantly closer than hearing granularity means suboptimal in terms of efficiency--wasting bits. The latter matters when you're doing DSP.
In digital imaging, this is considered explicitly, and thus HDR formats such as LogLuv which compress the dynamic range. I see no reason why in principle it's not useful for audio.
more on required dynamic range/digital coding:
http://www.meridian-audio.com/w_paper/Coding2.PDF
120 dB ~ 20 bits linear resoution is usually considered adequate, only required in our hearing peak sensitivity region of 3 KHz +/- ~ an octave
as a practical matter 0 dB threshold requires minutes of silence for the ears to accomodate to and any real musical recording is going to be riding on +20-30 dB room noise
http://headwize.com/articles/hearing_art.htm
gives some spl refernces
electronic technology also limits dynamic range, the current best "24 bit" monolithic DACs just manage 120 + a few dB S/N despite having differential linearity extending below the noise floor
and you might try calculating the S/N at the midpoint (-6 dB) on a 50K or 100K volume pot
http://www.meridian-audio.com/w_paper/Coding2.PDF
120 dB ~ 20 bits linear resoution is usually considered adequate, only required in our hearing peak sensitivity region of 3 KHz +/- ~ an octave
as a practical matter 0 dB threshold requires minutes of silence for the ears to accomodate to and any real musical recording is going to be riding on +20-30 dB room noise
http://headwize.com/articles/hearing_art.htm
gives some spl refernces
electronic technology also limits dynamic range, the current best "24 bit" monolithic DACs just manage 120 + a few dB S/N despite having differential linearity extending below the noise floor
and you might try calculating the S/N at the midpoint (-6 dB) on a 50K or 100K volume pot
If this is how complicated we make it seem, then no wonder the digital designers are having a hard time convincing our analogue ears that they, the designers, are able to reproduce perfect sound (forever).
linear coding is preferred when the information is to be considered "perfectly repesented" (all of the available information is included), or when limitations other than bandwidth and S/N are not well known or agreed on, companding is a lossy process:
http://en.wikipedia.org/wiki/Shannon_hartley
http://en.wikipedia.org/wiki/Companding
communications theory, audio transmission/reproduction theory and practice is much more deeply researched than subjectivivist audiophile caricatures would have you believe – remember that the 1st megacorp (Bell) and the huge entertainment industry have poured billions of $ into it and been at it for most of a century
http://en.wikipedia.org/wiki/Shannon_hartley
http://en.wikipedia.org/wiki/Companding
communications theory, audio transmission/reproduction theory and practice is much more deeply researched than subjectivivist audiophile caricatures would have you believe – remember that the 1st megacorp (Bell) and the huge entertainment industry have poured billions of $ into it and been at it for most of a century
I don't use pots; I use stepped attenuators and bulk metal foil resistors.jcx said:and you might try calculating the S/N at the midpoint (-6 dB) on a 50K or 100K volume pot [/B]
In this context, perfect representation is any that produces the same auditory nerve response that the original signal would have produced. Thus, what I said above about suboptimality remains true; if you use linear coding that's has sufficiently small granularity of quantization at the lowest levels, it's inefficient. No one's preventing anyone from measuring the granularity of human hearing throughout its dynamic range and compand appropriately. Thanks for the citations, but I'm already familiar with these things--I was involved in the development of an early prototype of a high dynamic range display during my university days.jcx said:linear coding is preferred when the information is to be considered "perfectly repesented" (all of the available information is included), or when limitations other than bandwidth and S/N are not well known or agreed on, companding is a lossy process:
Then the issue of perfect representation, that assumes you know the band limit of hearing. Apparently, we don't:
http://jn.physiology.org/cgi/content/full/83/6/3548 "Inaudible High-Frequency Sounds Affect Brain Activity: Hypersonic Effect"
I also remember reading elsewhere that the lowpass filter the ear implements has very short support (in the time domain of course), and ultrasonic bursts can affect the response of auditory cilia to immediately subsequent sonic transients.
I'm sure you enjoy listening to music over the telephone 🙂1st megacorp (Bell) and the huge entertainment industry have poured billions of $ into it and been at it for most of a century
- Status
- Not open for further replies.
- Home
- Source & Line
- Digital Source
- Dynamic range confusion